
گوگل مام (MUM) چیه؟
سرنخهایی از ماهیت گوگل مام (MUM) رو میشه تو مقالههای تحقیقاتی جدیدی که محققان گوگل در زمینه هوش ماشینی منتشر کردن، پیدا کرد.
مدل یکپارچه چند وظیفهای گوگل یا همون مام (Google Multitask Unified Model – MUM)، یه فناوری جدیده برای جواب دادن به سؤالهای پیچیدهای که جواب سرراستی ندارن. گوگل مقالههای تحقیقاتیای منتشر کرده که ممکنه بهمون سرنخهایی بده از اینکه هوش مصنوعی MUM چیه و چطور کار میکنه.
به احتمال زیاد، MUM از چند تا نوآوری مختلف تشکیل شده. مثلاً، مقاله تحقیقاتی گوگل با عنوان «ترنسفورمرهای هایپرگرید: به سوی یک مدل واحد برای چند وظیفه» (HyperGrid Transformers: Towards A Single Model for Multiple Tasks)، یه دستاورد جدید و پیشرفته در زمینه یادگیری چند وظیفهای رو توصیف میکنه که میتونه بخشی از MUM باشه.
با اینکه این مقاله روی دو تا مقاله خاص که خیلی جالبن تمرکز کرده، اما این به اون معنی نیست که فقط همین دو تا فناوری زیربنای مدل یکپارچه چند وظیفهای گوگل (MUM) هستن.
الگوریتمهای گوگل که در مقالات تحقیقاتی و پتنتها توصیف شدن
گوگل معمولاً تأیید نمیکنه که الگوریتمهایی که تو مقالهها یا پتنتها توضیح داده میشن، واقعاً در حال استفاده هستن یا نه.
گوگل هنوز تأیید نکرده که فناوری مدل یکپارچه چند وظیفهای (MUM) دقیقاً چیه.
مقالات تحقیقاتی درباره مدل یکپارچه چند وظیفهای
گاهی وقتا، مثل اتفاقی که برای تطبیق عصبی (Neural Matching) افتاد، هیچ مقاله یا پتنتی وجود نداره که دقیقاً از اسم اون فناوری استفاده کرده باشه. انگار گوگل یه اسم برند توصیفی برای گروهی از الگوریتمها که با هم کار میکنن، اختراع کرده.
این قضیه تا حدودی برای مدل یکپارچه چند وظیفهای (MUM) هم صادقه. هیچ پتنت یا مقاله تحقیقاتیای با برند MUM وجود نداره. اما…
مقالات تحقیقاتیای *وجود دارن* که درباره مشکلات مشابهی که MUM حل میکنه، با استفاده از راهحلهای چند وظیفهای و مدل یکپارچه بحث میکنن.
گوگل مام (MUM) چیه؟
گوگل MUM مجموعهای از فناوریهاست که با هم کار میکنن تا کوئریهای جستجوی سختی رو که نمیشه با یه اسنیپت کوتاه یا ده لینک آبی سنتی بهشون جواب داد، حل کنن.
هدف MUM اینه که با استفاده از انواع مختلف محتوا، از جمله تصاویر و محتوای متنی به زبانهای مختلف، این کوئریهای سخت رو حل کنه تا یه جواب غنی و دقیق ارائه بده.
پیشزمینه مشکلی که MUM حل میکنه
پاسخ به سؤالات طولانی (Long Form Question Answering) یه نوع کوئری جستجوی پیچیدهست که نمیشه با یه لینک یا اسنیپت بهش جواب داد. جوابش به پاراگرافهایی از اطلاعات نیاز داره که شامل چند تا موضوع فرعی هستن.
گوگل تو معرفی MUM، پیچیدگی بعضی سؤالها رو با یه مثال توضیح داد؛ مثلاً کاربری میخواد بدونه چطور برای کوهنوردی در کوه فوجی تو فصل پاییز آماده بشه.
این مثال گوگل از یه کوئری جستجوی پیچیدهست:
«امروز گوگل میتونه تو این زمینه به شما کمک کنه، اما به جستجوهای زیاد و حسابشدهای نیاز داره. شما باید ارتفاع هر کوه، میانگین دمای هوا تو پاییز، سختی مسیرهای کوهنوردی، تجهیزات مناسب و چیزای دیگه رو جدا جدا جستجو کنید.»
