
چگونه موتورهای جستجو به ChatGPT، Gemini و دیگران قدرت میدهند
مدلهای هوش مصنوعی برای ساختن جوابهاشون از نتایج جستجو استفاده میکنن. اینجا بهتون میگیم چطور مطمئن بشید که محتوای شما هم جزو چیزهایی باشه که جمینای، ChatGPT و بقیه نشون میدن.
چطوری میتونیم محتوای خودمون رو برای نمایش در هوش مصنوعی بهینه کنیم؟
چه ChatGPT باشه، چه Gemini گوگل، LLaMa متا، Grok، Claude مایکروسافت یا Perplexity AI، چالش اصلی اینه که بفهمیم این سیستمها چطوری به اسناد آنلاین دسترسی پیدا میکنن، اونها رو مصرف میکنن و ازشون جواب میسازن.
اگه بحثهای دیجیتال مارکتینگ و سئو رو تو شبکههای اجتماعی دنبال کرده باشید، حتماً میدونید که توصیههای مربوط به بهینهسازی برای هوش مصنوعی چقدر سریع محبوب شدن.
گوگل ترندز نشون میده که علاقه به این موضوع تو چند سال اخیر بهطور پیوسته در حال افزایش بوده و الان دیگه حسابی اوج گرفته.
به نظر میرسه که عبارت «سئو برای هوش مصنوعی» یا «AI SEO» داره تو این حوزه جا میفته و «بهینهسازی برای موتورهای مولد» یا «generative engine optimization» هم کمکم داره طرفدار پیدا میکنه.
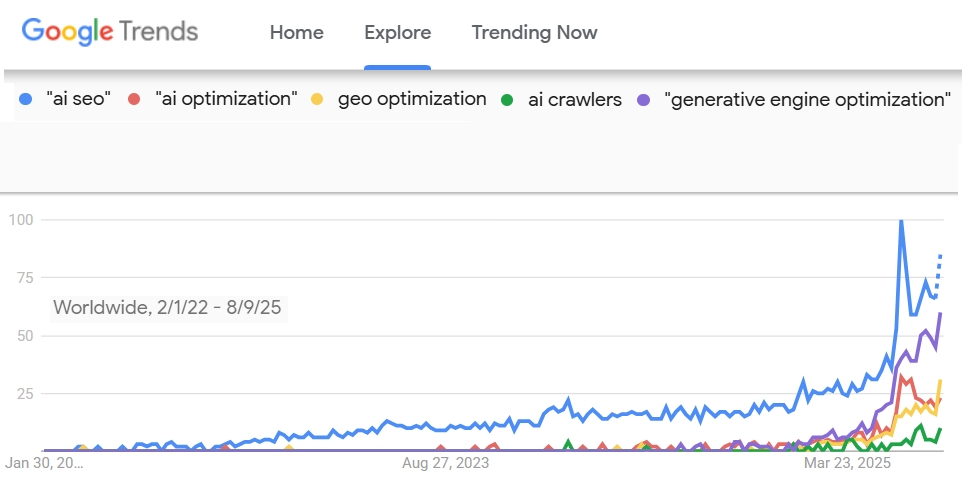
ظهور بهینهسازی برای هوش مصنوعی
وقتی هوش مصنوعی مولد یهو سر و کلهاش پیدا شد، خیلی زود شایعاتی در مورد مرگ سئو هم به راه افتاد.
اما این ادعاها از یه نگاه سادهانگارانه به نحوه کار هوش مصنوعی مولد میاد؛ نگاهی که بیشتر شبیه داستانهای علمی-تخیلیه.
توی اون داستانها، هوش مصنوعی یه موجود هوشمنده که خودش جوابها رو تولید میکنه یا کل دانش بشری رو بینقص جمعآوری میکنه.
اما در واقعیت، هوش مصنوعی با اطلاعات تغذیه میشه و یکی از اصلیترین منابع امروزش، وب و وبسایتهای تشکیلدهنده اونه.
به زبان ساده، سئو خوراک هوش مصنوعیه.
بررسی موردی: گوگل جمینای (Google Gemini)
بعضیها شاید بگن که بهینهسازی مخصوص هوش مصنوعی کار بیهوده یا تکراریه، چون تو بعضی موارد – مثل جمینای گوگل – هوش مصنوعی همین الان هم محتوا و جوابها رو از صفحاتی که رتبه بالایی برای یه جستجو دارن، استخراج میکنه.
سرگی برین، یکی از بنیانگذاران گوگل، این فرایند رو اینطوری توضیح میده که هوش مصنوعی هزار نتیجه برتر جستجو رو بازیابی میکنه و بعد جستجوهای تکمیلی انجام میده تا اونها رو دقیقتر و تحلیل کنه.
