تجربه جستجوی مولد چگونه کار میکند و چرا تولید افزوده با بازیابی، آینده ماست؟
میزان تهدید بالقوه SGE برای ترافیک سایتتون رو بسنجید. با تغییرات احتمالی در منحنی تقاضای جستجو و مدل نرخ کلیک (CTR) آشنا بشید.
دنیای جستجو، با اون شکلی که ما میشناختیم، برای همیشه با ظهور هوش مصنوعی مولد زیر و رو شده.
بهبودهای سریع در «تجربه تولیدی جستجوی گوگل» (SGE) و اظهارات اخیر ساندار پیچای درباره آینده اون، نشون میده که این تکنولوژی اومده که بمونه.
این تغییر بزرگ در نحوه بررسی و نمایش اطلاعات، عملکرد کانال جستجو (چه پولی و چه ارگانیک) و تمام کسبوکارهایی که از محتواشون درآمدزایی میکنن رو تهدید میکنه. این مطلب، بحثی درباره ماهیت این تهدیده.
موقعی که مشغول نوشتن کتاب «علم سئو» بودم، همچنان داشتم عمیقتر به تکنولوژی پشت صحنه جستجو فکر میکردم. فصل مشترک هوش مصنوعی مولد و بازیابی اطلاعات مدرن، یک دایره کامله، نه یک نمودار ون.
پیشرفتها در پردازش زبان طبیعی (NLP) که با هدف بهبود جستجو شروع شد، ما رو به مدلهای زبان بزرگ مبتنی بر ترنسفورمر (LLM) رسوند. این LLMها به ما اجازه دادن تا بر اساس دادههای نتایج جستجو، محتوایی رو در پاسخ به کوئریها تولید کنیم.
بیاید با هم گپ بزنیم و ببینیم همه اینها چطور کار میکنه و مهارتهای سئو برای همگام شدن با این تغییرات، باید به چه سمتی بره.
تولید محتوای مبتنی بر بازیابی (RAG) چیست؟
تولید محتوای مبتنی بر بازیابی (Retrieval-Augmented Generation یا RAG) یک رویکرده که در اون، اسناد یا دادههای مرتبط بر اساس یک کوئری یا پرامپت جمعآوری میشن و به عنوان یک پرامپت چند نمونهای به مدل زبان اضافه میشن تا پاسخ نهایی رو دقیقتر کنن.
این یک مکانیزمه که به کمک اون، یک مدل زبان میتونه بر اساس «واقعیتها» عمل کنه یا از محتوای موجود یاد بگیره تا خروجی مرتبطتری با احتمال «توهم زدن» (Hallucination) کمتر تولید کنه.

با اینکه بازار فکر میکنه مایکروسافت با بینگ جدید این نوآوری رو معرفی کرده، اما تیم تحقیقاتی هوش مصنوعی فیسبوک (متا) اولین بار این مفهوم رو در می ۲۰۲۰ در مقالهای با عنوان «تولید محتوای مبتنی بر بازیابی برای وظایف NLP دانشمحور» در کنفرانس NeurIPS ارائه کرد. با این حال، Neeva اولین موتور جستجوی عمومی بزرگی بود که این تکنولوژی رو برای قدرت بخشیدن به فیچر اسنیپتهای دقیق و تاثیرگذارش پیادهسازی کرد.
این رویکرد بازی رو عوض میکنه، چون با اینکه LLMها میتونن حقایق رو به خاطر بسپارن، اما از نظر اطلاعاتی بر اساس دادههای آموزشیشون «قفل» شدن. برای مثال، اطلاعات ChatGPT تا قبل از این، محدود به سپتامبر ۲۰۲۱ بود.
مدل RAG اجازه میده اطلاعات جدید برای بهبود خروجی در نظر گرفته بشن. این دقیقا همون کاریه که شما موقع استفاده از قابلیت جستجوی بینگ یا خزش زنده در پلاگینهای ChatGPT مثل AIPRM انجام میدید.
این رویکرد همچنین بهترین روش برای استفاده از LLMها برای تولید محتوای قویتره. انتظار دارم با رایجتر شدن دانش این روش، افراد بیشتری از کاری که ما در آژانس خودمون برای تولید محتوای مشتریان انجام میدیم، پیروی کنن.
