
قدرت فایل robots.txt رو آزاد کنید: یاد بگیرید چطور از robots.txt برای مسدود کردن URLهای غیرضروری استفاده کنید و استراتژی سئوی سایتتون رو بهبود بدید.
درک نحوه استفاده از فایل robots.txt برای هر استراتژی که برای سئوی سایت انتخاب کنیم، ضروریه. اشتباهات تو این فایل میتونه روی نحوه خزش (کرال یا Crawl) سایت شما و نمایش صفحات تو نتایج جستجو تأثیر بذاره. از طرف دیگه، استفاده درست از این فایل میتونه کارایی خزش رو بهبود بده و مشکلات خزش رو کاهش بده.
گوگل اخیراً به صاحبان سایتها یادآوری کرده که از robots.txt برای مسدود کردن URLهای غیرضروری استفاده کنن. این شامل صفحاتی مثل افزودن به سبد خرید، ورود به سایت یا تسویه حساب میشه. اما سوال اینه که چطور باید درست ازش استفاده کرد؟
تو این مقاله، ما شما رو با تمام جزئیات نحوه انجام این کار راهنمایی میکنیم.
robots.txt چیه؟
فایل robots.txt یه فایل متنی سادست که تو پوشه اصلی سایت شما قرار میگیره و به موتورهای جستجو میگه که کدوم قسمتها رو باید خزش کنن. این فایل بخشی از یه پروتکل به اسم REP هست که کارش اینه که استاندارد کنه چطوری رباتها سایتها رو بگردن، چطوری به محتوا دسترسی پیدا کنن و چطوری اون رو به کاربرا نشون بدن. این پروتکل REP علاوه بر این، درباره استفاده از متا تگ Robots و دستورهای دیگه مثل فالو کردن لینکها هم حرف میزنه.
جدول زیر یه مرجع سریع برای دستورات اصلی robots.txt رو نشون میده:
| دستور | توضیح |
|---|---|
| User-agent | مشخص میکنه که قوانین برای کدوم خزنده اعمال میشه. از * برای هدف قرار دادن همه خزندهها استفاده کنید. |
| Disallow | از خزش URLهای مشخص شده جلوگیری میکنه. |
| Allow | اجازه خزش URLهای خاص رو میده، حتی اگه پوشه بالاتر مسدود شده باشه. |
| Sitemap | مکان نقشه سایت XML شما رو نشون میده و به موتورهای جستجو کمک میکنه اون رو پیدا کنن. |
این یه مثال از robots.txt سایت ikea.com با چندین قانون مختلفه:
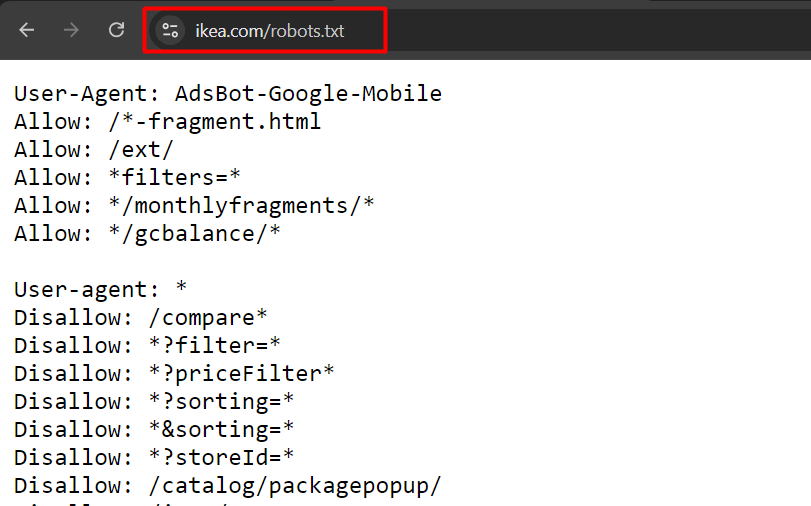
یادتون باشه که robots.txt از عبارات منظم (regular expressions) به طور کامل پشتیبانی نمیکنه و فقط دو نویسه (wildcard) جایگزین داره:
- ستاره (*)، که با 0 یا بیشتر از 0 کاراکتر مطابقت داره.
- علامت دلار ($)، که با انتهای یک URL مطابقت داره.
همچنین توجه داشته باشید که قوانینش به حروف بزرگ و کوچیک حساسن، مثلاً “filter=” با “Filter=” برابر نیست.
مثال هایی از فایل robots.txt
حالا بذار چند تا مثال از فایل robots.txt برات بزنم:
اگه بخوای همه پایشگرها رو از کل سایتت دور نگه داری:
User-agent: *
Disallow: /این دستورها به همه پایشگرهای وب میگه که هیچ صفحهای از www.example.com رو نگردن.
