
دادههای ساختاریافته، سوخت هوش مصنوعی برای دیده شدن بیشتر شما
بررسیهای اولیه نشون میده که استفاده از دادههای ساختاریافته (structured data)، دیده شدن و پایداری شما رو در اسنیپتهای تولیدشده توسط هوش مصنوعی افزایش میده.
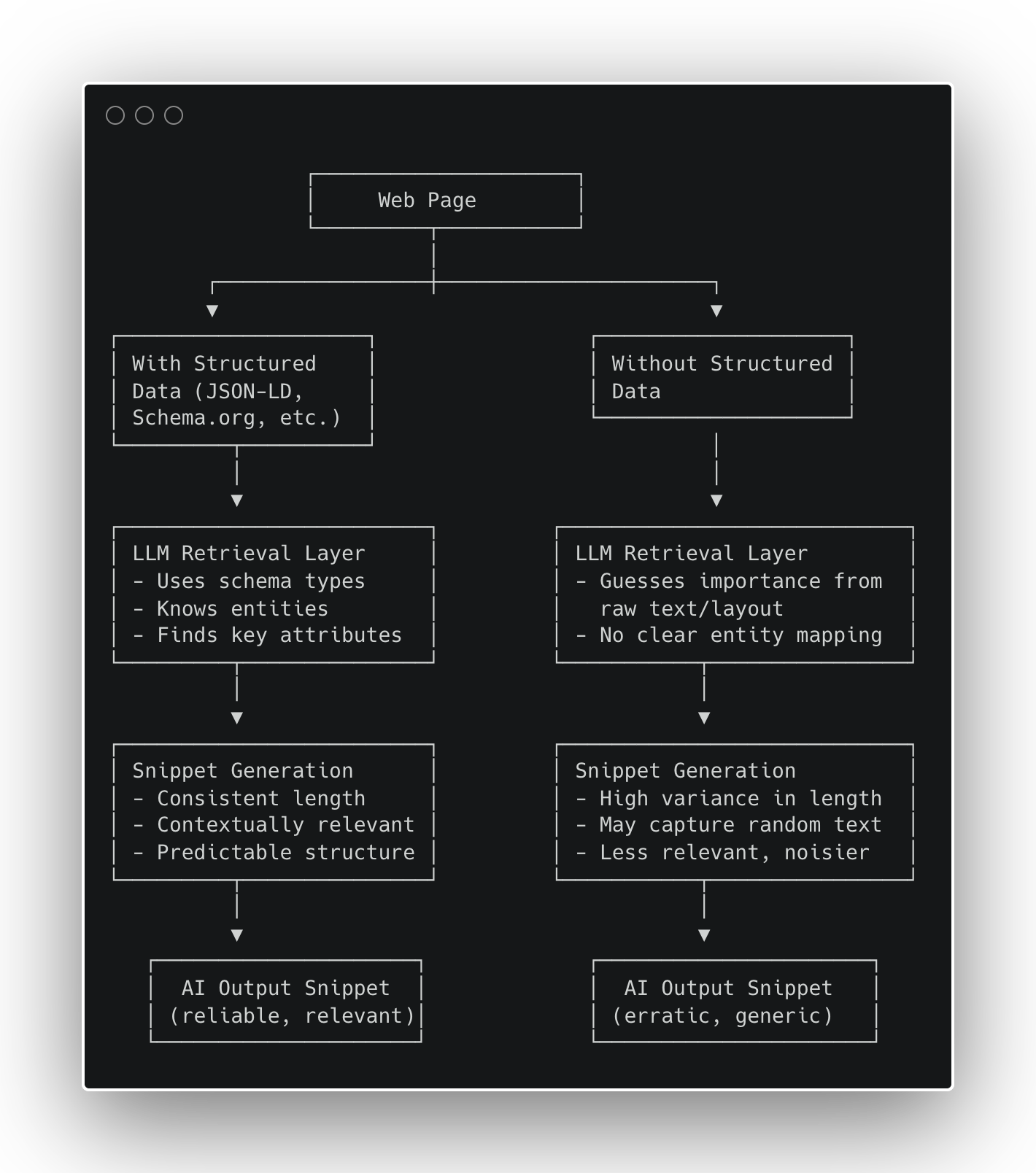
وقتی هوش مصنوعیهای مکالمهمحور مثل ChatGPT، Perplexity یا Google AI Mode اسنیپتها یا خلاصههایی رو به عنوان جواب تولید میکنن، اونا رو از صفر نمینویسن؛ بلکه محتوای صفحات وب رو انتخاب، فشرده و بازچینی میکنن. اگه محتوای شما سئوفرندلی و قابل ایندکس نباشه، اصلاً وارد جستجوی مولد (generative search) نمیشه. جستجو، اونطوری که ما میشناختیمش، حالا دیگه تابعی از هوش مصنوعیه.