RAG چطور کار میکنه؟
تصور کنید شما دانشجویی هستید که داره یک مقاله تحقیقی مینویسه. شما کلی کتاب و مقاله درباره موضوعتون خوندید، پس زمینه لازم برای بحث کلی درباره موضوع رو دارید، اما هنوز برای اثبات استدلالهاتون به اطلاعات خاصی نیاز دارید.
شما میتونید از RAG مثل یک دستیار تحقیق استفاده کنید: بهش یک پرامپت میدید و اون مرتبطترین اطلاعات رو از پایگاه دانشش استخراج میکنه. بعد میتونید از این اطلاعات برای تولید خروجی دقیقتر، با سبک نوشتاری درستتر و کمتر بیروح و تکراری استفاده کنید. LLMها به کامپیوترها اجازه میدن پاسخهای کلی بر اساس احتمالات بدن. RAG اجازه میده اون پاسخ دقیقتر باشه و منابعش رو هم ذکر کنه.
یک پیادهسازی RAG از سه بخش تشکیل شده:
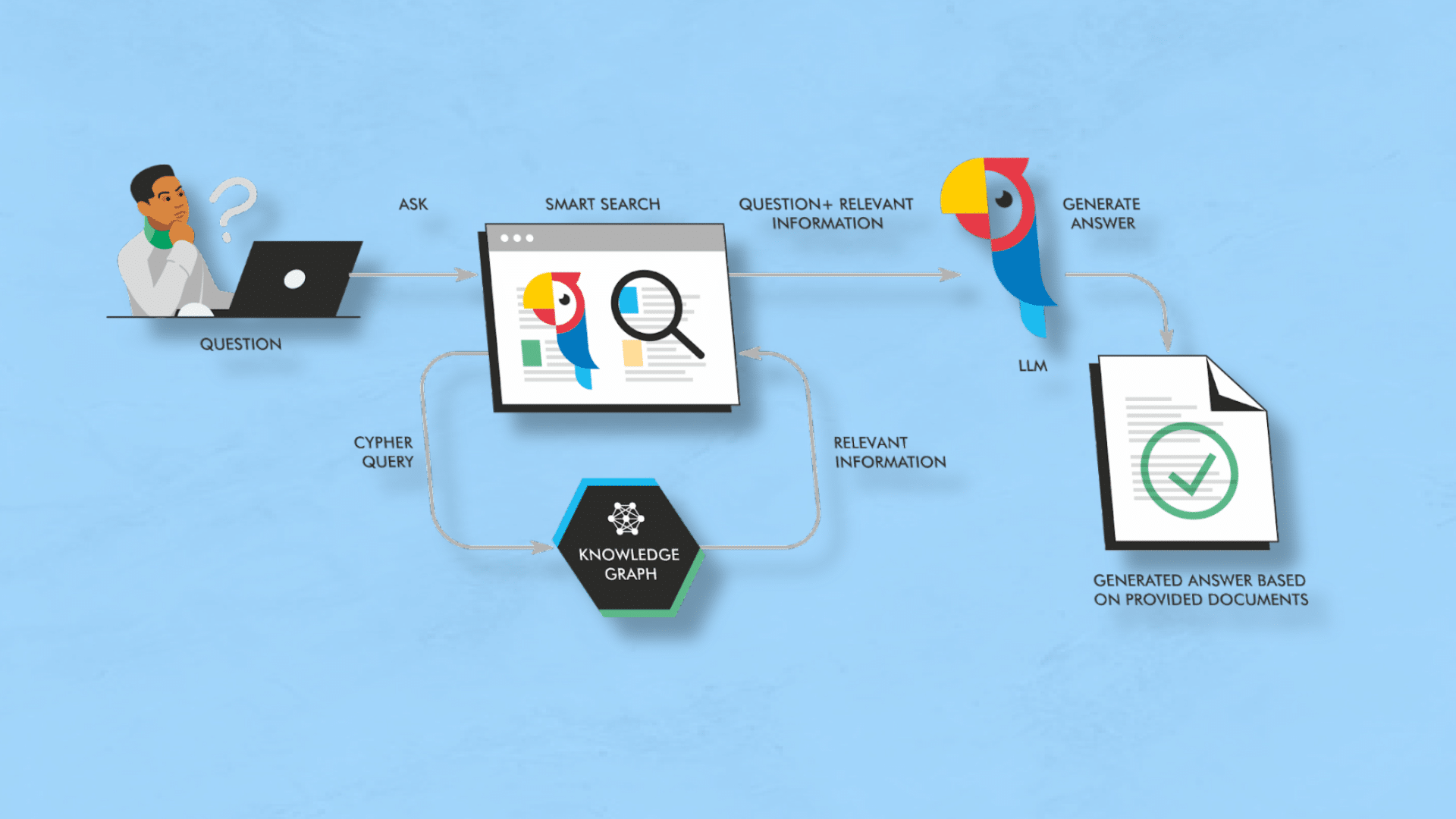
- رمزگذار ورودی (Input Encoder): این بخش، پرامپت ورودی رو به یک سری بردار امبدینگ (vector embeddings) برای عملیات بعدی تبدیل میکنه.
