
هوش مصنوعی مولد: دقیقاً چیه و چطور کار میکنه؟
قراره با هم عمیق بشیم توی اینکه مدلهای هوش مصنوعی مولد چطور کار میکنن، چه کارایی از دستشون برمیاد و چه کارایی نه، و پیامدهای همهی اینها چی میتونه باشه.
هوش مصنوعی مولد (Generative AI)، که یه زیرمجموعه از هوش مصنوعیه، مثل یه نیروی انقلابی تو دنیای تکنولوژی ظاهر شده. اما دقیقاً چی هست؟ و چرا اینقدر سروصدا کرده و توجه همه رو به خودش جلب کرده؟
این راهنمای جامع قراره کامل براتون توضیح بده که مدلهای هوش مصنوعی مولد چطور کار میکنن، چه تواناییهایی دارن و چه محدودیتهایی، و همهی اینها چه تأثیری روی دنیای ما میذاره.
هوش مصنوعی مولد چیه؟
هوش مصنوعی مولد، یا به اختصار genAI، به سیستمهایی گفته میشه که میتونن محتوای جدیدی تولید کنن؛ فرقی هم نمیکنه این محتوا متن باشه، عکس، موسیقی یا حتی ویدیو. به طور سنتی، هوش مصنوعی/یادگیری ماشین (AI/ML) سه تا معنی داشت: یادگیری نظارتشده، نظارتنشده و تقویتی. هر کدوم از اینها بر اساس خروجیهای خوشهبندیشده، یه سری بینش به ما میدن.
مدلهای هوش مصنوعی غیرمولد (Non-generative) بر اساس ورودی محاسبات انجام میدن (مثلاً یه عکس رو دستهبندی میکنن یا یه جمله رو ترجمه میکنن). در مقابل، مدلهای مولد خروجیهای «جدید» تولید میکنن؛ مثلاً مقاله مینویسن، موسیقی میسازن، طرحهای گرافیکی طراحی میکنن و حتی چهرههای واقعگرایانهی انسانهایی رو میسازن که تو دنیای واقعی وجود ندارن.
پیامدهای هوش مصنوعی مولد
ظهور هوش مصنوعی مولد پیامدهای خیلی مهمی داره. با توانایی تولید محتوا، صنایعی مثل سرگرمی، طراحی و روزنامهنگاری دارن یه تغییر پارادایم اساسی رو تجربه میکنن.
مثلاً، خبرگزاریها میتونن از هوش مصنوعی برای نوشتن پیشنویس گزارشهاشون استفاده کنن، در حالی که طراحها میتونن برای کارهای گرافیکیشون از هوش مصنوعی پیشنهادهای خلاقانه بگیرن. هوش مصنوعی میتونه تو چند ثانیه صدها شعار تبلیغاتی تولید کنه – البته اینکه این گزینهها خوب هستن یا نه، یه بحث دیگهست.
هوش مصنوعی مولد میتونه محتوای سفارشیشده برای هر کاربر تولید کنه. مثلاً یه اپلیکیشن موسیقی رو تصور کنید که بر اساس حال و هوای شما یه آهنگ منحصربهفرد میسازه، یا یه اپلیکیشن خبری که مقالههایی در مورد موضوعات مورد علاقهی شما مینویسه.
مسئله اینجاست که هرچی هوش مصنوعی نقش پررنگتری تو تولید محتوا بازی میکنه، سؤالهایی در مورد اصالت، حق کپیرایت و ارزش خلاقیت انسانی هم بیشتر مطرح میشه.
هوش مصنوعی مولد چطور کار میکنه؟
هوش مصنوعی مولد، تو هستهی خودش، کارش پیشبینی قطعهی بعدی داده تو یه دنباله است؛ چه کلمهی بعدی تو یه جمله باشه، چه پیکسل بعدی تو یه عکس. بیایید ببینیم این کار چطوری انجام میشه.
مدلهای آماری
مدلهای آماری ستون فقرات اکثر سیستمهای هوش مصنوعی هستن. این مدلها از معادلات ریاضی برای نشون دادن رابطه بین متغیرهای مختلف استفاده میکنن.
برای هوش مصنوعی مولد، مدلها طوری آموزش میبینن که الگوها رو توی دادهها تشخیص بدن و بعد از این الگوها برای تولید دادههای جدید و مشابه استفاده کنن.
اگه یه مدل روی جملات فارسی آموزش ببینه، احتمال آماری اومدن یه کلمه بعد از کلمهی دیگه رو یاد میگیره و این بهش اجازه میده جملات منسجم و معناداری تولید کنه.
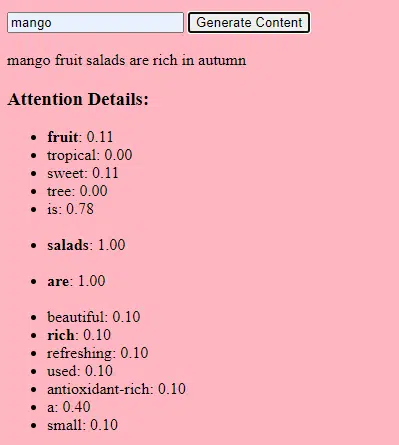
جمعآوری داده
هم کیفیت و هم کمیت دادهها خیلی مهمه. مدلهای مولد روی مجموعه دادههای عظیمی آموزش میبینن تا الگوها رو درک کنن.
برای یه مدل زبانی، این ممکنه به معنی پردازش میلیاردها کلمه از کتابها، وبسایتها و متون دیگه باشه.
برای یه مدل تصویری، میتونه به معنی تحلیل میلیونها عکس باشه. هرچی دادههای آموزشی متنوعتر و جامعتر باشن، مدل هم خروجیهای متنوعتر و بهتری تولید میکنه.
ترنسفورمرها و مکانیزم توجه چطور کار میکنن؟
ترنسفورمرها (Transformers) یه نوع معماری شبکهی عصبی هستن که تو مقالهای در سال ۲۰۱۷ به اسم «تنها چیزی که نیاز داری، توجه است» (Attention Is All You Need) توسط Vaswani و همکارانش معرفی شدن. از اون موقع تا حالا، این معماری پایهی اکثر مدلهای زبانی پیشرفته شده. بدون ترنسفورمرها، ChatGPT اصلاً کار نمیکرد.
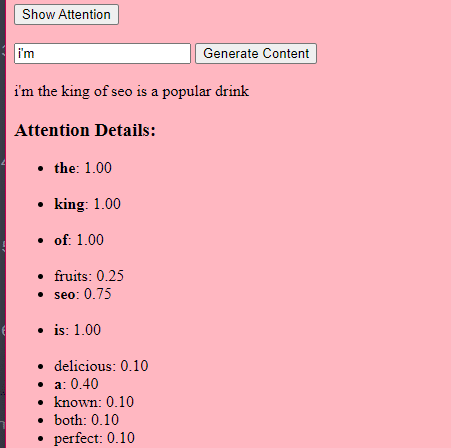
مکانیزم «توجه» (attention) به مدل اجازه میده روی بخشهای مختلف دادهی ورودی تمرکز کنه، خیلی شبیه به اینکه ما آدما برای فهمیدن یه جمله به کلمات خاصی توجه میکنیم.
این مکانیزم به مدل اجازه میده تصمیم بگیره کدوم قسمتهای ورودی برای یه کار خاص مرتبطتره و همین باعث میشه خیلی انعطافپذیر و قدرتمند باشه.