این دقیقاً روش کار بخشی از هوش مصنوعی گوگله.
مثلاً اگه من توی حالت هوش مصنوعی گوگل (AI Mode) دنبال اطلاعات جدیدی مثل «امیدبخشترین درمانهای آزمایشی فعلی برای ملانوما چیست؟» بگردم، سیستم چند مرحله رو طی میکنه:
اول، با یه جستجوی کلی، طیف وسیعی از اطلاعات رو جمعآوری میکنه.
بعد، منابع مرتبطتر و قابل اعتمادتر رو جدا میکنه تا یه جواب بسازه.
وقتی این عبارت رو به گوگل جمینای – یعنی همون هوش مصنوعی که نتایج حالت AI Mode گوگل رو تولید میکنه – میدیم، پشت صحنه به سرعت صدها سایت مرتبط با این جستجو رو شناسایی میکنه.
از جستجوهای کلی تا عبارتهای دقیقتر
جستجوهای کلی اولیه برای پیدا کردن طیف وسیعی از درمانهای بالقوه و مطالعات پزشکی، شامل این موارد بود:
- «درمانهای آزمایشی برای ملانوما»
- «درمانهای نوین ملانوما»
- «آزمایشهای بالینی امیدبخش ملانوما»
- «درمانهای آینده ملانوما»
اینها دقیقاً شبیه همون عبارتهای کلیدی نیستن که اگه خودمون هم میخواستیم در مورد «درمانهای آزمایشی امیدبخش برای ملانوما» تحقیق کنیم، بهشون میرسیدیم؟
دقیقاً همینه! حالت هوش مصنوعی گوگل در ابتدا عبارتهای جستجوی نزدیک به هم رو شناسایی میکنه.
بعد از اینکه این جستجوهای کلی و متعدد رو پیدا کرد، حالت هوش مصنوعی گوگل با هر کدوم از اونها یک جستجو انجام میده؛ درست مثل یه محقق انسانی که دنبال اطلاعات میگرده.
حالت هوش مصنوعی برای انجام این جستجوها از خودِ «جستجوی گوگل» استفاده میکنه.
صفحاتی که برای هر کدوم از این جستجوها رتبه بالایی میگیرن، تبدیل به منابع اطلاعاتی میشن که هوش مصنوعی قبل از جواب دادن به سؤال ما، اونها رو تحلیل میکنه.
جمینای از این نتایج کلی، جستجوهای دقیقتری رو بر اساس مسیرهای تحقیقی که از مرحله اول پیدا کرده بود، انجام داد.
این جستجوهای دقیقتر شامل این موارد بودن:
- «آزمایشات بالینی درمان TIL ملانوما»
- «درمان ملانوما با ویروس انکولیتیک»
- «BiTEs ملانوما»
- «واکسن mRNA ملانوما»
- «Lifileucel ملانوما»
- «T-VEC ملانوما»
- «Tebentafusp ملانوما یووهآل»
- «آزمایش بالینی V940 ملانوما»
هوش مصنوعی جستجوهای بیشتری که از دل تحقیق به دست میاد رو هم انجام میده و صفحات وب مرتبط با اونها رو هم بیرون میکشه.
این فرایند که خودشون بهش میگن «fanning out» یا «شاخهدار شدن»، درختی از جستجوهای مرتبط رو شناسایی میکنه تا تمام منابع اطلاعاتی لازم برای پاسخ به سؤالات رو پیدا کنه.
اعتبار و قابل اعتماد بودن در پاسخهای هوش مصنوعی
از بین تمام صفحاتی که بررسی میکنه، چه در حین فرایند جستجو و چه بعد از به دست آوردن تمام صفحات مرتبط، منابع معتبر و قابل اعتماد رو بر اساس معیارهای E-E-A-T شناسایی میکنه.
برای این نوع جستجو، گوگل احتمالاً اون رو در دسته مهم «پول شما یا زندگی شما» (YMYL) قرار میده.
بنابراین تعجبی نداره که جمینای از وبسایتهای زیر استفاده کرده:
- مؤسسات پزشکی معتبر (مثل دانشگاهها، مراکز سرطان)
- آژانسهای بهداشتی دولتی (مثل NIH، FDA)
- سازمانهای فعال در زمینه تحقیق و حمایت از بیماران ملانوما
- نشریات علمی معتبر و داوریشده
پس فعلاً برای حالت هوش مصنوعی گوگل، واقعاً نیازی نیست کار خاص و متفاوتی انجام بدید. فقط همون کارهایی رو که برای دیده شدن تو نتایج جستجوی گوگل انجام میدادید، ادامه بدید.