- بازیاب عصبی (Neural Retriever): این بخش مرتبطترین اسناد رو از پایگاه دانش خارجی بر اساس پرامپت ورودی رمزگذاری شده، بازیابی میکنه. وقتی اسناد ایندکس میشن، تکهتکه (chunk) میشن، بنابراین در طول فرآیند بازیابی، فقط مرتبطترین بخشهای اسناد و/یا گرافهای دانش به پرامپت اضافه میشن. به عبارت دیگه، یک موتور جستجو نتایجی رو برای اضافه کردن به پرامپت در اختیار میذاره.
- تولیدکننده خروجی (Output Generator): این بخش متن خروجی نهایی رو با در نظر گرفتن پرامپت ورودی رمزگذاری شده و اسناد بازیابی شده، تولید میکنه. این معمولاً یک مدل زبان بزرگ پایه مثل ChatGPT، Llama2 یا Claude هست.
برای اینکه این موضوع کمتر انتزاعی باشه، به پیادهسازی بینگ در ChatGPT فکر کنید. وقتی با اون ابزار کار میکنید، پرامپت شما رو میگیره، جستجوهایی رو برای جمعآوری اسناد انجام میده و مرتبطترین تکهها رو به پرامپت اضافه و اون رو اجرا میکنه.
هر سه بخش معمولاً با استفاده از ترنسفورمرهای از پیش آموزشدیده پیادهسازی میشن؛ نوعی شبکه عصبی که برای وظایف پردازش زبان طبیعی بسیار مؤثر بوده. باز هم، نوآوری ترنسفورمر گوگل، قدرتبخش کل دنیای جدید NLP/U/G امروزیه. سخته چیزی رو در این فضا پیدا کرد که ردپای تیم تحقیقاتی Google Brain روی اون نباشه.
رمزگذار ورودی و تولیدکننده خروجی برای یک وظیفه خاص مثل پاسخ به سؤال یا خلاصهسازی، بهینهسازی (fine-tune) میشن. بازیاب عصبی معمولاً بهینهسازی نمیشه، اما میتونه روی یک مجموعه بزرگ از متن و کد از پیش آموزش ببینه تا تواناییش در بازیابی اسناد مرتبط بهبود پیدا کنه.

RAG معمولاً با استفاده از اسناد در یک ایندکس برداری یا گرافهای دانش انجام میشه. در بسیاری از موارد، گرافهای دانش (KG) پیادهسازی مؤثرتر و کارآمدتری هستن، چون دادههای اضافه شده رو فقط به حقایق محدود میکنن.
همپوشانی بین گرافهای دانش و LLMها یک رابطه همزیستی رو نشون میده که پتانسیل هر دو رو آزاد میکنه. با توجه به اینکه بسیاری از این ابزارها از گرافهای دانش استفاده میکنن، الان زمان خوبیه که به استفاده از گرافهای دانش به عنوان چیزی فراتر از یک ابزار جدید یا چیزی که فقط دادههاش رو به گوگل میدیم تا بسازه، فکر کنیم.