کد زیر یه توضیح پایهای از مکانیزمهای ترنسفورمر رو نشون میده و هر قسمت رو به زبان ساده توضیح میده.
class Transformer:
# کلمات رو به وکتور (بردار) تبدیل میکنه
# این چیه: کلمات رو به "بردارهای جاسازی شده" (vector embeddings) تبدیل میکنه – یعنی یه سری عدد که نمایندهی کلمات و رابطهشون با همدیگهست.
# مثال: "این آناناس باحال و خوشمزهست" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9]
self.embedding = Embedding(vocab_size, d_model)
# اطلاعات موقعیت رو به بردارها اضافه میکنه
# این چیه: چون کلمات تو یه جمله ترتیب خاصی دارن، ما اطلاعاتی در مورد موقعیت هر کلمه تو جمله اضافه میکنیم.
# مثال: "این آناناس باحال و خوشمزهست" با اطلاعات موقعیت -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06]
self.positional_encoding = PositionalEncoding(d_model)
# مجموعهای از لایههای ترنسفورمر
# این چیه: چندین لایه از مدل ترنسفورمر که روی هم قرار گرفتن تا دادهها رو عمیقاً پردازش کنن.
# چرا این کار رو میکنه: هر لایه الگوها و روابط متفاوتی رو توی دادهها پیدا میکنه.
# توضیح برای یه بچه ۵ ساله: یه ساختمون چند طبقه رو تصور کن. هر طبقه (یا لایه) آدمایی (یا مکانیزمهایی) داره که کارهای مشخصی انجام میدن. هرچی طبقات بیشتر باشه، کارهای بیشتری انجام میشه!
self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)]
# بردارهای خروجی رو به احتمال کلمات تبدیل میکنه
# این چیه: یه راه برای پیشبینی کلمهی بعدی تو یه دنباله.
# چرا این کار رو میکنه: بعد از پردازش ورودی، میخوایم حدس بزنیم کلمهی بعدی چیه.
# توضیح برای یه بچه ۵ ساله: بعد از گوش دادن به یه داستان، سعی میکنه حدس بزنه بعدش چی میشه.
self.output_layer = Linear(d_model, vocab_size)
def forward(self, x):
# کلمات رو به بردار تبدیل میکنه، مثل بالا
x = self.embedding(x)
# اطلاعات موقعیت رو اضافه میکنه، مثل بالا
x = self.positional_encoding(x)
# از هر لایهی ترنسفورمر عبور میده
# این چیه: دادههامون رو از هر طبقهی اون ساختمون چند طبقهمون عبور میدیم.
# چرا این کار رو میکنه: برای پردازش و درک عمیق دادهها.
# توضیح برای یه بچه ۵ ساله: مثل اینه که سر کلاس یه یادداشت رو دست به دست کنی. هر نفر (یا لایه) یه چیزی به یادداشت اضافه میکنه قبل از اینکه به نفر بعدی بده، که تهش میتونه یه داستان منسجم از آب دربیاد – یا یه چیز درهم و برهم.
for layer in self.transformer_layers:
x = layer(x)
# احتمال کلمات خروجی رو به دست میاره
# این چیه: بهترین حدس ما برای کلمهی بعدی تو دنباله.
return self.output_layer(x)
توی کد، ممکنه یه کلاس Transformer و یه کلاس TransformerLayer داشته باشید. این مثل اینه که یه نقشه برای یه طبقه داشته باشید در مقابل یه ساختمون کامل.
این تیکه کد TransformerLayer به شما نشون میده که اجزای خاصی مثل توجه چندسر (multi-head attention) و چینشهای خاص چطور کار میکنن.
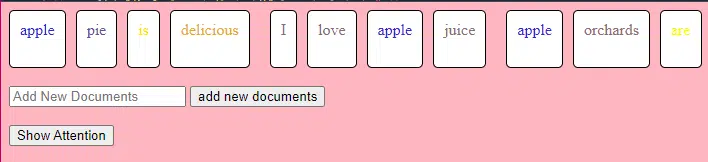
class TransformerLayer:
# مکانیزم توجه چندسر (Multi-head attention)
# این چیه: مکانیزمی که به مدل اجازه میده همزمان روی بخشهای مختلف دادهی ورودی تمرکز کنه.
# مثال: "این آناناس باحال و خوشمزهست" ممکنه تبدیل بشه به "این آناناس، باحال و خوشمزهست" چون مدل به کلمات خاصی بیشتر توجه میکنه.
self.attention = MultiHeadAttention(d_model, nhead)
# شبکهی عصبی ساده پیشخور (Feed-forward)
# این چیه: یه شبکهی عصبی پایه که دادهها رو بعد از مکانیزم توجه پردازش میکنه.
# مثال: "این آناناس، باحال و خوشمزهست" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (تغییرات جزئی در اعداد بعد از پردازش)
self.feed_forward = FeedForward(d_model)
def forward(self, x):
# اعمال مکانیزم توجه
# این چیه: مرحلهای که روی بخشهای مختلف جمله تمرکز میکنیم.
# توضیح برای یه بچه ۵ ساله: مثل اینه که قسمتهای مهم یه کتاب رو هایلایت کنی.
attention_output = self.attention(x, x, x)
# عبور دادن خروجی از شبکهی پیشخور
# این چیه: مرحلهای که اطلاعات هایلایتشده رو پردازش میکنیم.
return self.feed_forward(attention_output)
یه شبکهی عصبی پیشخور (feed-forward) یکی از سادهترین انواع شبکههای عصبی مصنوعی هست. این شبکه از یه لایهی ورودی، یک یا چند لایهی پنهان و یه لایهی خروجی تشکیل شده.
دادهها تو یه جهت حرکت میکنن – از لایهی ورودی، از طریق لایههای پنهان و به لایهی خروجی میرسن. هیچ حلقه یا چرخهای تو این شبکه وجود نداره.
در زمینهی معماری ترنسفورمر، شبکهی عصبی پیشخور بعد از مکانیزم توجه تو هر لایه استفاده میشه. این یه تبدیل خطی دو لایهی ساده است که بینشون یه تابع فعالسازی ReLU قرار داره.
# مکانیزم توجه ضرب نقطهای مقیاسشده (Scaled dot-product attention)
class ScaledDotProductAttention:
def __init__(self, d_model):
# ضریب مقیاسبندی به پایدارسازی گرادیانها کمک میکنه
# و واریانس ضرب نقطهای رو کاهش میده.
# این چیه: یه ضریب مقیاسبندی بر اساس اندازهی بردارهای مدل ما.
# چیکار میکنه: کمک میکنه مطمئن بشیم که ضربهای نقطهای خیلی بزرگ نشن.
# چرا این کار رو میکنه: ضربهای نقطهای بزرگ میتونن مدل رو ناپایدار و آموزشش رو سخت کنن.
# چطوری این کار رو میکنه: با تقسیم کردن ضربهای نقطهای بر ریشهی دوم اندازهی بردار.
# این موقع محاسبهی امتیازهای توجه استفاده میشه.
# توضیح برای یه بچه ۵ ساله: فرض کن یه چیزی رو خیلی بلند فریاد زدی. این ضریب مقیاسبندی مثل اینه که صدا رو کم کنی تا خیلی بلند نباشه.
self.scaling_factor = d_model ** 0.5
def forward(self, query, key, value):
# این چیه: تابعی که محاسبه میکنه هر کلمه چقدر باید توجه بگیره.
# چیکار میکنه: تعیین میکنه هر کلمه تو یه جمله چقدر به هر کلمهی دیگهای مرتبطه.
# چرا این کار رو میکنه: تا بتونیم موقع فهمیدن یه جمله، بیشتر روی کلمات مهم تمرکز کنیم.
# چطوری این کار رو میکنه: با گرفتن ضرب نقطهای (یه راه برای اندازهگیری شباهت) بین query و key، بعد مقیاسبندیش و در نهایت استفاده از اون برای وزندهی به valueها.