سئو برای گوگل، به طور خودکار بهینهسازی برای هوش مصنوعی گوگل هم هست.
(البته چندتا نکته وجود داره که در ادامه توضیح میدم.)
مدلهای مختلف هوش مصنوعی، دادههایشان را از کجا میآورند؟
اما بقیه مدلهای هوش مصنوعی چطور؟ اونها دادههای وب رو از کجا به دست میارن؟
بررسی پلتفرمها نشون میده که برای بهینهسازی برای هوش مصنوعی چه کارهایی لازمه و اطلاعات ما باید کجاها دیده بشه تا به دستشون برسه. مهمه که بدونیم دو تا اتفاق متفاوت در جریانه:
- دادههای آموزشی برای مدلهای زبان بزرگ (LLM): این دادهها معمولاً با نتایج جستجوی زنده و بهروز وب فرق دارن، هرچند که مشخصاً همپوشانیهایی هم وجود داره. خیلی از مدلهای اصلی هوش مصنوعی با دادههای به دست اومده از Common Crawl آموزش دیدن؛ یک منبع رایگان از دادههای وب که هضم شده و در فرمتی ذخیره شده که دسترسی، مصرف و استفاده از اون برای هوش مصنوعی نسبتاً آسونه.
- منابع اطلاعات زنده و بهروز وب: اینها لزوماً با دادههای آموزشی یکی نیستن. مجموعه دادههای آموزشی ممکنه مال چند سال پیش باشن، در حالی که دادههای وب امروزی شامل اطلاعاتی درباره سؤالاتی مثل «تخفیفهای فعلی رستوران اکمی چیه؟» یا «بلیطهای کنسرت تیلور سوئیفت فروش رفته؟» میشن.
افشاگری اخیر نشون میده در حالی که بعضی از مدلهای هوش مصنوعی نتونستن مجوز استفاده از نتایج جستجوی گوگل رو بگیرن، به نظر میرسه با استفاده از SerpApi (شرکتی که در زمینه استخراج نتایج جستجوی گوگل تخصص داره) این محدودیت رو دور زدن.
گزارش شده که هم OpenAI و هم Perplexity از طریق این دسترسی غیرمستقیم، استفاده محدودی از نتایج گوگل دارن.
| هوش مصنوعی | منبع اصلی دادههای وب | سایر منابع داده |
| Google Gemini / AI Mode | جستجوی گوگل | کتابهای دیجیتالی، ویدیوهای یوتیوب، Common Crawl |
| ChatGPT | جستجوی بینگ | Common Crawl، جستجوی گوگل از طریق SerpApi (محدود به دادههای روز مثل اخبار، ورزش و بازارها) |
| Meta LLaMa | جستجوی گوگل | محتوای پستهای عمومی فیسبوک و اینستاگرام، Common Crawl |
| Microsoft Copilot | جستجوی بینگ | Common Crawl |
| Perplexity | PerplexityBot | جستجوی گوگل از طریق SerpApi |
| Grok | Grok WebSearch | پستهای پلتفرم X (توییتر سابق) |
| Claude | جستجوی Brave | Common Crawl |
چرا سئو در عصر هوش مصنوعی هنوز مهمه؟
همونطور که میبینید، خیلی از چتباتهای هوش مصنوعی و سیستمهای جستجوی برتر، احتمالاً محتوایی رو منعکس میکنن که همین الان هم در گوگل و بینگ رتبه خوبی داره.
این موضوع این فرضیه رو تأیید میکنه که برای دیده شدن محتوا در حالت هوش مصنوعی گوگل، ChatGPT، LLaMa متا و مایکروسافت Copilot، هنوز هم باید به همون روشهای جاافتاده سئو که سالهاست برای بهینهسازی برای این موتورهای جستجو استفاده میشه، تکیه کرد.
کارمندان گوگل هم این موضوع رو تأیید کردن و بر همون رویکردهای کلی که در سالهای اخیر توصیه کردن، تأکید داشتن:
- روی محتوای منحصربهفرد و ارزشمند برای آدمها تمرکز کنید.
- تجربه کاربری عالی برای صفحه فراهم کنید.
- مطمئن بشید که ربات گوگل (Googlebot) میتونه به محتوای شما دسترسی داشته باشه.
- نمایش محتوا رو با کنترلهای پیشنمایش (nosnippet و max-snippet) مدیریت کنید.
- مطمئن بشید که دادههای ساختاریافته (structured data) با محتوای قابل مشاهده صفحه مطابقت داره.