اما اگه صفحهی شما اطلاعاتش رو در یک فرمت قابل خوندن برای ماشین «ارائه» نکنه چی؟ اینجاست که پای دادههای ساختاریافته به میون میاد؛ نه فقط به عنوان یه تکنیک سئو، بلکه به عنوان یه چهارچوب محکم تا هوش مصنوعی بتونه با اطمینان «حقایق درست» رو انتخاب کنه. اخیراً سردرگمیهایی تو جامعه ما در این مورد به وجود اومده، و من تو این مقاله میخوام:
- آزمایشهای کنترلشده روی ۹۷ صفحه وب رو با هم مرور کنیم تا ببینیم دادههای ساختاریافته چطور ثبات و ارتباط متنی اسنیپتها رو بهتر میکنه،
- و این نتایج رو در چهارچوب معنایی (semantic) خودمون ترسیم کنیم.
خیلیها تو ماههای اخیر از من پرسیدن که آیا LLMها از دادههای ساختاریافته استفاده میکنن یا نه، و من بارها و بارها تکرار کردم که یک LLM از دادههای ساختاریافته استفاده نمیکنه، چون دسترسی مستقیمی به وب جهانی نداره. یک LLM از ابزارهایی برای جستجوی وب و واکشی (fetch) صفحات وب استفاده میکنه. و ابزارهای اون – در بیشتر موارد – از ایندکس کردن دادههای ساختاریافته سود زیادی میبرن.

طبق نتایج اولیهی ما، دادههای ساختاریافته ثبات اسنیپت رو افزایش میده و ارتباط متنی رو در GPT-5 بهبود میبخشه. همچنین به نظر میرسه که محدودهی مؤثر «سهمیه کلمات» (wordlim envelope) رو هم گسترش میده. این سهمیه کلمات، یه دستورالعمل پنهان در GPT-5 هست که تصمیم میگیره محتوای شما چند کلمه از پاسخ رو به خودش اختصاص بده. میتونید اون رو به عنوان یه سهمیه برای دیده شدن محتوای شما در هوش مصنوعی تصور کنید که هرچقدر محتواتون غنیتر و ساختاریافتهتر باشه، این سهمیه هم بیشتر میشه.
چرا این موضوع الان مهمه؟
- محدودیتهای سهمیه کلمات (wordlim): سیستمهای هوش مصنوعی با بودجههای محدودی از توکن/کاراکتر کار میکنن. ابهام این بودجه رو هدر میده؛ اما حقایقِ ساختاریافته و مشخص، در مصرف اون صرفهجویی میکنن.
- رفع ابهام و قابل اتکا کردن اطلاعات: Schema.org فضای جستجوی مدل رو محدودتر میکنه (مثلاً بهش میگه «این یک دستور پخت/محصول/مقاله است») و این باعث میشه انتخاب اطلاعات با اطمینان بیشتری انجام بشه.
- گرافهای دانش (KG): اسکیما (Schema) اغلب گرافهای دانشی رو تغذیه میکنه که سیستمهای هوش مصنوعی برای پیدا کردن حقایق به اونا مراجعه میکنن. این مثل یه پل بین صفحات وب و استدلال عاملهای هوشمنده.
فرضیه شخصی من اینه که ما باید با دادههای ساختاریافته مثل لایه دستورالعمل برای هوش مصنوعی رفتار کنیم. داده ساختاریافته باعث «رتبه گرفتن شما» نمیشه، بلکه چیزهایی که هوش مصنوعی میتونه درباره شما بگه رو تثبیت میکنه.