# چطور تو بقیهی کد جا میگیره: این تابع هر وقت بخوایم توجه رو تو مدلمون محاسبه کنیم، فراخوانی میشه.
# توضیح برای یه بچه ۵ ساله: فرض کن یه اسباببازی داری و میخوای ببینی کدوم یکی از دوستات بیشتر دوستش داره. این تابع مثل اینه که از هر دوستت بپرسی چقدر اسباببازی رو دوست داره و بعد بر اساس جوابهاشون تصمیم بگیری کی باهاش بازی کنه.
# محاسبهی امتیازهای توجه با گرفتن ضرب نقطهای بین query و key.
scores = dot_product(query, key) / self.scaling_factor
# تبدیل امتیازهای خام به احتمال با استفاده از تابع softmax.
attention_weights = softmax(scores)
# وزندهی به valueها با استفاده از احتمالهای توجه.
return dot_product(attention_weights, value)
# شبکهی عصبی پیشخور
# این یه مثال خیلی ابتدایی از یه شبکهی عصبیه.
class FeedForward:
def __init__(self, d_model):
# لایهی خطی اول ابعاد داده رو افزایش میده.
self.layer1 = Linear(d_model, d_model * 4)
# لایهی خطی دوم ابعاد رو به d_model برمیگردونه.
self.layer2 = Linear(d_model * 4, d_model)
def forward(self, x):
# عبور دادن ورودی از لایهی اول،
#عبور دادن ورودی از لایهی اول:
# ورودی: به دادهای گفته میشه که به شبکهی عصبی میدین.
#لایهی اول: شبکههای عصبی از لایهها تشکیل شدن و هر لایه نورون داره. وقتی میگیم "ورودی رو از لایهی اول عبور بدیم"، یعنی دادهی ورودی توسط نورونهای این لایه پردازش میشه. هر نورون ورودی رو میگیره، در وزنهای خودش (که موقع آموزش یاد گرفته میشن) ضرب میکنه و یه خروجی تولید میکنه.
# اعمال تابع فعالسازی ReLU برای معرفی غیرخطی بودن،
# و بعد عبور از لایهی دوم.
#فعالسازی ReLU: ReLU مخفف Rectified Linear Unit هست.
# این یه نوع تابع فعالسازیه که یه تابع ریاضیه که به خروجی هر نورون اعمال میشه. به زبان ساده، اگه ورودی مثبت باشه، همون مقدار ورودی رو برمیگردونه؛ اگه ورودی منفی یا صفر باشه، صفر برمیگردونه.
# شبکههای عصبی میتونن با معرفی غیرخطی بودن، روابط پیچیدهی دادهها رو مدلسازی کنن.
# بدون توابع فعالسازی غیرخطی، مهم نیست چند تا لایه تو یه شبکهی عصبی روی هم بذارین، باز هم مثل یه پرسپترون تکلایه عمل میکنه چون جمع کردن این لایهها یه مدل خطی دیگه به شما میده.
# غیرخطی بودن به شبکه اجازه میده الگوهای پیچیده رو بگیره و پیشبینیهای بهتری انجام بده.
return self.layer2(relu(self.layer1(x)))
# کدگذاری موقعیتی (Positional encoding) اطلاعاتی در مورد موقعیت هر کلمه تو دنباله اضافه میکنه.
class PositionalEncoding:
def __init__(self, d_model):
# این چیه: یه تنظیمات برای اضافه کردن اطلاعات در مورد جایگاه هر کلمه تو یه جمله.
# چیکار میکنه: آماده میشه تا یه مقدار "موقعیت" منحصربهفرد به هر کلمه اضافه کنه.
# چرا این کار رو میکنه: کلمات تو یه جمله ترتیب دارن و این به مدل کمک میکنه اون ترتیب رو به خاطر بسپره.
# چطوری این کار رو میکنه: با ایجاد یه الگوی خاص از اعداد برای هر موقعیت تو یه جمله.
# چطور تو بقیهی کد جا میگیره: قبل از پردازش کلمات، اطلاعات موقعیتشون رو اضافه میکنیم.
# توضیح برای یه بچه ۵ ساله: فرض کن با دوستات تو یه صف وایسادین. این به هر کس یه شماره میده تا جاشون تو صف رو یادشون بمونه.
pass
def forward(self, x):
# این چیه: تابع اصلی که اطلاعات موقعیت رو به کلمات ما اضافه میکنه.
# چیکار میکنه: مقدار اصلی کلمه رو با مقدار موقعیتش ترکیب میکنه.
# چرا این کار رو میکنه: تا مدل ترتیب کلمات تو یه جمله رو بدونه.
# چطوری این کار رو میکنه: با اضافه کردن مقادیر موقعیتی که قبلاً آماده کردیم به مقادیر کلمات.
# چطور تو بقیهی کد جا میگیره: این تابع هر وقت بخوایم اطلاعات موقعیت رو به کلماتمون اضافه کنیم، فراخوانی میشه.
# توضیح برای یه بچه ۵ ساله: مثل اینه که به هر کدوم از اسباببازیهات یه برچسب بزنی که بگه این اسباببازی اول، دوم، سوم و... هست.
return x
# توابع کمکی
def dot_product(a, b):
# ضرب نقطهای دو ماتریس رو محاسبه میکنه.
# این چیه: یه عملیات ریاضی برای اینکه ببینیم دو تا لیست از اعداد چقدر شبیه به هم هستن.
# چیکار میکنه: آیتمهای متناظر تو لیستها رو ضرب میکنه و بعد جمعشون میکنه.
# چرا این کار رو میکنه: برای اندازهگیری شباهت یا ارتباط بین دو مجموعه داده.
# چطوری این کار رو میکنه: با ضرب کردن و جمع کردن.
# چطور تو بقیهی کد جا میگیره: تو مکانیزم توجه استفاده میشه تا ببینیم کلمات چقدر به هم مرتبط هستن.
# توضیح برای یه بچه ۵ ساله: فرض کن تو و دوستت هر کدوم یه کیسه شکلات دارین. هر دوتون شکلاتهاتون رو میریزین بیرون و هر نوع شکلات رو با هم جور میکنین. بعد میشمرین که چند تا جفت جور شده دارین.
return a @ b.transpose(-2, -1)
def softmax(x):
# امتیازهای خام رو به احتمال تبدیل میکنه و مطمئن میشه که جمعشون ۱ میشه.
# این چیه: یه راه برای تبدیل هر لیستی از اعداد به احتمال.
# چیکار میکنه: اعداد رو بین ۰ و ۱ میکنه و مطمئن میشه که همشون با هم جمع بشن ۱.
# چرا این کار رو میکنه: تا بتونیم اعداد رو به عنوان شانس یا احتمال درک کنیم.
# چطوری این کار رو میکنه: با استفاده از توانرسانی و تقسیم.
# چطور تو بقیهی کد جا میگیره: برای تبدیل امتیازهای توجه به احتمال استفاده میشه.
# توضیح برای یه بچه ۵ ساله: برگردیم سراغ اسباببازیهامون. این کار مطمئن میشه که وقتی اسباببازیها رو تقسیم میکنی، به همه سهم عادلانهای برسه و هیچ اسباببازیای جا نمونه.