اگه بخوای به همه پایشگرها اجازه بدی کل سایتت رو بگردن:
User-agent: *
Disallow:این دستورها به همه پایشگرهای وب میگه که میتونن همه صفحههای www.example.com رو بگردن.
اگه بخوای فقط یه پایشگر خاص رو از یه پوشه مشخص دور نگه داری:
User-agent: Googlebot
Disallow: /example-subfolder/این دستورها به Googlebot (ربات گوگل) میگه که آدرسهایی که با www.example.com/example-subfolder/ شروع میشن رو نگرده.
اگه بخوای فقط یه پایشگر خاص رو از یه صفحه وب مشخص دور نگه داری:
User-agent: Bingbot
Disallow: /example-subfolder/blocked-page.htmlاین دستورها به Bingbot (ربات بینگ) میگه که فقط آدرس www.example.com/example-subfolder/blocked-page.html رو نگرده.
فایل robots.txt چگونه کار می کند؟
موتورهای جستجو دو تا کار اصلی دارن:
1. گشتن وب برای پیدا کردن محتوای جدید
2. ایندکس کردن محتوا برای کسایی که دنبالش میگردن
موتورهای جستجو برای گشتن سایتها، لینکها رو دنبال میکنن و از یه سایت به سایت دیگه میرن. به این کارشون میگن خزیدن یا Spidering.
وقتی میرسن به یه سایت، قبل از اینکه شروع کنن به گشتن، اول یه نگاهی به فایل robots.txt میندازن. اگه این فایل رو پیدا کنن، میخوننش و بعد میرن سراغ گشتن سایت. فایلهای robots.txt در واقع یه جور دستورالعمل برای پایشگرها هستن که چطوری سایت رو بگردن. اگه فایل robots.txt هیچ دستوری برای محدود کردن پایشگرها نداشته باشه (یا اصلاً همچین فایلی وجود نداشته باشه)، پایشگرها بدون هیچ محدودیتی همه جای سایت رو میگردن و ایندکس میکنن.
چند تا نکته مهم درباره فایل robots.txt:
- فایل robots.txt باید توی پوشه اصلی سایت باشه تا پایشگرها بتونن پیداش کنن.
- اسم فایل robots.txt به بزرگی و کوچیکی حروف حساسه. یعنی باید دقیقاً همینجوری نوشته بشه: robots.txt. (مثلاً Robots.txt یا robots.TXT قبول نیست)
- بعضی از رباتها ممکنه دستورهای فایل robots.txt رو نادیده بگیرن. این مسئله بیشتر درباره پایشگرهای بدجنس مثل رباتهایی که دنبال ایمیل میگردن صدق میکنه.
- فایل robots.txt رو همه میتونن ببینن. پس اطلاعات خصوصیت رو اونجا نذار.
- هر کدوم از ساب دامینهای سایتت باید فایل robots.txt مخصوص خودش رو داشته باشه. مثلاً blog.example.com و example.com هر کدوم باید یه فایل robots.txt جدا داشته باشن.
- اگه میخوای توضیح بدی، میتونی از علامت # در اول خط استفاده کنی.
- حداکثر سایز فایل robots.txt که پشتیبانی میشه، 500 کیلوبایته. پس سعی کن از این بیشتر نشه. میتونی آدرس نقشههای سایتت رو هم آخر دستورهای فایل robots.txt بنویسی.
ترتیب اولویت در robots.txt
موقع تنظیم فایل robots.txt، مهمه که بدونید موتورهای جستجو در صورت وجود قوانین متضاد، به چه ترتیبی تصمیم میگیرن کدوم قوانین رو اعمال کنن.
اونا از این دو قانون کلیدی پیروی میکنن:
1. دقیقترین قانون
قانونی که با کاراکترهای بیشتری در URL مطابقت داره اعمال میشه. مثلاً:
User-agent: *
Disallow: /downloads/
Allow: /downloads/free/تو این مورد، قانون “Allow: /downloads/free/” دقیقتر از “Disallow: /downloads/” هست چون یه زیرپوشه رو هدف قرار میده.
گوگل اجازه خزش زیرپوشه “/downloads/free/” رو میده اما بقیه چیزها زیر “/downloads/” رو مسدود میکنه.
2. کمترین محدودیت
وقتی چند تا قانون به یک اندازه دقیق باشن، مثلاً:
User-agent: *
Disallow: /downloads/
Allow: /downloads/گوگل قانونی رو انتخاب میکنه که کمترین محدودیت رو داره. یعنی گوگل اجازه دسترسی به /downloads/ رو میده.
فایل robots.txt باید کجا باشه؟
موتورهای جستجو و بقیه پایشگرهای وب وقتی میان سراغ یه سایت، میدونن که باید دنبال یه فایل robots.txt بگردن. ولی فقط توی یه جای مشخص (پوشه اصلی سایت) دنبالش میگردن. اگه یه پایشگر توی آدرس www.example.com/robots.txt هیچ فایلی پیدا نکنه، فکر میکنه که این سایت اصلاً فایل robots.txt نداره.