طراحی آزمایش (بررسی ۹۷ آدرس)
با اینکه حجم نمونه کوچک بود، میخواستم ببینم لایه بازیابی (retrieval) چتجیپیتی وقتی از طریق رابط کاربری خودش (و نه از طریق API) استفاده میشه، واقعاً چطور کار میکنه. برای این کار، از GPT-5 خواستم دستهای از آدرسها رو از وبسایتهای مختلف جستجو و باز کنه و پاسخهای خام رو برگردونه.
شما میتونید با یه متا-پرامپت (meta-prompt) ساده، از GPT-5 (یا هر سیستم هوش مصنوعی دیگهای) بخواید که خروجی کلمه به کلمه ابزارهای داخلیش رو بهتون نشون بده. بعد از جمعآوری پاسخهای جستجو و واکشی برای هر آدرس، من یک ورکفلوی Agent WordLift [توضیح: این ایجنت سئوی هوش مصنوعی ماست] رو اجرا کردم تا هر صفحه رو تحلیل کنه و ببینه آیا داده ساختاریافته داره یا نه، و اگه داشت، نوع اسکیمای مشخصشده رو شناسایی کنه.
این دو مرحله یک دیتاست از ۹۷ آدرس تولید کرد که با فیلدهای کلیدی زیر برچسبگذاری شده بود:
- has_sd ← وجود داده ساختاریافته (True/False).
- schema_classes ← نوع اسکیمای شناساییشده (مثلاً Recipe، Product، Article).
- search_raw ← اسنیپت خام جستجو، یعنی چیزی که ابزار جستجوی هوش مصنوعی نشون داده.
- open_raw ← خلاصه واکشیشده یا مرور کلی ساختاری صفحه توسط GPT-5.
بعدش، با استفاده از رویکرد «LLM به عنوان قاضی» (LLM-as-a-Judge) که با Gemini 2.5 Pro کار میکرد، دیتاست رو تحلیل کردم تا سه معیار اصلی رو استخراج کنم:
- ثبات (Consistency): توزیع طول اسنیپتهای search_raw (با نمودار جعبهای).
- ارتباط متنی (Contextual relevance): پوشش کلمات کلیدی و فیلدها در open_raw بر اساس نوع صفحه (دستور پخت، فروشگاهی، مقاله).
- امتیاز کیفیت (Quality score): یه شاخص محافظهکارانه بین ۰ تا ۱ که حضور کلمات کلیدی، نشانههای اولیه NER (برای سایتهای فروشگاهی) و بازتاب اسکیما در خروجی جستجو رو با هم ترکیب میکنه.
سهمیه پنهان: رمزگشایی از «wordlim»
حین انجام این تستها، متوجه یه الگوی ظریف دیگه شدم؛ الگویی که شاید توضیح بده چرا دادههای ساختاریافته به اسنیپتهای باثباتتر و کاملتری منجر میشه. داخل خط لوله بازیابی اطلاعات GPT-5، یه دستورالعمل داخلی وجود داره که به طور غیررسمی بهش میگن wordlim: یک سهمیه پویا که مشخص میکنه چه مقدار از متن یک صفحه وب میتونه در پاسخ نهایی تولیدشده قرار بگیره.
در نگاه اول، مثل یه محدودیت تعداد کلمه عمل میکنه، اما در واقع تطبیقپذیره. هرچقدر محتوای یک صفحه غنیتر و ساختاریافتهتر باشه، سهم بیشتری در پنجرهی تولید محتوای مدل به دست میاره.
بر اساس مشاهدات مداوم من:
- محتوای بدون ساختار (مثلاً یک پست وبلاگ استاندارد) معمولاً حدود ۲۰۰ کلمه سهمیه میگیره.
- محتوای ساختاریافته (مثلاً مارکآپ محصول، فیدها) تا حدود ۵۰۰ کلمه هم میرسه.