- برای موفقیت چندرسانهای، فراتر از متن برید.
- ارزش کامل بازدیدهای کاربرانتون رو درک کنید.
- همگام با کاربرانتون تکامل پیدا کنید.
برای جستجوهای YMYL، وبسایت شما باید حس اعتماد، اعتبار و تخصص در اون موضوع رو هم منتقل کنه.
در بهینهسازی برای هوش مصنوعی، روی دادههای ساختاریافته هم تأکید شده.
مقاله گوگل با عنوان «برترین راهها برای اطمینان از عملکرد خوب محتوای شما در تجربههای هوش مصنوعی گوگل در جستجو» دوباره تأکید میکنه که دادههای ساختاریافته باید با محتوای قابل مشاهده مطابقت داشته باشن؛ چیزی که از قدیم یک اصل مهم بوده.
نکته قابل توجه، تأکید اضافهشون روی اعتبارسنجیه. پیام واضح اینه که از ابزارهای Rich Results Test و Schema Markup Validator گوگل استفاده کنید تا مطمئن بشید که کدهای نشانهگذاری (markup) رو به درستی در صفحاتتون پیادهسازی کردید.
پیچیدگیها و نکات تکمیلی
بسته به اینکه چی رو میخواید بهینه کنید، پیچیدگیهای بیشتری هم وجود داره.
همونطور که مثال جستجوی درمان ملانوما نشون داد، ممکنه لازم باشه برای دیده شدن در جستجوهای زیادی بهینهسازی کنید، نه فقط یکی.
سیستمهای هوش مصنوعی دیگه، مثل جمینای، هم احتمالاً موقع ساختن جواب، به جستجوهای نزدیک و مرتبط «شاخه» میزنن. پس بهینهسازی ممکنه به جای تمرکز روی یک عبارت کلیدی اصلی، به هدفگیری چندین جستجوی مختلف نیاز داشته باشه.
این موضوع برای ناشران یک دوراهی ایجاد میکنه، چون آپدیتهای قبلی گوگل، صفحاتی که محتوای ضعیفی داشتن و برای هدفگیری تنوع زیادی از کلمات کلیدی ساخته شده بودن رو جریمه میکرد.
هرچند که این موضوع رو به طور کامل تحقیق نکردم، اما دلیلی وجود داره که فکر کنیم استراتژیهای محتوایی گسترده که تنوع زیادی از عبارتهای مشابه رو پوشش میدن، ممکنه توسط هوش مصنوعی پاداش بگیرن، اما به رتبهبندی کلمات کلیدی ارگانیک آسیب بزنن.
اگه به چنین رویکردی فکر میکنید، باید برای هر تنوع از کلمات کلیدی، محتوای خاص، پیچیده و غنی تولید کنید، نه محتوایی که ارزون و با ابزارهای اتوماسیون یا هوش مصنوعی مولد ساخته شده باشه.
وقتی بحث مدیریت اعتبار آنلاین (online reputation management) پیش میاد، مطالب منفی در نتایج بالای جستجو میتونن در پاسخهای هوش مصنوعی برجسته و حتی تقویت بشن.
این اتفاق مخصوصاً زمانی میفته که چندین منبع، ادعاهای یکسانی رو تکرار کنن و هوش مصنوعی ممکنه اونها رو بدون در نظر گرفتن زمینه و جزئیات مهم ارائه بده.
برای مثال:
- یک مقاله خبری میگه: «جان اسمیت توسط جین جونز به سوء رفتار متهم شد و بعداً از او به خاطر تهمت شکایت کرد و در دادگاه پیروز شد.»
- هوش مصنوعی ممکنه این رو اینطور خلاصه کنه: «برخی منابع گفتهاند که جان اسمیت ممکن است در سوء رفتار مقصر باشد.»
برای مدیریت اعتبار، این یعنی باید چندین قطعه محتوا در دامنههای مختلف منتشر کنید تا مطالب آسیبزا رو به حاشیه ببرید. این کار حتی ممکنه توسط هوش مصنوعیهایی که نتایج برتر رو خلاصه میکنن، پاداش هم بگیره.
ابهامات و ناشناختههای جدید
در حالی که تکنیکها و عناصر بهینهسازی برای گوگل و بینگ کاملاً جا افتاده هستن، بهینهسازی برای بعضی از موتورهای جستجوی دیگه که تو جدول بالا اومدن، چندان مستند نیست.
PerplexityBot
هیچ راهنمای شناختهشدهای برای بهینهسازی برای PerplexityBot وجود نداره.
میشه فرض کرد که داشتن یک سئوی تکنیکال قوی برای وبسایت، به خزیدن (crawl) و جذب محتوای اون توسط PerplexityBot کمک میکنه.