حتی اگه این فایل رو توی جاهای دیگه سایت بذاری، پایشگر نمیفهمه که وجود داره. پس حتماً یادت باشه که توی پوشه اصلی سایتت بذاریش.
چرا robots.txt تو سئو مهمه؟
مسدود کردن صفحات غیرمهم با robots.txt به گوگلبات کمک میکنه بودجه خزشش رو روی قسمتهای ارزشمند سایت و خزش صفحات جدید متمرکز کنه. همچنین به موتورهای جستجو کمک میکنه در مصرف منابع محاسباتی صرفهجویی کنن و به پایداری بهتر کمک کنن.
تصور کنید یه فروشگاه آنلاین با صدها هزار صفحه دارید. بخشهایی از سایت مثل صفحاتی فیلترهایی بر روی اونها اعمال شده ممکنه تعداد نسخههای بینهایتی داشته باشن.
این صفحات ارزش منحصر به فردی ندارن، اساساً محتوای تکراری دارن و ممکنه فضایی برای خزش بینهایت ایجاد کنن و منابع سرور شما و گوگلبات رو هدر بدن.
اینجاست که robots.txt به کار میاد و از خزش این صفحات توسط رباتهای موتور جستجو جلوگیری میکنه.
اگه این کار رو نکنید، ممکنه گوگل سعی کنه تعداد بینهایتی از URLها رو با مقادیر مختلف (حتی غیرموجود) پارامترهای جستجو خزش کنه، که باعث افزایش ناگهانی و هدر رفتن بودجه خزش میشه.
نکتههای سئو درباره فایل robots.txt:
حالا میخوام چند تا نکته بهت بگم که اگه رعایتشون کنی موقع ساخت فایل robots.txt، سئوی سایتت بهتر میشه:
- مطمئن شو که محتواهای اصلی سایتت بلاک نشدن.
- لینکهایی که توی صفحههای بلاک شده توسط فایل robots.txt هستن، دنبال نمیشن. این یعنی اگه اون لینک توی هیچ جای دیگهای از سایتت که بلاک نشده نباشه، موتورهای جستجو نمیبیننش و در نتیجه ایندکسش نمیکنن. یه چیز دیگه هم اینه که اعتبار از صفحه بلاک شده به لینکهاش منتقل نمیشه. اگه صفحههایی داری که میخوای ایندکس نشن ولی اعتبارشون به لینکهاشون منتقل بشه، باید یه راه دیگه پیدا کنی.
- هیچوقت از فایل robots.txt برای مخفی کردن اطلاعات حساس و خصوصی سایتت از نتایج جستجو استفاده نکن. چون ممکنه لینک این جور صفحهها یه جای دیگه توی سایت باشه و کاربرها بتونن بهش دسترسی پیدا کنن. راه بهتر برای جلوگیری از دسترسی به این جور صفحهها، گذاشتن رمز عبوره.
- خیلی از موتورهای جستجو چند تا user agent دارن. مثلاً گوگل از Googlebot برای جستجوی عادی استفاده میکنه. همینطور از Googlebot-Image برای جستجوی عکسهای سایتها استفاده میکنه. معمولاً بیشتر user agentهای یه موتور جستجو، از همون دستورالعمل کلی برای یکی از user agentها استفاده میکنن و لازم نیست برای هر کدوم دستور جداگونه بنویسی. ولی اگه میخوای برای user agentهای مختلف دستورهای متفاوت بنویسی، میتونی راحت این کار رو توی فایل robots.txt انجام بدی.
- موتورهای جستجو محتوای فایل robots.txt رو ذخیره میکنن و معمولاً روزی یه بار بهروزش میکنن. اگه فایل robots.txt رو تغییر دادی، میتونی از طریق ابزار مربوطه توی گوگل سرچ کنسول، سریع بهروزش کنی.
- اینکه جلوی دسترسی به بعضی از آدرسهای سایت رو بگیری، به این معنی نیست که از ایندکس گوگل پاک میشن. یعنی اگه دسترسی به یه صفحهای که قبلاً ایندکس شده رو با فایل robots.txt بلاک کنی، اون صفحه هنوز توی نتایج جستجو دیده میشه. توی این حالت گوگل میگه که همچین صفحهای هست، ولی اطلاعاتش رو نمیتونه ببینه، چون جلوی دسترسی بهش گرفته شده. برای اینکه همچین مشکلی پیش نیاد، اول باید صفحههایی که میخوای رو با استفاده از متا robots نوایندکس کنی و بعد از اینکه از ایندکس گوگل خارج شدن، آدرسهاشون رو بلاک کنی.