این هم یه مثال از یه سؤال طولانی:
«تفاوت بین پهنههای آبی مثل دریاچهها، رودخونهها و اقیانوسها چیه؟»
سؤال بالا به چند پاراگراف نیاز داره تا ویژگیهای دریاچهها، رودخونهها و دریاها رو توضیح بده و بعد هر کدوم از این پهنههای آبی رو با هم مقایسه کنه.
این هم یه مثال از پیچیدگی جواب:
- معمولاً به دریاچه آب راکد میگن چون جریانی نداره.
- رودخونه در حال جریانه.
- هم دریاچه و هم رودخونه معمولاً آب شیرین دارن.
- اما گاهی وقتا یه رودخونه یا دریاچه میتونه آب لبشور (کمی شور) داشته باشه.
- عمق یه اقیانوس میتونه به چندین کیلومتر برسه.
جواب دادن به یه سؤال طولانی، به یه جواب پیچیده نیاز داره که از چند مرحله تشکیل شده، مثل مثالی که گوگل درباره آمادگی برای کوهنوردی در کوه فوجی تو پاییز زد.
گوگل تو معرفی MUM به «پاسخ به سؤالات طولانی» اشارهای نکرد، اما مشکلی که MUM حل میکنه دقیقاً همین به نظر میرسه.
تغییر در نحوه پاسخگویی به سؤالات
در ماه می ۲۰۲۱، یه محقق گوگل به اسم دونالد متزلر (Donald Metzler) مقالهای منتشر کرد که نشون میداد روشی که موتورهای جستجو به سؤالات جواب میدن، برای پاسخ به سؤالهای پیچیده باید مسیر جدیدی رو در پیش بگیره.
این مقاله میگفت که روش فعلی بازیابی اطلاعات که شامل ایندکس کردن صفحات وب و رتبهبندی اونهاست، برای جواب دادن به کوئریهای جستجوی پیچیده کافی نیست.
عنوان مقاله اینه: بازنگری در جستجو: تبدیل آماتورها به متخصصان (Rethinking Search: Making Experts out of Dilettantes) (PDF)
واژه Dilettante به کسی گفته میشه که دانش سطحی درباره یه موضوعی داره، مثل یه آدم آماتور و غیرمتخصص.
این مقاله وضعیت امروز موتورهای جستجو رو اینطوری توصیف میکنه:
«سیستمهای پیشرفته امروزی اغلب به ترکیبی از بازیابی مبتنی بر کلمه… و معنایی… برای تولید مجموعهای اولیه از کاندیداها متکی هستن.
این مجموعه از کاندیداها بعداً به یک یا چند مرحله از مدلهای بازرتبهبندی (re-ranking) منتقل میشن که به احتمال زیاد مدلهای یادگیری برای رتبهبندی مبتنی بر شبکههای عصبی هستن.
همونطور که قبلاً گفته شد، پارادایم «ایندکس کن – بازیابی کن – بعد رتبه بده» آزمون زمان رو پس داده و جای تعجب نداره که رویکردهای پیشرفته یادگیری ماشین و پردازش زبان طبیعی (NLP) بخش جداییناپذیر مؤلفههای ایندکس، بازیابی و رتبهبندی سیستمهای امروزی هستن.»
بازیابی اطلاعات مبتنی بر مدل (Model-based Information Retrieval)
سیستم جدیدی که مقاله «تبدیل آماتورها به متخصصان» توصیف میکنه، سیستمیه که بخش «ایندکس کن – بازیابی کن – رتبه بده» الگوریتم رو حذف میکنه.
این بخش از مقاله به IR اشاره میکنه که مخفف Information Retrieval (بازیابی اطلاعات) هست، یعنی همون کاری که موتورهای جستجو انجام میدن.
مقاله این مسیر جدید برای موتورهای جستجو رو اینطوری توصیف میکنه:
«این رویکرد که بهش بازیابی اطلاعات مبتنی بر مدل گفته میشه، قراره جایگزین پارادایم قدیمی «بازیابی کن – بعد رتبه بده» بشه. این کار با ادغام مؤلفههای ایندکس، بازیابی و رتبهبندی سیستمهای سنتی IR در یک مدل یکپارچه واحد انجام میشه.»
بعد، مقاله با جزئیات توضیح میده که این «مدل یکپارچه» چطور کار میکنه.
اجازه بدید همینجا یه مکثی بکنیم و یادآوری کنیم که اسم الگوریتم جدید گوگل، مدل *یکپارچه* چند وظیفهای (Multitask *Unified Model*) هست.