بهینهسازی فراتر از این، هنوز مشخص نیست.
Grok WebSearch
در حال حاضر هیچ روش شناختهشدهای برای بهینهسازی برای Grok WebSearch وجود نداره.
اما اگه میخواید یک وبسایت یا صفحه وب جدید توسط Grok ایندکس بشه، احتمالاً باید URLها رو در پلتفرم X (توییتر سابق) پست کنید تا به رباتهای اونها سیگنال بدید که محتوا رو بخزنن و ایندکس کنن.
Brave Search
این موتور جستجو روشهای بهینهسازی منتشر شدهای نداره، اما اعلام کرده که بیشتر کشف محتواش از طریق فعالیتهای وب کاربران که توسط مرورگر Brave شناسایی میشه، انجام میشه.
نصب کردن Brave میتونه راهی برای اضافه شدن جدیدترین محتوای شما به موتور جستجوی Brave باشه.
برای اینکه فعالیت بازدید شما از وبسایتها برای ایندکس شدن به اونها ارسال بشه، باید گزینه اشتراکگذاری دادههای مرورگر با Brave رو فعال کنید.
این روش یه کم محدود و قدیمی به نظر میرسه، شبیه ثبت سایت تو موتورهای جستجوی ۲۰ سال پیش.
نکات کاربردی برای کارشناسان بازاریابی جستجو
ممکنه در آینده راهنماییهای بیشتری از طرف ارائهدهندگان هوش مصنوعی مولد منتشر بشه، چون شرکتها و صاحبان سایتها مدام میپرسن که چطور میتونن محتواشون رو در هوش مصنوعی نمایش بدن – و چرا ممکنه محتواشون نمایش داده نشه.
این حرف قبلاً هم گفته شده، اما ارزش تکرار رو داره که استراتژیهای بهینهسازی و بازاریابی محتوا نباید صرفاً با محتوای تولید شده توسط هوش مصنوعی پیش بره.
هر مدل هوش مصنوعی مولد، به نوعی علاقهمنده که از محتوای بازتولید شده دوری کنه، چون احتمال انتشار خطا و افت کیفیت در این حالت زیاده.
موقع استفاده از هوش مصنوعی در بازاریابی و تولید محتوا، توصیه بلندمدت اینه که عمیقاً روی کیفیت تمرکز کنید و از هوش مصنوعی با احتیاط و در کنار نظارت و کنترل کیفیت انسانی استفاده کنید.
در غیر این صورت، تولید حجم زیادی از محتوای ارزون با هوش مصنوعی، احتمالاً یک تاکتیک کوتاهمدت و ناپایداره؛ همونطور که خیلی از استراتژیهای سئوی کلاه سیاه قبلاً این رو نشون دادن.
سئو، سوخت هوش مصنوعی است
خیالتون راحت باشه که «سئو نمرده».
هر پلتفرم هوش مصنوعی هنوز هم برای ارائه اطلاعات، باید بین تریلیونها صفحه وب و محتوای آنلاین دیگه جستجو کنه.
تکنیکهای امتحان پسداده سئو در آینده قابل پیشبینی همچنان ضروری باقی خواهند موند.
حتی قبل از انقلاب هوش مصنوعی مولد، گوگل و بقیه موتورهای جستجو در حال ادغام فرایندهای یادگیری ماشین در الگوریتمهای رتبهبندی خودشون بودن.
یادگیری ماشین احتمالاً به تغییر و تحول عملکردهای جستجوی کلمات کلیدی ادامه خواهد داد.
همین الان هم احتمال زیادی وجود داره که گوگل و بقیه از مدلهایی استفاده کنن که روشهای رتبهبندی و وزندهی فاکتورها رو به صورت سفارشی برای هر موضوع و جستجو ایجاد میکنن؛ همونطور که من در کارهای قبلیام درباره روشهای امتیازدهی کیفی گوگل توضیح دادم.
سئو، سوخت چتباتهای هوش مصنوعیه.
هر کدوم از اونها به محتوایی که در بین تریلیونها صفحه وب پیدا میشه نیاز دارن و موتورهای جستجو پشت صحنه کار میکنن تا به پیدا کردن و سازماندهی اون کمک کنن.
برای اینکه صفحات وب قابل پیدا شدن باشن – و به اندازه کافی در موتورهای جستجویی که هوش مصنوعی رو تغذیه میکنن رتبه خوبی بگیرن – سئو همچنان حلقه اتصال ضروری بین محتوای وب و اطلاعاتی است که در نهایت به دست کاربران میرسه.
پاسخی بگذارید