چالشها و دردسرهای RAG
مزایای RAG کاملاً واضحه؛ شما با گسترش دانش در دسترس مدل زبان، به صورت خودکار خروجی بهتری میگیرید. چیزی که شاید کمتر واضح باشه، اینه که چه چیزهایی هنوز ممکنه اشتباه پیش بره و چرا. بیاید عمیقتر بشیم:
بازیابی اطلاعات؛ مرحله مرگ و زندگی
ببینید، اگه بخش بازیابی RAG درست کار نکنه، به مشکل میخوریم. مثل اینه که کسی رو بفرستید براتون چلوکباب سلطانی از بهترین رستوران شهر بگیره، ولی با یه ساندویچ نون و پنیر برگرده – اصلاً اون چیزی نیست که خواسته بودید.
اگه اسناد اشتباهی رو بیاره یا بهترینها رو جا بندازه، خروجی شما یه کم – خب – بیکیفیت میشه. هنوز هم قانون «آشغال بدی، آشغال تحویل میگیری» پابرجاست.
همه چیز به دادهها بستگی داره
این رویکرد یه جورایی به دادهها وابسته است. اگه با یک مجموعه داده کار میکنید که به اندازه اورکات یاهو ۳۶۰ از رده خارجه یا اصلاً به درد نمیخوره، دارید جلوی درخشش این سیستم رو میگیرید.
مراقب پژواک باشید!
وقتی به اسناد بازیابی شده نگاه میکنید، ممکنه حس دژاوو بهتون دست بده. اگه همپوشانی وجود داشته باشه، مدل مثل اون دوستی میشه که تو هر مهمونی یه داستان تکراری رو تعریف میکنه.
در نتایجتون تکرار خواهید داشت، و از اونجایی که سئو پر از محتوای کپی و تکراریه، ممکنه محتوای ضعیف و تحقیق نشده، نتایج شما رو تحت تأثیر قرار بده.
محدودیت طول پرامپت
یک پرامپت نمیتونه خیلی طولانی باشه و با اینکه میتونید اندازه تکهها (chunks) رو محدود کنید، باز هم مثل اینه که بخواید جهیزیه کامل رو تو یه پراید جا بدید. تا به امروز، فقط Claude از شرکت Anthropic از پنجره زمینه (context window) با ظرفیت ۱۰۰,۰۰۰ توکن پشتیبانی میکنه. GPT 3.5 Turbo حداکثر ۱۶,۰۰۰ توکن ظرفیت داره.
خارج شدن از مسیر
حتی با تمام تلاشهای قهرمانانه شما برای بازیابی اطلاعات، این به این معنی نیست که LLM به سناریو پایبند میمونه. هنوز هم میتونه توهم بزنه و اشتباه کنه.
گمان میکنم اینها دلایلی بودن که گوگل زودتر سراغ این تکنولوژی نرفت، اما از اونجایی که بالاخره وارد بازی شدن، بیاید در موردش صحبت کنیم.
تجربه تولیدی جستجو (SGE) چیست؟
برای این بحث، ما در مورد این صحبت خواهیم کرد که SGE یکی از پیادهسازیهای RAG توسط گوگل است؛ بارد (Bard) هم اون یکی دیگهست.
(یه نکته خودمونی: خروجی بارد از زمان عرضه خیلی بهتر شده. احتمالاً باید یه بار دیگه امتحانش کنید.)

رابط کاربری SGE هنوز خیلی در حال تغییره. همین الان که این مطلب رو مینویسم، گوگل تغییراتی ایجاد کرده و این تجربه رو با دکمههای «Show more» جمعوجورتر کرده.
بیایید روی سه جنبه SGE تمرکز کنیم که رفتار جستجو رو به طور قابل توجهی تغییر میدن:
درک کوئری
در گذشته، کوئریهای جستجو به ۳۲ کلمه محدود بودن. چون اسناد بر اساس لیستهای متقاطع برای عبارات ۲ تا ۵ کلمهای و گسترش اونها در نظر گرفته میشدن،
گوگل همیشه *معنی* کوئری رو نمیفهمید. گوگل اعلام کرده که SGE در درک کوئریهای پیچیده بسیار بهتر عمل میکنه.
اسنپشات هوش مصنوعی (AI Snapshot)
اسنپشات هوش مصنوعی یک نسخه قویتر از فیچر اسنیپته که متن تولیدی و لینک به منابع داره. این بخش اغلب تمام فضای بالای صفحه (above-the-fold) رو اشغال میکنه.