من فعلاً از توضیحات «مدل یکپارچه» میگذرم و فقط به این نکته اشاره میکنم:
«تفاوت مهم بین سیستمهای امروزی و سیستم آیندهنگرانهای که تصور میشه، اینه که یه مدل یکپارچه جایگزین مؤلفههای ایندکس، بازیابی و رتبهبندی میشه. در واقع، بهش مبتنی بر مدل گفته میشه چون چیزی جز یک مدل وجود نداره.»
اسکرینشاتی که نشون میده مدل یکپارچه چیه
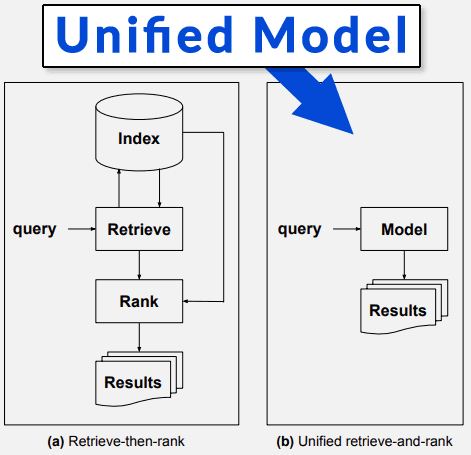
در جای دیگهای از مقاله Dilettantes اومده:
«برای رسیدن به این هدف، یک چارچوب بازیابی اطلاعات به اصطلاح مبتنی بر مدل پیشنهاد شده که از پارادایم سنتی «ایندکس کن – بازیابی کن – بعد رتبه بده» فاصله میگیره. این کار با کدگذاری دانش موجود در یک مجموعه داده (corpus) در یک مدل یکپارچه انجام میشه که جایگزین مؤلفههای ایندکس، بازیابی و رتبهبندی سیستمهای سنتی میشه.»
آیا این تصادفیه که فناوری گوگل برای پاسخ به سؤالات پیچیده، مدل یکپارچه چند وظیفهای نامیده میشه و سیستمی که تو این مقاله ماه می ۲۰۲۱ بحث شده، بر نیاز به یک «مدل یکپارچه» برای پاسخ به سؤالات پیچیده تأکید میکنه؟
مقاله تحقیقاتی MUM چیه؟
مقاله تحقیقاتی «بازنگری در جستجو: تبدیل آماتورها به متخصصان» اسم دونالد متزلر رو به عنوان یکی از نویسندهها لیست کرده. این مقاله نیاز به الگوریتمی رو اعلام میکنه که وظیفه پاسخ به سؤالات پیچیده رو انجام بده و یه مدل یکپارچه برای این کار پیشنهاد میکنه.
یه نمای کلی از فرآیند ارائه میده، اما جزئیات و آزمایشهای کمی داره.
یه مقاله تحقیقاتی دیگه هم هست که در دسامبر ۲۰۲۰ منتشر شده و الگوریتمی رو توصیف میکنه که آزمایشها و جزئیات داره و یکی از نویسندههاش… دونالد متزلره.
اسم این مقاله تحقیقاتی دسامبر ۲۰۲۰ اینه: ترکیب چند وظیفهای متخصصان متوالی برای جریانهای فعالیت کاربر (Multitask Mixture of Sequential Experts for User Activity Streams)
بیایید همینجا وایسیم، برگردیم عقب و اسم الگوریتم جدید گوگل رو تکرار کنیم: مدل یکپارچه چند وظیفهای.
مقاله می ۲۰۲۱ «بازنگری در جستجو: تبدیل آماتورها به متخصصان» نیاز به یک مدل یکپارچه رو مشخص کرد. مقاله تحقیقاتی قبلی از دسامبر ۲۰۲۰ (از همون نویسنده) اسمش هست: ترکیب چند وظیفهای… (Multitask Mixture of Sequential Experts for User Activity Streams) (PDF).
اینها تصادفیان؟ شاید نه. شباهتهای بین MUM و این مقاله تحقیقاتی دیگه به طرز عجیبی زیاده.
MoSE: ترکیب چند وظیفهای متخصصان متوالی برای جریانهای فعالیت کاربر
خلاصه کلام
MoSE یه فناوری هوش ماشینیه که از چندین منبع داده (لاگهای جستجو و مرور) یاد میگیره تا الگوهای جستجوی پیچیده و چند مرحلهای رو پیشبینی کنه. این فناوری خیلی کارآمده که باعث میشه مقیاسپذیر و قدرتمند باشه.