return exp(x) / sum(exp(x), axis=-1)
def relu(x):
# تابع فعالسازی که غیرخطی بودن رو معرفی میکنه. مقادیر منفی رو به ۰ تبدیل میکنه.
# این چیه: یه قانون ساده برای اعداد.
# چیکار میکنه: اگه یه عدد منفی باشه، اون رو به صفر تغییر میده. در غیر این صورت، همونطور که هست باقی میذاره.
# چرا این کار رو میکنه: برای معرفی کمی سادگی و غیرخطی بودن تو محاسبات مدلمون.
# چطوری این کار رو میکنه: با بررسی هر عدد و تبدیلش به صفر اگه منفی باشه.
# چطور تو بقیهی کد جا میگیره: تو شبکههای عصبی استفاده میشه تا اونها رو قدرتمندتر و انعطافپذیرتر کنه.
# توضیح برای یه بچه ۵ ساله: فرض کن یه سری برچسب داری، بعضیهاشون براقن (اعداد مثبت) و بعضیهاشون مات (اعداد منفی). این قانون میگه همهی برچسبهای مات رو با برچسبهای سفید جایگزین کن.
return max(0, x)
هوش مصنوعی مولد به زبان ساده چطور کار میکنه؟
هوش مصنوعی مولد رو مثل انداختن یه تاس وزندار در نظر بگیرید. دادههای آموزشی، وزنها (یا احتمالات) رو تعیین میکنن.
اگه تاس نمایندهی کلمهی بعدی تو یه جمله باشه، کلمهای که تو دادههای آموزشی اغلب بعد از کلمهی فعلی اومده، وزن بیشتری خواهد داشت. بنابراین، «آسمان» ممکنه بیشتر از «موز» بعد از «آبی» بیاد. وقتی هوش مصنوعی «تاس رو میندازه» تا محتوا تولید کنه، به احتمال زیاد دنبالههایی رو انتخاب میکنه که بر اساس آموزشش از نظر آماری محتملتر هستن.
خب، پس چطور مدلهای زبانی بزرگ (LLM) میتونن محتوایی تولید کنن که «به نظر» اصیل و جدید میاد؟
بیایید یه لیست ساختگی رو مثال بزنیم – «بهترین هدیههای عید فطر برای فعالان حوزهی بازاریابی محتوا» – و مرحله به مرحله ببینیم یه LLM چطور میتونه این لیست رو با ترکیب سرنخهای متنی از اسنادی در مورد هدیهها، عید فطر و بازاریابان محتوا تولید کنه.
قبل از پردازش، متن به قطعات کوچکتری به نام «توکن» (token) شکسته میشه. این توکنها میتونن به کوتاهی یک کاراکتر یا به بلندی یک کلمه باشن.
مثال: «عید فطر یک جشن است» تبدیل میشه به [«عید»، «فطر»، «یک»، «جشن»، «است»].
این کار به مدل اجازه میده با تیکههای قابل مدیریت از متن کار کنه و ساختار جملات رو بفهمه.
بعد هر توکن با استفاده از امبدینگها (embeddings) به یک بردار (لیستی از اعداد) تبدیل میشه. این بردارها معنی و زمینهی هر کلمه رو در خودشون دارن.
کدگذاری موقعیتی (Positional encoding) اطلاعاتی در مورد موقعیت هر کلمه در جمله به بردار اون کلمه اضافه میکنه و این اطمینان رو میده که مدل این اطلاعات ترتیب رو از دست نده.
بعد از مکانیزم توجه استفاده میکنیم: این مکانیزم به مدل اجازه میده موقع تولید خروجی، روی بخشهای مختلف متن ورودی تمرکز کنه. اگه مدل BERT رو یادتون باشه، این همون چیزی بود که مهندسای گوگل رو در موردش هیجانزده کرده بود.
اگه مدل ما متنهایی در مورد «هدیه» دیده باشه و بدونه که مردم موقع جشنها به هم هدیه میدن، و همچنین متنهایی دیده باشه که «عید فطر» یه جشن مهمه، به این ارتباطات «توجه» میکنه.
به همین ترتیب، اگه متنهایی در مورد «بازاریابان محتوا» دیده باشه که به ابزارها یا منابع خاصی نیاز دارن، میتونه ایدهی «هدیه» رو به «بازاریابان محتوا» وصل کنه.

حالا میتونیم زمینهها رو با هم ترکیب کنیم: وقتی مدل متن ورودی رو از طریق لایههای متعدد ترنسفورمر پردازش میکنه، زمینههایی که یاد گرفته رو با هم ترکیب میکنه.
بنابراین، حتی اگه تو متون اصلی هیچوقت به «هدیههای عید فطر برای بازاریابان محتوا» اشاره نشده باشه، مدل میتونه مفاهیم «عید فطر»، «هدیه» و «بازاریابان محتوا» رو کنار هم بذاره و این محتوا رو تولید کنه.
دلیلش اینه که مدل زمینههای گستردهتری رو حول هر کدوم از این اصطلاحات یاد گرفته.
بعد از پردازش ورودی از طریق مکانیزم توجه و شبکههای پیشخور در هر لایهی ترنسفورمر، مدل یه توزیع احتمال روی واژگان خودش برای کلمهی بعدی در دنباله تولید میکنه.
ممکنه فکر کنه که بعد از کلماتی مثل «بهترین» و «عید فطر»، کلمهی «هدیهها» احتمال بالایی برای اومدن داره. به همین ترتیب، ممکنه «هدیهها» رو با گیرندگان بالقوهای مثل «بازاریابان محتوا» مرتبط بدونه.
مدلهای زبانی بزرگ (LLM) چطور ساخته میشن؟
سفر از یه مدل ترنسفورمر پایه به یه مدل زبانی بزرگ (LLM) پیشرفته مثل GPT-3 یا BERT شامل بزرگکردن و اصلاح اجزای مختلفه.
اینجا یه توضیح قدم به قدم داریم:
LLMها روی حجم عظیمی از دادههای متنی آموزش میبینن. توضیح اینکه این دادهها چقدر عظیم هستن سخته.
مجموعه دادهی C4، که نقطهی شروع خیلی از LLMهاست، ۷۵۰ گیگابایت دادهی متنیه. این یعنی ۸۰۵,۳۰۶,۳۶۸,۰۰۰ بایت – یه عالمه اطلاعات. این دادهها میتونن شامل کتابها، مقالات، وبسایتها، انجمنها، بخش نظرات و منابع دیگه باشن.
هرچی دادهها متنوعتر و جامعتر باشن، درک و قابلیت تعمیمدهی مدل هم بهتر میشه.
در حالی که معماری پایهی ترنسفورمر همچنان اساس کاره، LLMها تعداد پارامترهای بسیار بیشتری دارن. مثلاً GPT-3، ۱۷۵ میلیارد پارامتر داره. در این مورد، پارامترها به وزنها و بایاسها در شبکهی عصبی اشاره دارن که در طول فرآیند آموزش یاد گرفته میشن.
در یادگیری عمیق، یه مدل آموزش میبینه که با تنظیم این پارامترها، تفاوت بین پیشبینیهاش و نتایج واقعی رو کم کنه و پیشبینیهای بهتری انجام بده.
فرآیند تنظیم این پارامترها بهینهسازی نامیده میشه که از الگوریتمهایی مثل گرادیان کاهشی (gradient descent) استفاده میکنه.