سوالات تکمیلی
سوالات تکمیلی، مفهوم پنجرههای زمینه (context windows) در ChatGPT رو به جستجو میارن. همونطور که کاربر از جستجوی اولیه به سمت جستجوهای تکمیلی بعدی حرکت میکنه، مجموعه صفحات در نظر گرفته شده بر اساس ارتباط متنی ایجاد شده توسط نتایج و کوئریهای قبلی، محدودتر میشه.
همه اینها با عملکرد استاندارد جستجو متفاوته. با عادت کردن کاربران به این عناصر جدید، احتمالاً شاهد یک تغییر قابل توجه در رفتار خواهیم بود، چون گوگل روی کاهش «هزینههای دلفی» (Delphic costs) جستجو تمرکز کرده. در نهایت، کاربران همیشه دنبال جواب بودن، نه ۱۰ لینک آبی رنگ.
تجربه تولیدی جستجوی گوگل چگونه کار میکند (REALM، RETRO و RARR)
بازار معتقده که گوگل SGE رو در واکنش به بینگ در اوایل سال ۲۰۲۳ ساخته. با این حال، تیم تحقیقاتی گوگل یک پیادهسازی از RAG رو در مقاله خودشون با عنوان «پیشآموزش مدل زبان مبتنی بر بازیابی (REALM)» که در آگوست ۲۰۲۰ منتشر شد، ارائه کرده بود.
این مقاله در مورد روشی صحبت میکنه که از رویکرد مدل زبان ماسکگذاری شده (MLM) که توسط BERT محبوب شد، برای پاسخ به سؤالات به روش «کتاب-باز» با استفاده از مجموعهای از اسناد و یک مدل زبان استفاده میکنه.
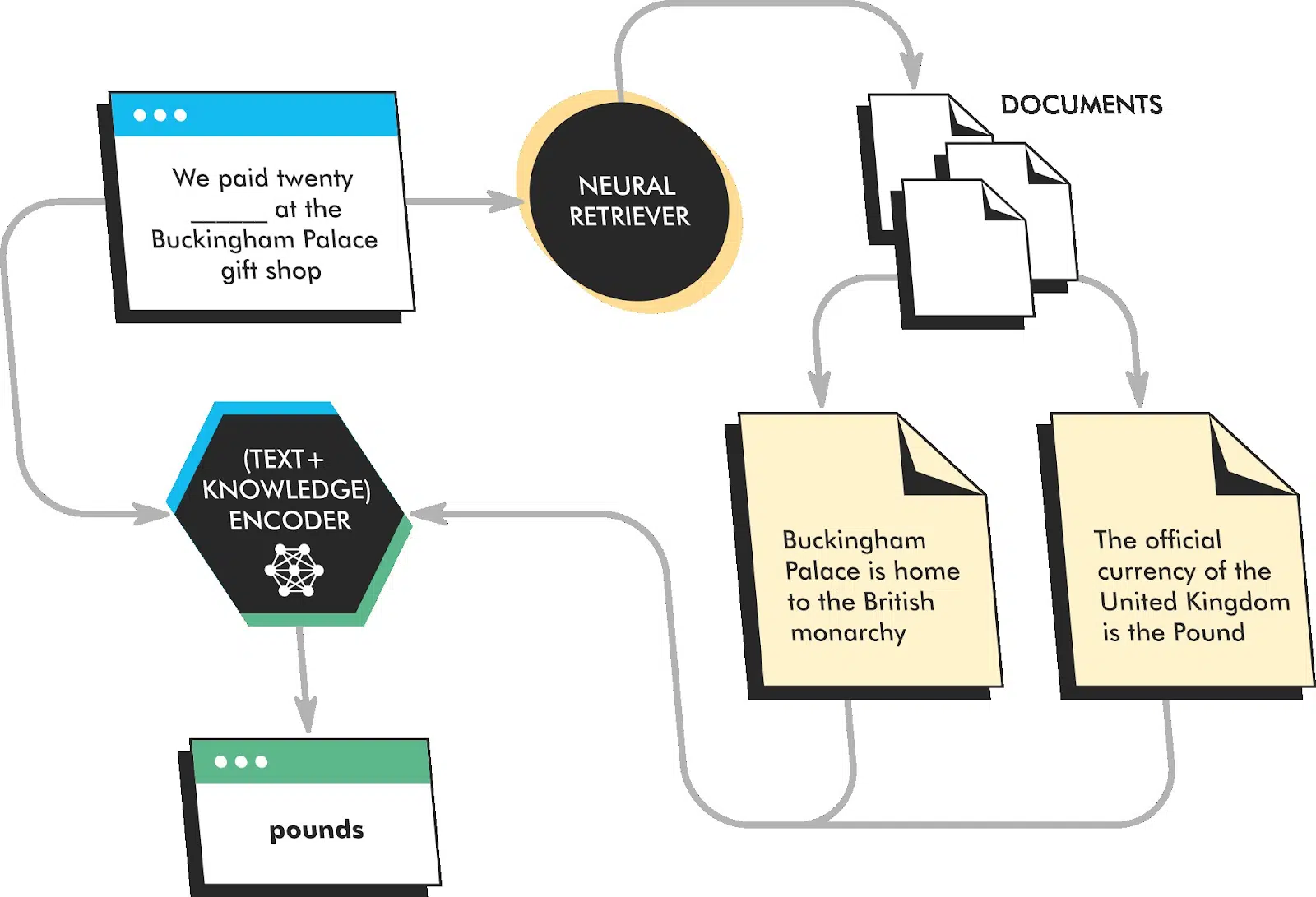
REALM اسناد کامل رو شناسایی میکنه، مرتبطترین بخشها رو در هر کدوم پیدا میکنه و تنها مرتبطترین بخش رو برای استخراج اطلاعات برمیگردونه.
در طول پیشآموزش، REALM آموزش میبینه که توکنهای ماسکگذاری شده در یک جمله رو پیشبینی کنه، اما همچنین آموزش میبینه که اسناد مرتبط رو از یک مجموعه بازیابی کنه و هنگام پیشبینی به این اسناد توجه کنه. این به REALM اجازه میده یاد بگیره متنی رو تولید کنه که از نظر واقعی بودن دقیقتر و آموزندهتر از مدلهای زبان سنتی باشه.