- منابع متراکم و معتبر (APIها، مقالات تحقیقاتی) میتونن به بیش از ۱۰۰۰ کلمه هم برسن.
این محدودیت بیدلیل نیست و به سیستمهای هوش مصنوعی کمک میکنه تا:
- به جای کپی کردن، به ترکیب اطلاعات از منابع مختلف تشویق بشن.
- از مشکلات مربوط به حق کپیرایت جلوگیری کنن.
- پاسخها رو مختصر و خوانا نگه دارن.
با این حال، این موضوع یه مرز جدید در سئو هم ایجاد میکنه: دادههای ساختاریافته شما به طور مؤثری سهمیه دیده شدن شما رو افزایش میده. اگه دادههاتون ساختاریافته نباشه، در حداقل سهمیه گیر میکنید؛ اما اگه ساختاریافته باشه، به هوش مصنوعی اعتماد و فضای بیشتری میدید تا برند شما رو نمایش بده.
با اینکه دیتاست ما هنوز اونقدر بزرگ نیست که از نظر آماری در همه حوزهها معنادار باشه، الگوهای اولیه کاملاً واضح و کاربردی هستن.
نتایج
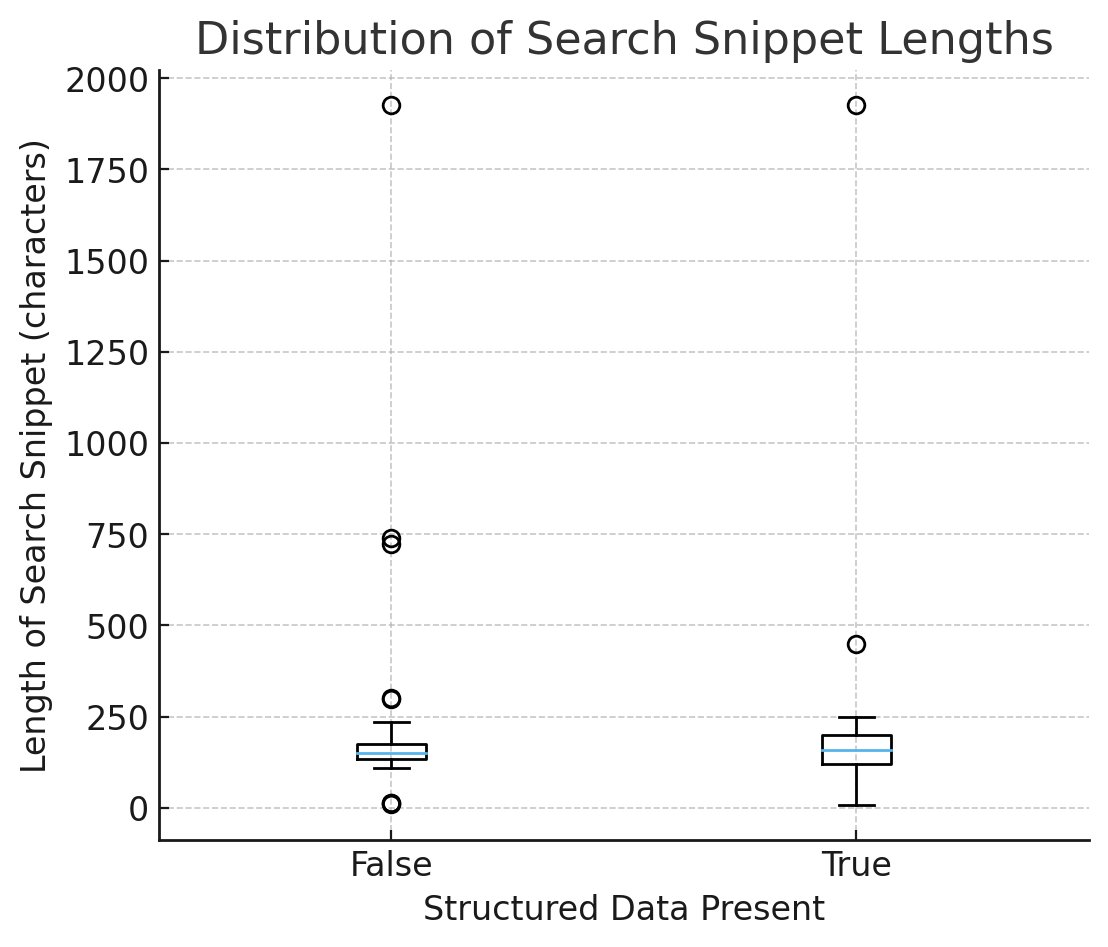 شکل ۲ – توزیع طول اسنیپتهای جستجو
شکل ۲ – توزیع طول اسنیپتهای جستجو
۱) ثبات: اسنیپتها با وجود اسکیما قابل پیشبینیتر میشن
در نمودار جعبهای طول اسنیپتهای جستجو (مقایسه حالت با و بدون داده ساختاریافته):
- میانهها (Medians) مشابه هستن ← اسکیما به طور متوسط باعث طولانیتر یا کوتاهتر شدن اسنیپتها نمیشه.