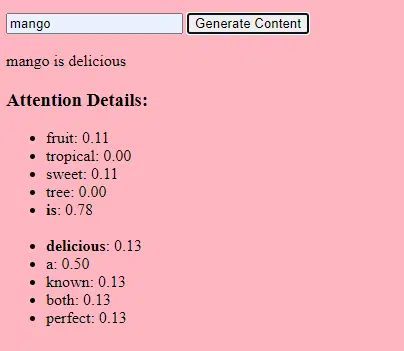
- وزنها (Weights): اینها مقادیری در شبکهی عصبی هستن که دادههای ورودی رو در لایههای شبکه تغییر میدن. این مقادیر در طول آموزش تنظیم میشن تا خروجی مدل بهینه بشه. هر اتصال بین نورونها در لایههای مجاور یه وزن مرتبط داره.
- بایاسها (Biases): اینها هم مقادیری در شبکهی عصبی هستن که به خروجی تبدیل یک لایه اضافه میشن. اینها درجهی آزادی بیشتری به مدل میدن و بهش اجازه میدن بهتر با دادههای آموزشی تطبیق پیدا کنه. هر نورون در یک لایه یه بایاس مرتبط داره.
این مقیاسبندی به مدل اجازه میده الگوها و روابط پیچیدهتری رو در دادهها ذخیره و پردازش کنه.
تعداد زیاد پارامترها همچنین به این معنیه که مدل برای آموزش و استنتاج به توان محاسباتی و حافظهی قابل توجهی نیاز داره. به همین دلیله که آموزش چنین مدلهایی منابع زیادی میخواد و معمولاً از سختافزارهای تخصصی مثل GPUها یا TPUها استفاده میشه.
مدل آموزش میبینه که با استفاده از منابع محاسباتی قدرتمند، کلمهی بعدی در یک دنباله رو پیشبینی کنه. این مدل پارامترهای داخلی خودش رو بر اساس خطاهایی که مرتکب میشه تنظیم میکنه و به طور مداوم پیشبینیهاش رو بهبود میده.
مکانیزمهای توجه مثل اونهایی که در موردشون صحبت کردیم، برای LLMها حیاتی هستن. این مکانیزمها به مدل اجازه میدن موقع تولید خروجی، روی بخشهای مختلف ورودی تمرکز کنه.
با وزندهی به اهمیت کلمات مختلف در یک زمینه، مکانیزمهای توجه به مدل این امکان رو میدن که متن منسجم و مرتبط با زمینه تولید کنه. انجام این کار در این مقیاس عظیم، باعث میشه LLMها به این شکلی که میبینیم کار کنن.
یه ترنسفورمر چطور متن رو پیشبینی میکنه؟
ترنسفورمرها با پردازش توکنهای ورودی از طریق لایههای متعدد، متن رو پیشبینی میکنن. هر کدوم از این لایهها به مکانیزمهای توجه و شبکههای پیشخور مجهز هستن.
بعد از پردازش، مدل یه توزیع احتمال روی واژگان خودش برای کلمهی بعدی در دنباله تولید میکنه. کلمهای که بالاترین احتمال رو داره، معمولاً به عنوان پیشبینی انتخاب میشه.
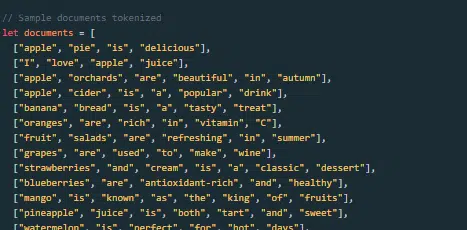
یه مدل زبانی بزرگ چطور ساخته و آموزش داده میشه؟
ساختن یه LLM شامل جمعآوری داده، پاکسازی اون، آموزش مدل، تنظیم دقیق مدل (fine-tuning) و تستهای سختگیرانه و مداومه.
مدل در ابتدا روی یه مجموعهی عظیم از متون آموزش میبینه تا کلمهی بعدی در یک دنباله رو پیشبینی کنه. این مرحله به مدل اجازه میده ارتباطات بین کلمات رو یاد بگیره که الگوهای گرامری، روابطی که میتونن حقایقی در مورد جهان رو نشون بدن و ارتباطاتی که شبیه استدلال منطقی به نظر میرسن رو درک کنه. این ارتباطات همچنین باعث میشن که مدل، سوگیریهای موجود در دادههای آموزشی رو هم یاد بگیره.
بعد از پیشآموزش (pre-training)، مدل روی یه مجموعه دادهی محدودتر و اغلب با بازبینهای انسانی که از دستورالعملهای خاصی پیروی میکنن، اصلاح میشه.
تنظیم دقیق (Fine-tuning) یه مرحلهی حیاتی در ساخت LLMهاست. این کار شامل آموزش مدلِ پیشآموزشدیده روی یه مجموعه داده یا وظیفهی خاصتره. بیایید ChatGPT رو به عنوان مثال در نظر بگیریم.
اگه با مدلهای GPT کار کرده باشین، میدونین که پرامپت دادن کمتر شبیه «این رو بنویس» هست و بیشتر این شکلیه:
- پرامپت: یکی بود یکی نبود
- ادامه: یه جادوگر خبیث بالای یه برج زندگی میکرد.
- پرامپت: چرا مرغه عضو یه گروه موسیقی شد؟
- ادامه: چون ساقهای خوبی برای درام زدن داشت!
برای رسیدن از اون نقطه به ChatGPT، نیروی کار زیادی با دستمزد پایین به کار گرفته میشه. این افراد مجموعههای عظیمی از داده ایجاد میکنن تا روی وزن پاسخهای GPT و رفتارهای مورد انتظار تأثیر بذارن. این کارگران تعداد زیادی متن پرامپت/ادامه میسازن که این شکلی هستن:
- پرامپت: این داستان رو تموم کن: «یکی بود یکی نبود…»
- ادامه: حتماً! یکی بود یکی نبود، در سرزمینی دور، خیلی دور، یه دهکدهی کوچیک بین دو تا کوه با شکوه قرار داشت.
- پرامپت: یه جوک در مورد مرغ بگو.
- ادامه: چرا مرغه عضو یه گروه موسیقی شد؟ چون ساقهای خوبی برای درام زدن داشت!
این فرآیند تنظیم دقیق به چند دلیل ضروریه:
- تخصصی شدن: در حالی که پیشآموزش به مدل یه درک کلی از زبان میده، تنظیم دقیق دانش و رفتارش رو محدودتر میکنه تا با وظایف یا حوزههای خاصی هماهنگ بشه. مثلاً، مدلی که روی دادههای پزشکی تنظیم دقیق شده باشه، سوالات پزشکی رو بهتر جواب میده.
- کنترل: تنظیم دقیق به توسعهدهندهها کنترل بیشتری روی خروجیهای مدل میده. توسعهدهندهها میتونن از یه مجموعه دادهی انتخابشده استفاده کنن تا مدل رو به سمت تولید پاسخهای دلخواه هدایت کنن و از رفتارهای ناخواسته جلوگیری کنن.
- ایمنی: این کار به کاهش خروجیهای مضر یا مغرضانه کمک میکنه. با استفاده از دستورالعملها در طول فرآیند تنظیم دقیق، بازبینهای انسانی میتونن اطمینان حاصل کنن که مدل محتوای نامناسب تولید نمیکنه.