این ویژگیهای MoSE با ویژگیهای خاصی از الگوریتم MUM مطابقت داره، مخصوصاً اینکه MUM میتونه به کوئریهای جستجوی پیچیده جواب بده و ۱۰۰۰ برابر قدرتمندتر از فناوریهایی مثل BERT هست.
MoSE چیکار میکنه؟
خلاصه کلام
MoSE از ترتیب متوالی کلیکها و دادههای مرور کاربر یاد میگیره. این اطلاعات بهش اجازه میده فرآیند کوئریهای جستجوی پیچیده رو مدلسازی کنه تا جوابهای رضایتبخشی تولید کنه.
مقاله تحقیقاتی MoSE در دسامبر ۲۰۲۰ از گوگل، مدلسازی رفتار کاربر به ترتیب متوالی رو توصیف میکنه، برخلاف مدلسازی بر اساس کوئری جستجو و محتواش.
مدلسازی رفتار کاربر به ترتیب متوالی مثل اینه که بررسی کنیم یه کاربر اول دنبال چی گشته، بعد چی، و بعدش چی، تا بفهمیم چطور باید به یه کوئری پیچیده جواب بدیم.
مقاله این موضوع رو اینطوری توصیف میکنه:
«در این کار، ما مشکل چالشبرانگیز نحوه مدلسازی رفتار متوالی کاربر در تنظیمات یادگیری چند وظیفهای عصبی رو مطالعه میکنیم.
مهمترین دستاورد ما یک چارچوب جدیده به اسم ترکیب متخصصان متوالی (MoSE). این چارچوب به صراحت رفتار متوالی کاربر رو با استفاده از حافظه طولانی کوتاهمدت (LSTM) در چارچوب مدلسازی چند وظیفهای پیشرفته «ترکیب متخصصان چند دریچهای» مدلسازی میکنه.»
اون قسمت آخر درباره «چارچوب مدلسازی چند وظیفهای ترکیب متخصصان چند دریچهای» یه کم سنگینه!
این یه اشاره به نوعی از الگوریتمه که برای چند وظیفه/هدف بهینهسازی شده و فعلاً همین قدر که بدونیم کافیه. (منبع: مدلسازی روابط وظایف در یادگیری چند وظیفهای با ترکیب متخصصان چند دریچهای)
مقاله MoSE درباره الگوریتمهای چند وظیفهای مشابه دیگهای هم صحبت میکنه که برای چند هدف بهینهسازی شدن، مثل اینکه همزمان پیشبینی کنن یه کاربر ممکنه چه ویدیویی رو تو یوتیوب بخواد ببینه، کدوم ویدیوها تعامل بیشتری ایجاد میکنن و کدوم ویدیوها رضایت کاربر بیشتری به همراه دارن. این یعنی سه تا وظیفه/هدف.
مقاله میگه:
«یادگیری چند وظیفهای به خصوص وقتی که وظایف ارتباط نزدیکی با هم دارن، مؤثره.»
MoSE روی جستجو آموزش دیده
الگوریتم MoSE روی یادگیری از چیزی که بهش دادههای ناهمگون (heterogeneous data) میگه تمرکز داره، یعنی انواع مختلف و متنوع داده.
چیزی که برای ما در زمینه MUM جالبه اینه که الگوریتم MoSE در زمینه جستجو و تعاملات جستجوگرها برای پیدا کردن جواب، یعنی مراحلی که یه جستجوگر برای پیدا کردن جواب طی کرده، مورد بحث قرار گرفته.
«…در این کار، ما روی مدلسازی جریانهای فعالیت کاربر از منابع داده ناهمگون (مثلاً لاگهای جستجو و لاگهای مرور) و تعاملات بین اونها تمرکز میکنیم.»
محققان الگوریتم MoSE رو روی وظایف جستجو در G Suite و Gmail آزمایش و تست کردن.
MoSE و پیشبینی رفتار جستجو
یه ویژگی دیگه که MoSE رو به یه کاندیدای جالب برای MUM تبدیل میکنه اینه که میتونه یه سری از جستجوها و رفتارهای متوالی رو پیشبینی کنه.
کوئریهای جستجوی پیچیده، همونطور که تو معرفی MUM گوگل اشاره شد، میتونن تا هشت جستجوی مختلف نیاز داشته باشن.
اما اگه یه الگوریتم بتونه این جستجوها رو پیشبینی کنه و اونها رو تو جوابهاش لحاظ کنه، میتونه بهتر به این سؤالهای پیچیده جواب بده.