تیم DeepMind گوگل سپس این ایده رو با ترنسفورمر تقویتشده با بازیابی (RETRO) یک قدم جلوتر برد. RETRO یک مدل زبانه که شبیه REALM هست، اما از یک مکانیزم توجه (attention) متفاوت استفاده میکنه.
RETRO به اسناد بازیابی شده به صورت سلسلهمراتبیتری توجه میکنه، که بهش اجازه میده زمینه اسناد رو بهتر درک کنه. این منجر به تولید متنی میشه که روانتر و منسجمتر از متن تولید شده توسط REALM هست.
به دنبال RETRO، تیمها رویکردی به نام تخصیص اصلاحی با استفاده از تحقیق و بازبینی (RARR) رو برای کمک به اعتبارسنجی و پیادهسازی خروجی یک LLM و ذکر منابع توسعه دادن.

RARR یک رویکرد متفاوت برای مدلسازی زبانه. RARR متن رو از ابتدا تولید نمیکنه. در عوض، مجموعهای از بخشهای کاندید رو از یک مجموعه بازیابی میکنه و سپس اونها رو برای انتخاب بهترین بخش برای وظیفه مورد نظر، دوباره رتبهبندی میکنه. این رویکرد به RARR اجازه میده متن دقیقتر و آموزندهتری نسبت به مدلهای زبان سنتی تولید کنه، اما میتونه از نظر محاسباتی پرهزینهتر باشه.
این سه پیادهسازی برای RAG هر کدوم نقاط قوت و ضعف خودشون رو دارن. در حالی که چیزی که در حال حاضر در حال استفاده است، احتمالاً ترکیبی از نوآوریهای ارائه شده در این مقالات و موارد دیگهست، ایده اصلی اینه که اسناد و گرافهای دانش جستجو میشن و با یک مدل زبان برای تولید پاسخ استفاده میشن.
بر اساس اطلاعاتی که به صورت عمومی به اشتراک گذاشته شده، ما میدونیم که SGE از ترکیبی از مدلهای زبان PaLM 2 و MuM با جنبههایی از جستجوی گوگل به عنوان بازیاب خودش استفاده میکنه. این یعنی هم ایندکس اسناد گوگل و هم Knowledge Vault میتونن برای بهینهسازی پاسخها استفاده بشن.