- پوشههایی که فایلهای CSS و جاوا اسکریپت مورد نیاز سایتت توشونه رو بلاک نکن. چون گوگل دوست داره سایت رو همونجوری ببینه که کاربرها میبینن. اینجوری گوگل میتونه سایت رو از نظر موبایلفرندلی بودن هم بررسی کنه.
- بهتره یه سری دستور مشترک برای همه user agentها داشته باشی تا موقع بهروزرسانی فایل robots.txt گیج نشی.
چه موقع باید از robots.txt استفاده کرد؟
به عنوان یه قانون کلی، همیشه باید بپرسید چرا صفحات خاصی وجود دارن و آیا چیزی ارزشمندی برای خزش و ایندکس شدن توسط موتورهای جستجو دارن یا نه.
اگه از این اصل پیروی کنیم، مطمئناً همیشه باید این موارد رو مسدود کنیم:
1. URLهایی که شامل پارامترهای پرسوجو هستن مثل:
- جستجوی داخلی سایت.
- URLهای ناوبری فاست (Faceted navigation) که با گزینههای فیلتر یا مرتبسازی ایجاد میشن، اگه بخشی از ساختار URL و استراتژی سئو نیستن.
- URLهای اکشن مثل افزودن به لیست علاقهمندیها یا افزودن به سبد خرید.
2. بخشهای خصوصی سایت، مثل صفحات ورود.
3. فایلهای جاوااسکریپت که برای محتوا یا رندر سایت مهم نیستن، مثل اسکریپتهای ردیابی.
4. مسدود کردن اسکرپرها و چتباتهای هوش مصنوعی برای جلوگیری از استفاده از محتوای شما برای اهداف آموزشی اونا.
بیاید ببینیم چطور میتونید از robots.txt برای هر کدوم از این موارد استفاده کنید.
1. مسدود کردن صفحات جستجوی داخلی
رایجترین و کاملاً ضروریترین کار، مسدود کردن URLهای جستجوی داخلی از خزش توسط گوگل و سایر موتورهای جستجوست، چون تقریباً هر سایتی یه قابلیت جستجوی داخلی داره.
تو سایتهای وردپرسی، معمولاً یه پارامتر “s” هست و URL اینطوری به نظر میاد:
https://www.example.com/?s=googleگری ایلیس از گوگل بارها هشدار داده که URLهای “اکشن” رو مسدود کنید چون ممکنه باعث بشه گوگلبات اونا رو تا حتی URLهای غیرموجود با ترکیبهای مختلف، بینهایت خزش کنه.
این قانونی هست که میتونید تو robots.txt خودتون استفاده کنید تا از خزش این URLها جلوگیری کنید:
User-agent: *
Disallow: *s=*- خط User-agent: * مشخص میکنه که این قانون برای همه خزندههای وب، از جمله گوگلبات، بینگبات و غیره اعمال میشه.
- خط Disallow: *s=* به همه خزندهها میگه که هیچ URLی که شامل پارامتر پرسوجوی “s=” باشه رو خزش نکنن. نویسه جایگزین “*” یعنی میتونه با هر دنبالهای از کاراکترها قبل یا بعد از “s=” مطابقت داشته باشه. اما با URLهایی که “S” بزرگ دارن مثل “/?S=” مطابقت نداره چون به حروف بزرگ و کوچیک حساسه.
این یه مثال از سایتیه که تونست خزش URLهای جستجوی داخلی غیرموجود رو بعد از مسدود کردنشون از طریق robots.txt به شدت کاهش بده.
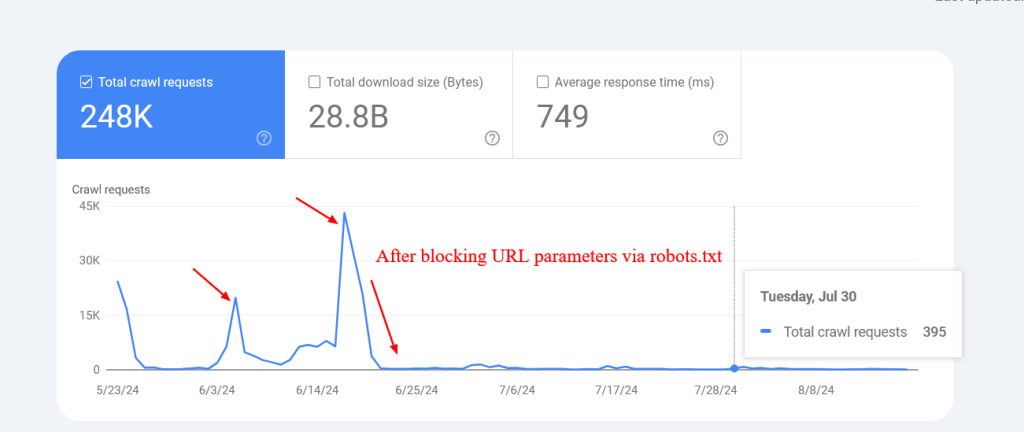
توجه داشته باشید که ممکنه گوگل این صفحات مسدود شده رو ایندکس کنه، اما نگران نباشید چون با گذشت زمان حذف میشن.