- عملکرد: تنظیم دقیق میتونه به طور قابل توجهی عملکرد مدل رو در وظایف خاص بهبود بده. مثلاً، مدلی که برای پشتیبانی مشتری تنظیم دقیق شده باشه، خیلی بهتر از یه مدل عمومی عمل میکنه.
شما میتونین بفهمین که ChatGPT به روشهای خاصی تنظیم دقیق شده.
مثلاً، «استدلال منطقی» چیزیه که LLMها معمولاً باهاش مشکل دارن. بهترین مدل استدلال منطقی ChatGPT – یعنی GPT-4 – به طور فشرده آموزش دیده تا الگوهای اعداد رو به طور صریح تشخیص بده.
به جای چیزی شبیه این:
- پرامپت: ۲+۲ چند میشه؟
- فرآیند: اغلب تو کتابهای ریاضی بچهها ۲+۲=۴ هست. گاهی اوقات به «۲+۲=۵» هم اشاره میشه ولی معمولاً زمینهی بیشتری در مورد جورج اورول یا استار ترک وجود داره. اگه تو اون زمینه بود، وزن به نفع ۲+۲=۵ بیشتر میشد. ولی اون زمینه وجود نداره، پس تو این مورد توکن بعدی به احتمال زیاد ۴ هست.
- پاسخ: ۲+۲=۴
آموزش یه کاری شبیه این انجام میده:
- آموزش: ۲+۲=۴
- آموزش: ۴/۲=۲
- آموزش: نصف ۴ میشه ۲
- آموزش: ۲ تا ۲ تا میشه چهار تا
… و همینطور ادامه پیدا میکنه.
این یعنی برای اون مدلهای «منطقیتر»، فرآیند آموزش سختگیرانهتر و متمرکزتره تا اطمینان حاصل بشه که مدل اصول منطقی و ریاضی رو درک میکنه و به درستی به کار میبره.
مدل با انواع مسائل ریاضی و راهحلهاشون مواجه میشه تا مطمئن بشیم میتونه این اصول رو تعمیم بده و برای مسائل جدید و دیدهنشده به کار ببره.
اهمیت این فرآیند تنظیم دقیق، به خصوص برای استدلال منطقی، رو نمیشه نادیده گرفت. بدون اون، مدل ممکنه به سوالات سادهی منطقی یا ریاضی پاسخهای نادرست یا بیمعنی بده.
مدلهای تصویری در مقابل مدلهای زبانی
در حالی که هم مدلهای تصویری و هم زبانی ممکنه از معماریهای مشابهی مثل ترنسفورمرها استفاده کنن، دادههایی که پردازش میکنن اساساً متفاوته:
مدلهای تصویری
این مدلها با پیکسلها سروکار دارن و اغلب به صورت سلسلهمراتبی کار میکنن؛ اول الگوهای کوچیک (مثل لبهها) رو تحلیل میکنن، بعد اونها رو ترکیب میکنن تا ساختارهای بزرگتر (مثل شکلها) رو تشخیص بدن و همینطور ادامه میدن تا کل تصویر رو بفهمن.
مدلهای زبانی
این مدلها دنبالههایی از کلمات یا کاراکترها رو پردازش میکنن. اونها باید زمینه، گرامر و معناشناسی رو بفهمن تا متن منسجم و مرتبط با زمینه تولید کنن.
رابطهای کاربری معروف هوش مصنوعی مولد چطور کار میکنن؟
Dall-E و Midjourney
Dall-E یه نسخهی تغییریافته از مدل GPT-3 هست که برای تولید تصویر تطبیق داده شده. این مدل روی یه مجموعه دادهی عظیم از جفتهای متن-تصویر آموزش دیده. Midjourney هم یه نرمافزار تولید تصویر دیگهست که بر اساس یه مدل اختصاصی کار میکنه.
- ورودی: شما یه توصیف متنی میدین، مثلاً «یه فلامینگوی دو سر».
- پردازش: این مدلها این متن رو به یه سری عدد کدگذاری میکنن و بعد این بردارها رو کدگشایی میکنن و روابطشون با پیکسلها رو پیدا میکنن تا یه تصویر تولید کنن. مدل، روابط بین توصیفات متنی و نمایشهای بصری رو از دادههای آموزشی خودش یاد گرفته.
- خروجی: یه تصویر که با توصیف داده شده مطابقت داره یا به اون مرتبطه.
انگشتها، الگوها، مشکلات
چرا این ابزارها نمیتونن همیشه دستهایی تولید کنن که عادی به نظر برسن؟ این ابزارها با نگاه کردن به پیکسلهای کنار هم کار میکنن.
میتونین ببینین این چطور کار میکنه وقتی تصاویر تولید شدهی قدیمیتر یا ابتداییتر رو با تصاویر جدیدتر مقایسه میکنین: مدلهای قدیمیتر خیلی تار به نظر میرسن. در مقابل، مدلهای جدیدتر خیلی واضحتر هستن.
این مدلها با پیشبینی پیکسل بعدی بر اساس پیکسلهایی که قبلاً تولید کردن، تصویر میسازن. این فرآیند میلیونها بار تکرار میشه تا یه تصویر کامل تولید بشه.
دستها، به خصوص انگشتها، پیچیده هستن و جزئیات زیادی دارن که باید به دقت ثبت بشن.
موقعیت، طول و جهت هر انگشت میتونه تو تصاویر مختلف خیلی متفاوت باشه.
وقتی یه تصویر از روی یه توصیف متنی تولید میشه، مدل باید فرضیات زیادی در مورد حالت و ساختار دقیق دست داشته باشه که میتونه منجر به ناهنجاری بشه.
ChatGPT
ChatGPT بر اساس معماری GPT-3.5 ساخته شده که یه مدل مبتنی بر ترنسفورمره و برای وظایف پردازش زبان طبیعی طراحی شده.
- ورودی: یه پرامپت یا یه سری پیام برای شبیهسازی یه مکالمه.
- پردازش: ChatGPT از دانش وسیع خودش که از متون متنوع اینترنتی به دست آورده برای تولید پاسخ استفاده میکنه. این مدل زمینهی ارائه شده در مکالمه رو در نظر میگیره و سعی میکنه مرتبطترین و منسجمترین پاسخ رو تولید کنه.
- خروجی: یه پاسخ متنی که مکالمه رو ادامه میده یا به اون جواب میده.
تخصص
نقطهی قوت ChatGPT در توانایی اون برای مدیریت موضوعات مختلف و شبیهسازی مکالمات شبهانسانیه که اون رو برای چتباتها و دستیارهای مجازی ایدهآل میکنه.
Bard و تجربهی مولد جستجو (SGE)
در حالی که جزئیات خاص ممکنه اختصاصی باشن، Bard بر اساس تکنیکهای هوش مصنوعی ترنسفورمر ساخته شده، شبیه به سایر مدلهای زبانی پیشرفته. SGE بر اساس مدلهای مشابهی ساخته شده ولی الگوریتمهای یادگیری ماشین دیگهای که گوگل استفاده میکنه رو هم در خودش داره.
SGE احتمالاً با استفاده از یه مدل مولد مبتنی بر ترنسفورمر محتوا تولید میکنه و بعد جوابها رو از صفحات رتبهبندی شده در جستجو به صورت فازی استخراج میکنه. (این ممکنه درست نباشه. فقط یه حدسه بر اساس اینکه به نظر میرسه چطور کار میکنه. لطفاً ازم شکایت نکنید!)