تو معرفی MUM اومده:
«اما با یه فناوری جدید به اسم مدل یکپارچه چند وظیفهای یا MUM، داریم به کمک به شما برای این نوع نیازهای پیچیده نزدیکتر میشیم. پس در آینده، برای انجام کارهاتون به جستجوهای کمتری نیاز خواهید داشت.»
و این هم چیزیه که مقاله تحقیقاتی MoSE میگه:
«مثلاً، جریانهای رفتار کاربر، مثل لاگهای جستجوی کاربر در سیستمهای جستجو، به طور طبیعی یه دنباله زمانی هستن. مدلسازی رفتارهای متوالی کاربر به عنوان نمایشهای متوالی صریح، میتونه به مدل چند وظیفهای قدرت بده تا وابستگیهای زمانی رو در نظر بگیره و در نتیجه رفتار آینده کاربر رو با دقت بیشتری پیشبینی کنه.»
MoSE در مصرف منابع بسیار بهینهست
بهینه بودن MoSE خیلی مهمه.
هرچقدر یه الگوریتم برای انجام یه کار به منابع محاسباتی کمتری نیاز داشته باشه، میتونه تو اون کارها قدرتمندتر باشه، چون این بهش فضای بیشتری برای مقیاسپذیری میده.
گفته شده که MUM هزار برابر قدرتمندتر از BERT هست.
مقاله تحقیقاتی MoSE به ایجاد تعادل بین کیفیت جستجو و «هزینههای منابع» اشاره میکنه که منظور از هزینههای منابع، منابع محاسباتیه.
حالت ایدهآل اینه که با کمترین هزینه منابع محاسباتی، نتایج باکیفیتی داشته باشیم که به الگوریتم اجازه بده برای کارهای بزرگتری مثل جستجو مقیاسپذیر بشه.
الگوریتم پنگوئن اولیه فقط میتونست سالی چند بار روی کل نقشه وب (که بهش گراف لینک میگن) اجرا بشه. احتمالاً به این دلیل که منابع زیادی مصرف میکرد و نمیشد روزانه اجراش کرد.
در سال ۲۰۱۶، پنگوئن قدرتمندتر شد چون دیگه میتونست به صورت ریلتایم اجرا بشه. این یه مثاله که نشون میده چرا تولید نتایج باکیفیت با حداقل هزینههای منابع مهمه.
هرچی MoSE به هزینههای منابع کمتری نیاز داشته باشه، میتونه قدرتمندتر و مقیاسپذیرتر باشه.
این چیزیه که محققان درباره هزینههای منابع MoSE گفتن:
«در آزمایشها، ما کارایی معماری MoSE رو در مقایسه با هفت معماری جایگزین، هم روی دادههای مصنوعی و هم روی دادههای نویزی دنیای واقعی کاربر در G Suite نشون میدیم.
ما همچنین کارایی و انعطافپذیری معماری MoSE رو در یه موتور تصمیمگیری واقعی در Gmail که میلیونها کاربر داره، با ایجاد تعادل بین کیفیت جستجو و هزینههای منابع، به نمایش میذاریم.»
بعد، نزدیکای آخر مقاله، این نتایج فوقالعاده رو گزارش میده:
«ما بر دو مزیت MoSE تأکید میکنیم. اول اینکه از نظر عملکرد، MoSE به طور قابل توجهی از مدل پایه مشترک که خیلی بهینهسازی شده، بهتر عمل میکنه. با نیاز به ۸۰٪ صرفهجویی در منابع، MoSE میتونه تقریباً ۸٪ کلیکهای جستجوی اسناد بیشتری رو حفظ کنه که در محصول خیلی مهمه.
همچنین، MoSE به دلیل قدرت مدلسازیش، در سطوح مختلف صرفهجویی در منابع، مقاومه، حتی با اینکه ما در طول آموزش به وظایف وزنهای مساوی اختصاص دادیم.»
و درباره قدرت و انعطافپذیری محضش برای تغییر، با افتخار میگه:
«این به MoSE انعطافپذیری بیشتری میده وقتی که نیازهای کسبوکار در عمل مدام در حال تغییره، چون یه مدل مقاومتر مثل MoSE ممکنه نیاز به آموزش مجدد مدل رو کاهش بده، در مقایسه با مدلهایی که به وزنهای اهمیت در طول آموزش حساسترن.»
مام، MoSE و ترنسفورمر
اعلام شد که MUM با استفاده از تکنیک ترنسفورمر (Transformer) ساخته شده.