2. مسدود کردن URLهای ناوبری فاست
ناوبری فاست (Faceted Navigation) یه بخش جداییناپذیر از هر سایت فروشگاهیه. مواردی هست که ناوبری فاست بخشی از استراتژی سئو هست و هدفش رتبهبندی برای جستجوهای کلی محصولاته.
مثلاً، زالاندو از URLهای ناوبری فاست برای گزینههای رنگ استفاده میکنه تا برای کلمات کلیدی کلی محصول مثل “تیشرت خاکستری” رتبهبندی کنه.
اما تو بیشتر موارد، اینطور نیست و پارامترهای فیلتر صرفاً برای فیلتر کردن محصولات استفاده میشن و دهها صفحه با محتوای تکراری ایجاد میکنن.
از نظر فنی، این پارامترها با پارامترهای جستجوی داخلی تفاوتی ندارن با این تفاوت که ممکنه چندین پارامتر وجود داشته باشه. باید مطمئن بشید که همه اونا رو مسدود میکنید.
مثلاً، اگه فیلترهایی با پارامترهای “sortby”، “color” و “price” دارید، میتونید از این مجموعه قوانین استفاده کنید:
User-agent: *
Disallow: *sortby=*
Disallow: *color=*
Disallow: *price=*بسته به مورد خاص شما، ممکنه پارامترهای بیشتری وجود داشته باشه و نیاز باشه همه اونا رو اضافه کنید.
پارامترهای UTM چی؟
پارامترهای UTM برای اهداف ردیابی استفاده میشن.
همونطور که جان مولر تو پست ردیتش گفته، لازم نیست نگران پارامترهای URLی باشید که به صورت خارجی به صفحات شما لینک میدن.
فقط مطمئن شید که هر پارامتر تصادفی که داخلی استفاده میکنید رو مسدود کنید و از لینک دادن داخلی به این صفحات خودداری کنید، مثلاً لینک دادن از صفحات مقالهتون به صفحه جستجو با یه پرسوجوی جستجو مثل “https://www.example.com/?s=google”.
3. مسدود کردن URLهای PDF
فرض کنید تعداد زیادی سند PDF دارید، مثل راهنمای محصول، بروشور یا مقالات قابل دانلود، و نمیخواید خزش بشن.
اینجا یه قانون ساده robots.txt هست که جلوی دسترسی رباتهای موتور جستجو به این اسناد رو میگیره:
User-agent: *
Disallow: /*.pdf$خط “Disallow: /*.pdf$” به خزندهها میگه که هیچ URLی که با .pdf تموم میشه رو خزش نکنن.
با استفاده از /*، این قانون با هر مسیری تو سایت مطابقت داره. در نتیجه، هر URLی که با .pdf تموم بشه از خزش مسدود میشه.
اگه یه سایت وردپرسی دارید و میخواید PDFها رو از پوشه uploads که از طریق سیستم مدیریت محتوا آپلود میکنید مسدود کنید، میتونید از این قانون استفاده کنید:
User-agent: *
Disallow: /wp-content/uploads/*.pdf$
Allow: /wp-content/uploads/2024/09/allowed-document.pdf$میبینید که اینجا قوانین متناقضی داریم.
در صورت وجود قوانین متناقض، قانون دقیقتر اولویت داره، که یعنی خط آخر اطمینان میده که فقط فایل خاصی که تو پوشه “wp-content/uploads/2024/09/allowed-document.pdf” قرار داره اجازه خزش داره.
4. مسدود کردن یک پوشه
فرض کنید یه API endpoint دارید که دادههای فرم رو بهش ارسال میکنید. احتمالاً فرم شما یه ویژگی action داره مثل action=”/form/submissions/”.
مشکل اینه که گوگل سعی میکنه این URL یعنی /form/submissions/ رو خزش کنه، که احتمالاً نمیخواید. میتونید با این قانون، این URLها رو از خزش مسدود کنید:
User-agent: *
Disallow: /form/با مشخص کردن یه پوشه تو قانون Disallow، به خزندهها میگید که از خزش همه صفحات زیر اون پوشه خودداری کنن، و دیگه نیازی به استفاده از نویسه جایگزین (*) مثل “/form/*” ندارید.
توجه کنید که همیشه باید مسیرهای نسبی رو مشخص کنید و هرگز از URLهای مطلق مثل “https://www.example.com/form/” برای دستورات Disallow و Allow استفاده نکنید.