- ورودی: یه پرامپت/دستور/جستجو
- پردازش: Bard ورودی رو پردازش میکنه و مثل بقیهی LLMها کار میکنه. SGE از یه معماری مشابه استفاده میکنه ولی یه لایه اضافه میکنه که تو اون دانش داخلی خودش (که از دادههای آموزشی به دست آورده) رو جستجو میکنه تا یه پاسخ مناسب تولید کنه. این مدل ساختار، زمینه و قصد پرامپت رو در نظر میگیره تا محتوای مرتبط تولید کنه.
- خروجی: محتوای تولید شده که میتونه یه داستان، جواب یا هر نوع متن دیگهای باشه.
کاربردهای هوش مصنوعی مولد (و جنجالهاشون)
هنر و طراحی
هوش مصنوعی مولد حالا میتونه آثار هنری، موسیقی و حتی طراحی محصول ایجاد کنه. این موضوع راههای جدیدی برای خلاقیت و نوآوری باز کرده.
جنجال
ظهور هوش مصنوعی در هنر باعث بحثهایی در مورد از دست رفتن شغلها در زمینههای خلاقانه شده.
علاوه بر این، نگرانیهایی در مورد این موارد وجود داره:
- نقض حقوق کار، به خصوص وقتی که محتوای تولید شده توسط هوش مصنوعی بدون ذکر منبع یا پرداخت غرامت مناسب استفاده میشه.
- تهدید نویسندگان توسط مدیران برای جایگزین کردنشون با هوش مصنوعی یکی از مسائلی بود که باعث اعتصاب نویسندگان شد.
پردازش زبان طبیعی (NLP)
مدلهای هوش مصنوعی حالا به طور گسترده برای چتباتها، ترجمهی زبان و سایر وظایف NLP استفاده میشن.
خارج از رویای هوش مصنوعی عمومی (AGI)، این بهترین استفاده برای LLMهاست چون به یه مدل NLP «همهکاره» نزدیک هستن.
جنجال
خیلی از کاربرا چتباتها رو غیرشخصی و گاهی اوقات آزاردهنده میدونن.
علاوه بر این، در حالی که هوش مصنوعی پیشرفتهای قابل توجهی در ترجمهی زبان داشته، اغلب فاقد ظرافت و درک فرهنگیای هست که مترجمان انسانی دارن و این منجر به ترجمههایی میشه که هم چشمگیرن و هم پر از اشکال.
پزشکی و کشف دارو
هوش مصنوعی میتونه به سرعت حجم عظیمی از دادههای پزشکی رو تحلیل کنه و ترکیبات دارویی بالقوه رو تولید کنه و فرآیند کشف دارو رو سرعت ببخشه. خیلی از پزشکان در حال حاضر از LLMها برای نوشتن یادداشتها و ارتباط با بیماران استفاده میکنن.
جنجال
اتکا به LLMها برای مقاصد پزشکی میتونه مشکلساز باشه. پزشکی به دقت نیاز داره و هرگونه خطا یا غفلت توسط هوش مصنوعی میتونه عواقب جدی داشته باشه.
پزشکی در حال حاضر هم سوگیریهایی داره که با استفاده از LLMها فقط ریشهدارتر میشن. مسائل مشابهی هم، همونطور که در ادامه بحث میشه، در مورد حریم خصوصی، کارایی و اخلاق وجود داره.
بازیسازی
خیلی از علاقهمندان به هوش مصنوعی در مورد استفاده از اون در بازیسازی هیجانزده هستن: اونها میگن هوش مصنوعی میتونه محیطهای بازی واقعگرایانه، شخصیتها و حتی کل داستان بازی رو تولید کنه و تجربهی بازی رو بهبود ببخشه. دیالوگهای NPCها (شخصیتهای غیرقابل بازی) میتونه با استفاده از این ابزارها بهتر بشه.
جنجال
بحثی در مورد هدفمندی در طراحی بازی وجود داره.
در حالی که هوش مصنوعی میتونه حجم زیادی محتوا تولید کنه، بعضیها معتقدن که فاقد طراحی عمدی و انسجام رواییای هست که طراحان انسانی به ارمغان میارن.
بازی Watch Dogs 2 شخصیتهای NPC برنامهریزیشده داشت که کمک چندانی به انسجام روایی کلی بازی نکرد.
بازاریابی و تبلیغات
هوش مصنوعی میتونه رفتار مصرفکننده رو تحلیل کنه و تبلیغات و محتوای تبلیغاتی شخصیسازیشده تولید کنه و کمپینهای بازاریابی رو مؤثرتر کنه.
LLMها از نوشتههای افراد دیگه زمینه دارن که اونها رو برای تولید داستانهای کاربر یا ایدههای برنامهریزیشدهی ظریفتر مفید میکنه. به جای پیشنهاد تلویزیون به کسی که تازه تلویزیون خریده، LLMها میتونن لوازم جانبیای رو پیشنهاد بدن که ممکنه اون شخص بخواد.
جنجال
استفاده از هوش مصنوعی در بازاریابی نگرانیهای مربوط به حریم خصوصی رو ایجاد میکنه. همچنین بحثی در مورد پیامدهای اخلاقی استفاده از هوش مصنوعی برای تأثیرگذاری بر رفتار مصرفکننده وجود داره.
مشکلات ادامهدار با LLMها
درک زمینهای و فهم گفتار انسان
- محدودیت: مدلهای هوش مصنوعی، از جمله GPT، اغلب با تعاملات ظریف انسانی مثل تشخیص کنایه، طنز یا دروغ مشکل دارن.
- مثال: در داستانهایی که یه شخصیت به شخصیتهای دیگه دروغ میگه، هوش مصنوعی ممکنه همیشه فریب زیربنایی رو درک نکنه و ممکنه اظهارات رو به صورت ظاهری تفسیر کنه.
تطبیق الگو
- محدودیت: مدلهای هوش مصنوعی، به خصوص مدلهایی مثل GPT، اساساً تطبیقدهندهی الگو هستن. اونها در تشخیص و تولید محتوا بر اساس الگوهایی که در دادههای آموزشیشون دیدن، عالی عمل میکنن. با این حال، عملکردشون ممکنه وقتی با موقعیتهای جدید یا انحراف از الگوهای تثبیتشده مواجه میشن، کاهش پیدا کنه.
- مثال: اگه یه اصطلاح عامیانهی جدید یا ارجاع فرهنگی بعد از آخرین بهروزرسانی آموزشی مدل ظهور کنه، ممکنه اون رو نشناسه یا نفهمه.
فقدان درک عقل سلیم
- محدودیت: در حالی که مدلهای هوش مصنوعی میتونن حجم عظیمی از اطلاعات رو ذخیره کنن، اغلب فاقد درک «عقل سلیم» از جهان هستن که منجر به خروجیهایی میشه که ممکنه از نظر فنی درست باشن ولی از نظر زمینهای بیمعنی باشن.
پتانسیل برای تقویت سوگیریها
- ملاحظات اخلاقی: مدلهای هوش مصنوعی از دادهها یاد میگیرن و اگه اون دادهها حاوی سوگیری باشن، مدل به احتمال زیاد اون سوگیریها رو بازتولید و حتی تقویت میکنه. این میتونه منجر به خروجیهایی بشه که تبعیضآمیز جنسیتی، نژادپرستانه یا به هر شکل دیگهای متعصبانه هستن.
چالشها در تولید ایدههای منحصربهفرد
- محدودیت: مدلهای هوش مصنوعی محتوا رو بر اساس الگوهایی که دیدن تولید میکنن. در حالی که میتونن این الگوها رو به روشهای جدیدی ترکیب کنن، مثل انسانها «اختراع» نمیکنن. «خلاقیت» اونها ترکیبی از ایدههای موجوده.