تو معرفی گوگل اومده بود:
«MUM پتانسیل این رو داره که نحوه کمک گوگل به شما در کارهای پیچیده رو متحول کنه. MUM هم مثل BERT، بر اساس معماری ترنسفورمر ساخته شده، اما ۱۰۰۰ برابر قدرتمندتره.»
نتایجی که تو مقاله تحقیقاتی MoSE در دسامبر ۲۰۲۰، یعنی شش ماه قبلش، گزارش شده بود، فوقالعاده بود.
اما نسخهای از MoSE که در سال ۲۰۲۰ آزمایش شد، با استفاده از معماری ترنسفورمر ساخته نشده بود. محققان اشاره کردن که MoSE میتونه به راحتی با ترنسفورمرها توسعه داده بشه.
محققان (در مقالهای که در دسامبر ۲۰۲۰ منتشر شد) به ترنسفورمرها به عنوان یه مسیر آینده برای MoSE اشاره کردن:
«آزمایش با تکنیکهای پیشرفتهتر مثل ترنسفورمر به عنوان کار آینده در نظر گرفته شده.
… MoSE، که از بلوکهای ساختمانی عمومی تشکیل شده، میتونه به راحتی توسعه داده بشه، مثلاً با استفاده از واحدهای مدلسازی متوالی دیگه به جز LSTM، از جمله GRU ها، attention ها و ترنسفورمرها…»
بنابراین طبق این مقاله تحقیقاتی، MoSE میتونه به راحتی با استفاده از معماریهای دیگه مثل ترنسفورمرها، فوقالعاده قدرتمند بشه. این یعنی MoSE میتونه بخشی از چیزی باشه که گوگل به عنوان MUM معرفی کرده.
چرا موفقیت MoSE قابل توجهه؟
گوگل پتنتها و مقالات تحقیقاتی الگوریتمهای زیادی منتشر میکنه. خیلی از اونها مرزهای دانش روز رو جابجا میکنن و در عین حال به نقصها و خطاهایی اشاره میکنن که به تحقیقات بیشتری نیاز داره.
اما در مورد MoSE اینطور نیست. کاملاً برعکسه. محققان به دستاوردهای MoSE اشاره میکنن و اینکه هنوز فرصت برای بهتر کردنش هم وجود داره.
چیزی که تحقیقات MoSE رو حتی قابل توجهتر میکنه، سطح موفقیتیه که ادعا میکنه و دری که برای بهتر شدن باز میذاره.
وقتی یه مقاله تحقیقاتی ادعای موفقیت میکنه و نه ترکیبی از موفقیت و شکست، این موضوع قابل توجه و مهمه.
این موضوع به خصوص وقتی صادقه که محققان ادعا میکنن این موفقیتها رو بدون نیاز به منابع قابل توجهی به دست آوردن.
آیا MoSE همون فناوری هوش مصنوعی گوگل MUM هست؟
MUM به عنوان یه فناوری هوش مصنوعی (Artificial Intelligence) توصیف شده. MoSE تو وبلاگ هوش مصنوعی گوگل به عنوان هوش ماشینی (Machine Intelligence) دستهبندی شده. تفاوت بین هوش مصنوعی و هوش ماشینی چیه؟ خیلی زیاد نیست، تقریباً تو یه دستهبندی قرار میگیرن (توجه کنید که من نوشتم هوش *ماشینی*، نه یادگیری ماشین). پایگاه داده انتشارات هوش مصنوعی گوگل، مقالات تحقیقاتی در زمینه هوش مصنوعی رو زیر دسته هوش ماشینی طبقهبندی میکنه. دستهبندیای به اسم هوش مصنوعی وجود نداره.
ما نمیتونیم با قطعیت بگیم که MoSE بخشی از فناوری زیربنایی MUM گوگل هست.
- ممکنه MUM در واقع مجموعهای از فناوریها باشه که با هم کار میکنن و MoSE بخشی از اون باشه.
- ممکنه MoSE بخش عمدهای از گوگل MUM باشه.
- یا ممکنه MoSE اصلاً هیچ ربطی به MUM نداشته باشه.
با این حال، خیلی جالبه که MoSE یه رویکرد موفق برای پیشبینی رفتار جستجوی کاربره و به راحتی میتونه با استفاده از ترنسفورمرها مقیاسپذیر بشه.
چه این بخشی از فناوری MUM گوگل باشه چه نباشه، الگوریتمهایی که تو این مقالهها توصیف شدن، نشون میدن که جدیدترین دستاوردهای حوزه بازیابی اطلاعات چی هستن.
پاسخی بگذارید