مراقب باشید از قوانین نادرست استفاده نکنید. مثلاً، استفاده از /form بدون اسلش انتهایی با یه صفحه /form-design-examples/ هم مطابقت داره، که ممکنه یه صفحه تو وبلاگ شما باشه که میخواید ایندکس بشه.
5. مسدود کردن URLهای حساب کاربری
اگه یه سایت فروشگاهی دارید، احتمالاً پوشههایی دارید که با “/myaccount/” شروع میشن، مثل “/myaccount/orders/” یا “/myaccount/profile/”.
با توجه به اینکه صفحه اصلی “/myaccount/” یه صفحه ورود به سیستمه که میخواید ایندکس بشه و کاربرها تو جستجو پیداش کنن، ممکنه بخواید زیرصفحههاش رو از خزش توسط گوگلبات مسدود کنید.
میتونید از قانون Disallow در ترکیب با قانون Allow استفاده کنید تا همه چیز زیر پوشه “/myaccount/” رو مسدود کنید (به جز خود صفحه /myaccount/).
User-agent: *
Disallow: /myaccount/
Allow: /myaccount/$و باز هم، از اونجایی که گوگل از دقیقترین قانون استفاده میکنه، همه چیز زیر پوشه /myaccount/ رو مسدود میکنه اما فقط به خود صفحه /myaccount/ اجازه خزش میده.
اینم یه مورد دیگه از ترکیب قوانین Disallow و Allow: اگه جستجوی شما زیر پوشه /search/ قرار داره و میخواید پیدا و ایندکس بشه اما URLهای جستجوی واقعی رو مسدود کنید:
User-agent: *
Disallow: /search/
Allow: /search/$6. مسدود کردن فایلهای جاوااسکریپت غیرمرتبط با رندر
هر سایتی از جاوااسکریپت استفاده میکنه، و خیلی از این اسکریپتها به رندر محتوا مربوط نیستن، مثل اسکریپتهای ردیابی یا اونایی که برای بارگذاری AdSense استفاده میشن.
گوگلبات میتونه بدون این اسکریپتها محتوای سایت رو خزش و رندر کنه. بنابراین، مسدود کردنشون امنه و توصیه میشه، چون درخواستها و منابع لازم برای دریافت و تجزیه اونا رو ذخیره میکنه.
در زیر یه نمونه خط هست که یه جاوااسکریپت نمونه رو که حاوی پیکسلهای ردیابیه مسدود میکنه.
User-agent: *
Disallow: /assets/js/pixels.js7. مسدود کردن چتباتهای هوش مصنوعی و اسکرپرها
خیلی از ناشران نگرانن که محتواشون به طور ناعادلانه و بدون رضایتشون برای آموزش مدلهای هوش مصنوعی استفاده میشه، و میخوان جلوی این کار رو بگیرن.
#ai chatbots
User-agent: GPTBot
User-agent: ChatGPT-User
User-agent: Claude-Web
User-agent: ClaudeBot
User-agent: anthropic-ai
User-agent: cohere-ai
User-agent: Bytespider
User-agent: Google-Extended
User-Agent: PerplexityBot
User-agent: Applebot-Extended
User-agent: Diffbot
User-agent: PerplexityBot
Disallow: /#scrapers
User-agent: Scrapy
User-agent: magpie-crawler
User-agent: CCBot
User-Agent: omgili
User-Agent: omgilibot
User-agent: Node/simplecrawler
Disallow: /اینجا، هر user agent به طور جداگانه لیست شده، و قانون Disallow: / به اون رباتها میگه که هیچ بخشی از سایت رو خزش نکنن.
این کار، علاوه بر جلوگیری از آموزش هوش مصنوعی روی محتوای شما، میتونه به کاهش بار روی سرورتون با کم کردن خزش غیرضروری کمک کنه.
برای ایده گرفتن در مورد اینکه کدوم رباتها رو مسدود کنید، میتونید فایلهای لاگ سرورتون رو چک کنید تا ببینید کدوم خزندهها سرورهاتون رو خسته میکنن، و یادتون باشه، robots.txt از دسترسی غیرمجاز جلوگیری نمیکنه.