مسائل مربوط به حریم خصوصی دادهها، مالکیت معنوی و کنترل کیفیت:
- ملاحظات اخلاقی: استفاده از مدلهای هوش مصنوعی در برنامههایی که با دادههای حساس سروکار دارن، نگرانیهایی در مورد حریم خصوصی دادهها ایجاد میکنه. وقتی هوش مصنوعی محتوا تولید میکنه، سوالاتی در مورد اینکه چه کسی صاحب حقوق مالکیت معنوی است، به وجود میاد. تضمین کیفیت و دقت محتوای تولید شده توسط هوش مصنوعی هم یه چالش مهمه.
کد بد
- مدلهای هوش مصنوعی ممکنه موقع استفاده برای کارهای کدنویسی، کدی تولید کنن که از نظر سینتکس درسته ولی از نظر عملکردی معیوب یا ناامنه. من خودم مجبور شدم کدی رو که افراد با استفاده از LLMها تولید کردن و به سایتها اضافه کردن، اصلاح کنم. ظاهرش درست بود، ولی کار نمیکرد. حتی وقتی کار میکنه، LLMها انتظارات قدیمی از کد دارن و از توابعی مثل «document.write» استفاده میکنن که دیگه بهترین روش محسوب نمیشه.
نظرات جنجالی از یه مهندس MLOps و سئوکار تکنیکال
این بخش شامل چند تا نظر جنجالی منه در مورد LLMها و هوش مصنوعی مولد. راحت باشید باهام مخالفت کنید.
مهندسی پرامپت (برای رابطهای متنی مولد) یه چیز واقعی نیست
مدلهای مولد، به خصوص مدلهای زبانی بزرگ (LLM) مثل GPT-3 و جانشینانش، به خاطر تواناییشون در تولید متن منسجم و مرتبط با زمینه بر اساس پرامپتها، مورد تحسین قرار گرفتن.
به همین دلیل، و از اونجایی که این مدلها به «تب طلا»ی جدید تبدیل شدن، مردم شروع کردن به کسب درآمد از «مهندسی پرامپت» به عنوان یه مهارت. این میتونه به شکل دورههای آموزشی گرونقیمت یا شغلهای مهندسی پرامپت باشه.
با این حال، چند تا ملاحظهی مهم وجود داره:
LLMها به سرعت تغییر میکنن
همینطور که تکنولوژی تکامل پیدا میکنه و نسخههای جدید مدلها منتشر میشن، نحوهی پاسخدهیشون به پرامپتها میتونه تغییر کنه. چیزی که برای GPT-3 کار میکرد، ممکنه برای GPT-4 یا حتی یه نسخهی جدیدتر از GPT-3 به همون شکل کار نکنه.
این تکامل مداوم به این معنیه که مهندسی پرامپت میتونه یه هدف متحرک باشه و حفظ ثبات رو چالشبرانگیز کنه. پرامپتهایی که تو دی ماه کار میکنن، ممکنه تو اسفند ماه کار نکنن.
نتایج غیرقابل کنترل
در حالی که میتونین LLMها رو با پرامپتها هدایت کنین، هیچ تضمینی وجود نداره که همیشه خروجی مورد نظر رو تولید کنن. مثلاً، درخواست از یه LLM برای تولید یه مقالهی ۵۰۰ کلمهای ممکنه منجر به خروجیهایی با طولهای مختلف بشه چون LLMها نمیدونن عدد چیه.
به همین ترتیب، در حالی که میتونین اطلاعات واقعی بخواین، مدل ممکنه اطلاعات نادرست تولید کنه چون نمیتونه تفاوت بین اطلاعات دقیق و نادرست رو به خودی خود تشخیص بده.
استفاده از LLMها در کاربردهای غیرزبانی ایدهی بدیه
LLMها اساساً برای وظایف زبانی طراحی شدن. در حالی که میتونن برای اهداف دیگه تطبیق داده بشن، محدودیتهای ذاتی وجود داره:
مشکل با ایدههای جدید
LLMها روی دادههای موجود آموزش میبینن، که یعنی اساساً دارن چیزی که قبلاً دیدن رو بازگو و ترکیب میکنن. اونها به معنای واقعی کلمه «اختراع» نمیکنن.
وظایفی که به نوآوری واقعی یا تفکر خارج از چارچوب نیاز دارن، نباید از LLMها استفاده کنن.
میتونین مشکلی رو در این مورد ببینین وقتی که مردم از مدلهای GPT برای محتوای خبری استفاده میکنن – اگه یه چیز جدید پیش بیاد، برای LLMها سخته که باهاش کنار بیان.

مثلاً، یه سایتی که به نظر میرسه با LLMها محتوا تولید میکنه، یه مقالهی احتمالاً افتراآمیز در مورد مگان کرازبی منتشر کرد. کرازبی در زندگی واقعی موقع آرنج زدن به حریفانش گیر افتاده بود.
بدون اون زمینه، LLM یه داستان کاملاً متفاوت و بدون مدرک در مورد یه «اظهارنظر جنجالی» ساخته بود.
متنمحور
در هستهی خودشون، LLMها برای متن طراحی شدن. در حالی که میتونن برای وظایفی مثل تولید تصویر یا آهنگسازی تطبیق داده بشن، ممکنه به اندازهی مدلهایی که به طور خاص برای اون وظایف طراحی شدن، ماهر نباشن.
LLMها نمیدونن حقیقت چیه
اونها خروجیها رو بر اساس الگوهایی که در دادههای آموزشیشون باهاشون مواجه شدن، تولید میکنن. این یعنی نمیتونن حقایق رو تأیید کنن یا اطلاعات درست و غلط رو تشخیص بدن.
اگه در طول آموزش با اطلاعات غلط یا دادههای مغرضانه مواجه شده باشن، یا برای چیزی زمینه نداشته باشن، ممکنه اون نادرستیها رو در خروجیهاشون تکثیر کنن.
این به خصوص در کاربردهایی مثل تولید خبر یا تحقیقات آکادمیک، که در اونها دقت و حقیقت از اهمیت بالایی برخورداره، مشکلسازه.
اینطوری بهش فکر کنین: اگه یه LLM تا حالا با اسم «جیمی اسکرامبلز» مواجه نشده باشه ولی بدونه که این یه اسمه، پرامپتها برای نوشتن در موردش فقط بردارهای مرتبط رو پیدا میکنن و یه داستان ساختگی تحویل میدن.
طراحان همیشه از هنر تولید شده توسط هوش مصنوعی بهترن
هوش مصنوعی پیشرفتهای قابل توجهی در هنر داشته، از تولید نقاشی گرفته تا آهنگسازی. با این حال، یه تفاوت اساسی بین هنر ساختهی انسان و هنر تولید شده توسط هوش مصنوعی وجود داره:
قصد، احساس، حس و حال
هنر فقط در مورد محصول نهایی نیست، بلکه در مورد قصد و احساس پشت اونه.
یه هنرمند انسانی تجربیات، احساسات و دیدگاههای خودش رو به کارش میاره و به اون عمق و ظرافتی میده که برای هوش مصنوعی تکرار کردنش چالشبرانگیزه.
یه اثر هنری «بد» از یه انسان، عمق بیشتری نسبت به یه اثر هنری زیبا از یه پرامپت داره.
پاسخی بگذارید