بینگ زودتر به این نقطه رسید، اما با قدرت گوگل در جستجو، هیچ سازمانی به اندازه گوگل برای استفاده از این رویکرد برای نمایش و شخصیسازی اطلاعات، صلاحیت نداره.
تهدید تجربه تولیدی جستجو
مأموریت گوگل سازماندهی اطلاعات جهان و در دسترس قرار دادن اونهاست. در دراز مدت، شاید به ۱۰ لینک آبی رنگ مثل امروز که به فلاپی دیسک و پیجر نگاه میکنیم، نگاه کنیم. جستجو، به شکلی که ما میشناسیم، احتمالاً فقط یک گام میانی تا رسیدن به چیزی بسیار بهتره.
عرضه اخیر ویژگیهای چندوجهی ChatGPT همون کامپیوتر فیلم «پیشتازان فضا» (Star Trek) است که مهندسان گوگل اغلب گفتهاند میخواهند به آن برسند. کاربران همیشه دنبال جواب بودهاند، نه بار شناختی بررسی و تحلیل لیستی از گزینهها.
یک مقاله نظری اخیر با عنوان «جایگاهیابی جستجو» این باور را به چالش میکشد و بیان میکند که کاربران ترجیح میدهند خودشان تحقیق و اعتبارسنجی کنند و موتورهای جستجو جلوتر از آنها حرکت کردهاند.
بنابراین، این چیزی است که احتمالاً در نتیجه اتفاق خواهد افتاد.
توزیع مجدد منحنی تقاضای جستجو
با فاصله گرفتن کاربران از کوئریهای تلگرافی و کوتاه، کوئریهایشان طولانیتر خواهد شد.
وقتی کاربران متوجه شوند که گوگل درک بهتری از زبان طبیعی دارد، نحوه بیان جستجوهایشان را تغییر خواهند داد. کلمات کلیدی اصلی (Head terms) کاهش مییابند در حالی که کوئریهای متوسط (chunky middle) و طولانی (long-tail) رشد خواهند کرد.
مدل نرخ کلیک (CTR) تغییر خواهد کرد
۱۰ لینک آبی رنگ کلیکهای کمتری دریافت خواهند کرد زیرا اسنپشات هوش مصنوعی نتایج ارگانیک استاندارد را به پایین هل میدهد. نرخ کلیک (CTR) ۳۰ تا ۴۵ درصدی برای جایگاه اول احتمالاً به شدت کاهش خواهد یافت.
با این حال، ما در حال حاضر دادههای واقعی برای نشان دادن چگونگی تغییر این توزیع نداریم. بنابراین، نمودار زیر فقط برای اهداف نمایشی است.

رهگیری رتبه پیچیدهتر خواهد شد
ابزارهای رهگیری رتبه مدتی است که مجبور به رندر کردن SERP برای ویژگیهای مختلف بودهاند. اکنون، این ابزارها باید برای هر کوئری زمان بیشتری منتظر بمانند.
بیشتر محصولات SaaS بر روی پلتفرمهایی مانند Amazon Web Service (AWS)، Google Cloud Platform (GCP) و Microsoft Azure ساخته شدهاند که هزینههای محاسباتی را بر اساس زمان استفاده شده دریافت میکنند.
در حالی که نتایج رندر شده ممکن بود در ۱-۲ ثانیه برگردانده شوند، اکنون ممکن است نیاز به انتظار بسیار طولانیتری داشته باشند، که باعث افزایش هزینههای رهگیری رتبه میشود.
پنجرههای زمینه (Context Windows) نتایج شخصیسازیشدهتری را به همراه خواهند داشت
سوالات تکمیلی به کاربران سفرهای جستجویی شبیه داستانهای «خودت قهرمان داستانت باش» میدهند. با محدودتر شدن پنجره زمینه، مجموعهای از محتوای فوقالعاده مرتبط سفر را پر میکند، در حالی که هر کدام از این جستجوها به تنهایی نتایج مبهمتری به همراه داشتند.