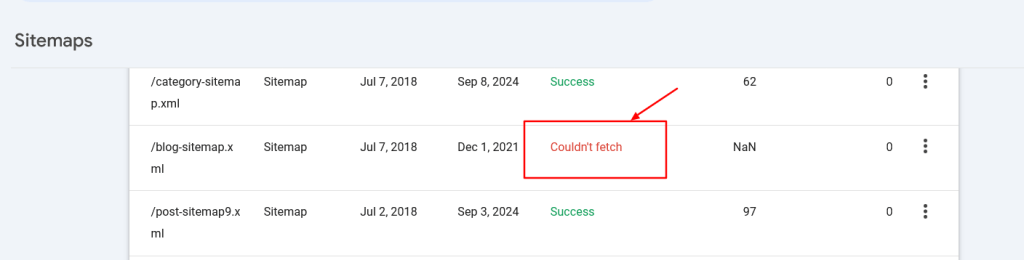
8. مشخص کردن URLهای نقشه سایت
قرار دادن URL نقشه سایت تو فایل robots.txt به موتورهای جستجو کمک میکنه به راحتی همه صفحات مهم سایت شما رو کشف کنن. این کار با اضافه کردن یه خط خاص که به مکان نقشه سایت شما اشاره میکنه انجام میشه، و میتونید چندین نقشه سایت رو مشخص کنید، هر کدوم تو یه خط جداگانه.
Sitemap: https://www.example.com/sitemap/articles.xml
Sitemap: https://www.example.com/sitemap/news.xml
Sitemap: https://www.example.com/sitemap/video.xmlبرخلاف قوانین Allow یا Disallow که فقط مسیر نسبی رو اجازه میدن، دستور Sitemap نیاز به یه URL کامل و مطلق داره تا مکان نقشه سایت رو نشون بده.
مطمئن شید که URLهای نقشه سایت برای موتورهای جستجو قابل دسترسی هستن و ساختار درستی دارن تا از خطاها جلوگیری بشه.
9. چه موقع از Crawl-Delay استفاده کنیم
دستور crawl-delay تو robots.txt تعداد ثانیههایی رو مشخص میکنه که یه ربات باید قبل از خزش صفحه بعدی صبر کنه. اگرچه گوگلبات این دستور رو نمیشناسه، اما رباتهای دیگه ممکنه بهش احترام بذارن.
این کار با کنترل اینکه رباتها چقدر مکرر سایت شما رو خزش میکنن، به جلوگیری از بار اضافی سرور کمک میکنه.
مثلاً، اگه میخواید ClaudeBot محتوای شما رو برای آموزش هوش مصنوعی خزش کنه اما میخواید از بار اضافی سرور جلوگیری کنید، میتونید یه تأخیر خزش تعیین کنید تا فاصله بین درخواستها رو مدیریت کنید.
User-agent: ClaudeBot
Crawl-delay: 60این به user agent ClaudeBot دستور میده که بین درخواستها موقع خزش سایت 60 ثانیه صبر کنه.
البته، ممکنه رباتهای هوش مصنوعی ای باشن که به دستورات تأخیر خزش احترام نذارن. در این صورت، ممکنه نیاز باشه از یه فایروال وب برای محدود کردن سرعتشون استفاده کنید.
عیبیابی robots.txt
وقتی robots.txt خودتون رو نوشتید، میتونید از این ابزارها استفاده کنید تا چک کنید آیا ساختارش درسته یا اینکه اتفاقی یه URL مهم رو مسدود نکردید.
1. اعتبارسنج robots.txt کنسول جستجوی گوگل
وقتی robots.txt رو بهروزرسانی کردید، باید چک کنید که آیا خطایی داره یا به طور تصادفی URLهایی رو که میخواید خزش بشن مثل منابع، تصاویر یا بخشهای سایت رو مسدود نکرده باشه.
برید به تنظیمات > robots.txt، و اونجا اعتبارسنج داخلی robots.txt رو پیدا میکنید. زیر ویدیویی هست که نشون میده چطور robots.txt رو دریافت و اعتبارسنجی کنید.
2. تجزیهکننده robots.txt گوگل
این تجزیهکننده (Parser)، تجزیهکننده رسمی robots.txt گوگله که تو کنسول جستجو استفاده میشه.
برای نصب و اجرا روی کامپیوتر محلیتون به مهارتهای پیشرفته نیاز داره. اما شدیداً توصیه میشه وقت بذارید و طبق دستورالعملهای اون صفحه انجامش بدید، چون میتونید تغییرات تو فایل robots.txt رو قبل از آپلود به سرورتون مطابق با تجزیهکننده رسمی گوگل اعتبارسنجی کنید.
مدیریت متمرکز robots.txt
هر دامنه و زیردامنه باید robots.txt خودش رو داشته باشه، چون گوگلبات robots.txt دامنه اصلی رو برای یه زیردامنه تشخیص نمیده.
این وقتی یه سایت با دهها زیردامنه دارید چالشهایی ایجاد میکنه، چون یعنی باید یه عالمه فایل robots.txt رو جداگانه نگهداری کنید.
با این حال، میشه یه فایل robots.txt رو روی یه زیردامنه میزبانی کرد، مثلاً https://cdn.example.com/robots.txt، و یه ریدایرکت از https://www.example.com/robots.txt به اون تنظیم کرد.
میتونید برعکسش رو هم انجام بدید و فقط زیر دامنه اصلی میزبانیش کنید و از زیردامنهها به دامنه اصلی ریدایرکت کنید.