- پراکندگی (IQR و whiskers) وقتی `has_sd = True` هست، کمتره ← خروجی کمتر نامنظم و خلاصهها قابل پیشبینیتر هستن.
تفسیر: دادههای ساختاریافته طول اسنیپت رو زیاد نمیکنه؛ بلکه عدم قطعیت رو کاهش میده. مدلهای هوش مصنوعی به جای حدس زدن از روی کدهای HTML نامشخص، به سراغ حقایق ساختاریافته و امن میرن.
۲) ارتباط متنی: اسکیما استخراج اطلاعات رو هدایت میکنه
- دستور پخت (Recipes): با اسکیمای `Recipe`، خلاصههای واکشیشده به احتمال خیلی بیشتری شامل مواد اولیه و مراحل پخت میشن. یک بهبود واضح و قابل اندازهگیری.
- فروشگاه اینترنتی (Ecommerce): ابزار جستجو اغلب فیلدهای JSON-LD (مثل `aggregateRating`، `offer`، `brand`) رو بازتاب میده، که نشون میده اسکیما خونده شده و به سطح بالاتر آورده شده. خلاصههای واکشیشده بیشتر به سمت نام دقیق محصول میرن تا عبارات کلی مثل «قیمت»، اما با وجود اسکیما، هویت محصول قویتر تثبیت میشه.
- مقالات (Articles): بهبودهای کوچک اما قابل مشاهدهای وجود داره (احتمال نمایش نویسنده/تاریخ/عنوان بیشتر میشه).
۳) امتیاز کیفیت (همه صفحات)
میانگین امتیاز ۰ تا ۱ در تمام صفحات:
- بدون اسکیما ← حدود ۰.۰۰
- با اسکیما ← بهبود مثبت، که بیشتر به خاطر دستورهای پخت و برخی مقالات بوده.
حتی در مواردی که میانگینها شبیه به هم به نظر میرسن، با وجود اسکیما واریانس (پراکندگی) به شدت کاهش پیدا میکنه. در دنیای هوش مصنوعی که با محدودیتهایی مثل سهمیه کلمات (wordlim) و هزینههای بازیابی اطلاعات روبروئیم، واریانس پایین یک مزیت رقابتیه.
فراتر از ثبات: دادههای غنیتر، سهمیه کلمات (wordlim) را افزایش میدهند (یک سیگنال اولیه)
با اینکه دیتاست هنوز برای آزمونهای معناداری آماری به اندازه کافی بزرگ نیست، ما این الگوی در حال ظهور رو مشاهده کردیم:
صفحاتی که دادههای ساختاریافته غنیتر و چند-موجودیتی (multi-entity) دارن، معمولاً قبل از بریده شدن، اسنیپتهای کمی طولانیتر و متراکمتری تولید میکنن.
فرضیه: حقایق ساختاریافته و به هم پیوسته (مثلاً `Product + Offer + Brand + AggregateRating` یا `Article + author + datePublished`) به مدلها کمک میکنه تا اطلاعات باارزشتر رو اولویتبندی و فشرده کنن – که در عمل، بودجه توکن قابل استفاده برای اون صفحه رو افزایش میده.