موتورهای جستجو با فایل ریدایرکت شده طوری رفتار میکنن که انگار روی دامنه اصلی قرار داره. این روش اجازه میده قوانین robots.txt رو هم برای دامنه اصلی و هم برای زیردامنههاتون به صورت متمرکز مدیریت کنید.
این کار بهروزرسانیها و نگهداری رو کارآمدتر میکنه. در غیر این صورت، نیاز داشتید برای هر زیردامنه از یه فایل robots.txt جداگانه استفاده کنید.
Robots.txt و وردپرس
هر چیزی که تا الان درباره فایل robots.txt یاد گرفتی، توی سایتهای وردپرسی هم میشه انجام داد. قبلاً پیشنهاد میشد که مسیرهای wp-admin و wp-includes رو توی فایل robots.txt بلاک کنیم. ولی از سال 2012 به بعد دیگه لازم نیست این کار رو بکنی، چون وردپرس خودش با کد @header( ‘X-Robots-Tag: noindex’ ); صفحههای موجود توی این آدرسها رو نوایندکس میکنه.
وردپرس به طور پیشفرض یه فایل فیزیکی برای robots.txt نداره، ولی اگه آدرس https://www.yourdomain.com/robots.txt رو توی مرورگرت بزنی، یه صفحه متنی با این محتوا میبینی:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpاگه توی تنظیمات وردپرس تیک “عدم نمایش سایت برای موتورهای جستجو” رو بزنی، محتوای robots.txt به این شکل تغییر میکنه:
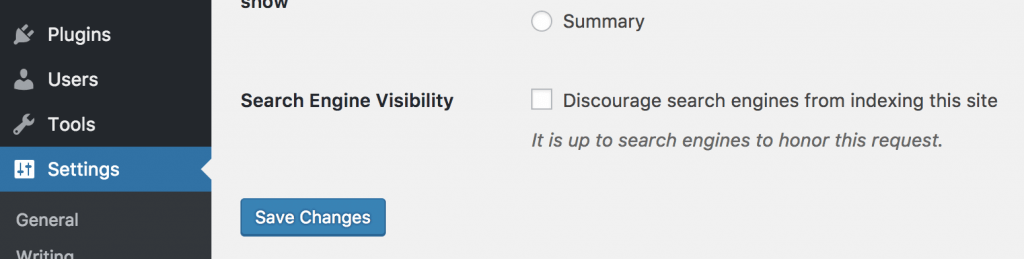
User-agent: *
Disallow: /این دستورها جلوی دسترسی به کل سایت رو برای موتورهای جستجو میگیره.
برای ویرایش robots.txt توی وردپرس باید یه فایل متنی با همین اسم رو توی پوشه اصلی آپلود کنی. وقتی این کار رو بکنی، دیگه فایل robots.txt مجازی وردپرس دیده نمیشه.
مقایسه robots.txt، متا robots و x-robots:
بین اینها یه سری تفاوت هست. robots.txt یه فایل واقعیه، ولی robots و x-robots جزو دادههای متا هستن. کارشون هم با هم فرق داره. فایل robots.txt کنترل میکنه که صفحههای سایت چطوری گشت
نتیجهگیری
یه فایل robots.txt بهینهسازی شده درست برای مدیریت بودجه خزش یه سایت ضروریه. این اطمینان میده که موتورهای جستجو مثل گوگلبات وقتشون رو روی صفحات ارزشمند میذارن به جای اینکه منابع رو روی صفحات غیرضروری هدر بدن.
از طرف دیگه، مسدود کردن رباتهای هوش مصنوعی و اسکرپرها با استفاده از robots.txt میتونه به طور قابل توجهی بار سرور رو کاهش بده و منابع محاسباتی رو ذخیره کنه.
مطمئن شید همیشه تغییراتتون رو اعتبارسنجی میکنید تا از مشکلات غیرمنتظره قابلیت خزش جلوگیری کنید.
اما یادتون باشه که اگرچه مسدود کردن منابع غیرمهم از طریق robots.txt ممکنه به افزایش کارایی خزش کمک کنه، عوامل اصلی که روی بودجه خزش تأثیر میذارن محتوای با کیفیت بالا و سرعت بارگذاری صفحه هستن.
سلام
بخاطر اینکه سرعت وب سایت من پایین نیاد میخواهم فقط برای گوگل و بینگ یاهو سایتم را قابل دسترس کنم باید دستور را چه قرار دهم
سایت من وردپرس است
User-agent: آیا باید نام همه آنها را اینجا قرار دهم ؟
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
کافیست user-agent: * را در فایل robots.txt قرار دهید. دستورات برای همه بات های فوق اعمال می شود. اما اگر منظور سایر بات هاست، احتمالا به دستورات فایل robots.txt توجهی نخواهند کرد.