صفحاتی که اسکیما ندارن، اغلب به دلیل عدم قطعیت در مورد میزان ارتباط، زودتر از موعد بریده میشن.
قدم بعدی: ما رابطه بین غنای معنایی (تعداد موجودیتها/ویژگیهای متمایز Schema.org) و طول مؤثر اسنیپت رو اندازهگیری خواهیم کرد. اگه این موضوع تأیید بشه، یعنی دادههای ساختاریافته نه تنها اسنیپتها رو تثبیت میکنن، بلکه بازده اطلاعاتی رو هم تحت محدودیتهای کلمات ثابت، افزایش میدن.
از اسکیما تا استراتژی: راهنمای عملی
ما سایتها رو به این شکل ساختاربندی میکنیم:
- گراف موجودیت (Entity Graph) (شامل Schema/GS1/Articles/…): محصولات، پیشنهادات، دستهبندیها، سازگاری، مکانها، سیاستها؛
- گراف واژگانی (Lexical Graph): کپیهای بخشبندیشده (دستورالعملهای نگهداری، راهنمای سایز، پرسشهای متداول) که به موجودیتها لینک شدن.
چرا این روش کار میکنه: لایه موجودیت (entity) یک چهارچوب امن به هوش مصنوعی میده؛ لایه واژگانی (lexical) هم شواهد قابل استفاده و قابل نقل قول رو فراهم میکنه. این دو با هم، دقت رو تحت محدودیتهای سهمیه کلمات (wordlim) بالا میبرن.
در ادامه، توضیح میدیم که چطور این یافتهها رو به یک راهنمای عملی و تکرارپذیر سئو برای برندهایی که درگیر محدودیتهای کشف توسط هوش مصنوعی هستن، تبدیل میکنیم.
- برای قالبهای اصلی JSON-LD پیادهسازی کنید
- دستور پخت ← `Recipe` (مواد اولیه، دستورالعملها، تعداد، زمان).
- محصولات ← `Product + Offer` (برند، GTIN/SKU، قیمت، موجودی، امتیازها).
- مقالات ← `Article/NewsArticle` (عنوان، نویسنده، `datePublished`).
- موجودیت و واژگان را یکپارچه کنید
مشخصات فنی، پرسشهای متداول و متن سیاستها رو به صورت بخشبندیشده و متصل به موجودیت نگه دارید. - سطح اسنیپت را مستحکم کنید
حقایق باید در HTML قابل مشاهده و JSON-LD یکسان باشن؛ حقایق حیاتی رو در بالای صفحه (above the fold) و به صورت پایدار نگه دارید. - اندازهگیری کنید
به جای میانگین، واریانس (پراکندگی) را رصد کنید. پوشش کلمات کلیدی/فیلدها را در خلاصههای ماشینی برای هر قالب سایت محک بزنید.
نتیجهگیری
دادههای ساختاریافته اندازه متوسط اسنیپتهای هوش مصنوعی رو تغییر نمیده؛ بلکه قطعیت اونا رو تغییر میده. خلاصهها رو تثبیت میکنه و محتوای داخلشون رو شکل میده. در GPT-5، به خصوص تحت شرایط سختگیرانه سهمیه کلمات (wordlim)، این قابلیت اطمینان به پاسخهای باکیفیتتر، توهمات (hallucinations) کمتر و دیده شدن بیشتر برند در نتایج تولیدشده توسط هوش مصنوعی منجر میشه.
برای سئوکارها و تیمهای محصول، پیام روشنه: با دادههای ساختاریافته مثل یک زیرساخت اصلی رفتار کنید. اگه قالبهای سایت شما هنوز از نظر معنایی در HTML ضعیف هستن، مستقیم سراغ JSON-LD نرید: اول پایهها رو درست کنید. با تمیز کردن مارکآپ (markup) شروع کنید، بعد دادههای ساختاریافته رو به عنوان یک لایه روی اون اضافه کنید تا دقت معنایی و قابلیت کشف طولانیمدت رو بسازید. در دنیای جستجوی هوش مصنوعی، معناشناسی (semantics) میدان رقابت جدید شماست.
پاسخی بگذارید