به طور موثر، جستجوها چندبعدی میشوند و مسئولیت بر عهده تولیدکنندگان محتواست تا محتوای خود را برای مراحل مختلفی بهینه کنند تا در مجموعه گزینهها باقی بمانند.

در مثال بالا، Geico میخواهد محتوایی داشته باشد که با این شاخهها همپوشانی داشته باشد تا با پیشرفت کاربر در سفرش، در پنجره زمینه باقی بماند.
تعیین سطح تهدید SGE برای شما
ما دادهای در مورد چگونگی تغییر رفتار کاربران در محیط SGE نداریم. اگر شما دارید، لطفاً با ما تماس بگیرید (با شما هستم SimilarWeb).
چیزی که داریم، درک تاریخی از رفتار کاربران در جستجو است.
ما میدانیم که کاربران به طور متوسط ۱۴.۶۶ ثانیه برای انتخاب یک نتیجه جستجو زمان صرف میکنند. این به ما میگوید که یک کاربر برای یک اسنپشات هوش مصنوعی که به طور خودکار فعال میشود و زمان تولید آن بیش از ۱۴.۶ ثانیه است، منتظر نخواهد ماند. بنابراین، هر چیزی فراتر از این محدوده زمانی، تهدید فوری برای ترافیک جستجوی ارگانیک شما نیست، زیرا کاربر به جای انتظار، به سادگی به نتایج استاندارد پایین صفحه اسکرول میکند.

ما همچنین میدانیم که، به طور تاریخی، فیچر اسنیپتها ۳۵.۱٪ از کلیکها را در زمانی که در SERP حضور دارند، به خود اختصاص دادهاند.

از این دو داده میتوان برای ایجاد چند فرض برای ساختن مدلی از تهدید و میزان ترافیکی که ممکن است از این تغییر از دست برود، استفاده کرد.
بیایید ابتدا وضعیت SGE را بر اساس دادههای موجود بررسی کنیم.
وضعیت فعلی SGE
از آنجایی که دادهای در مورد SGE وجود ندارد، عالی میشد اگر کسی مقداری داده ایجاد میکرد. من به طور اتفاقی با یک مجموعه داده از تقریباً ۹۱,۰۰۰ کوئری و SERPهای آنها در SGE برخورد کردم.
برای هر یک از این کوئریها، مجموعه داده شامل موارد زیر است:
- کوئری: جستجویی که انجام شده است.
- HTML اولیه: HTML هنگام بارگذاری اولیه SERP.
- HTML نهایی: HTML پس از بارگذاری اسنپشات هوش مصنوعی.
- زمان بارگذاری اسنپشات هوش مصنوعی: چه مدت طول کشید تا اسنپشات هوش مصنوعی بارگذاری شود.
- فعالسازی خودکار (Autotrigger): آیا اسنپشات به طور خودکار فعال میشود یا باید روی دکمه *تولید (Generate)* کلیک کنید؟
- نوع اسنپشات هوش مصنوعی: آیا اسنپشات هوش مصنوعی اطلاعاتی، خرید یا محلی است؟
- سوالات تکمیلی: لیست سوالات در بخش تکمیلی.
- URLهای کاروسل: URLهای نتایجی که در اسنپشات هوش مصنوعی ظاهر میشوند.
- ۱۰ نتیجه ارگانیک برتر: ۱۰ URL برتر برای دیدن همپوشانی.
- وضعیت اسنپشات: آیا اسنپشات یا دکمه تولید وجود دارد؟
- وضعیت «بیشتر نشان بده»: آیا اسنپشات نیاز به کلیک کاربر روی «بیشتر نشان بده» دارد؟
کوئریها همچنین به دستههای مختلفی تقسیم شدهاند تا بتوانیم درکی از نحوه عملکرد موارد مختلف داشته باشیم. فرصت کافی برای بررسی کل مجموعه داده را ندارم، اما در اینجا برخی از یافتههای سطح بالا آورده شده است.
اسنپشاتهای هوش مصنوعی اکنون به طور متوسط ۶.۰۸ ثانیه برای تولید زمان میبرند

وقتی SGE برای اولین بار راهاندازی شد و من شروع به بررسی زمان بارگذاری اسنپشات هوش مصنوعی کردم، ۱۱ تا ۳۰ ثانیه طول میکشید تا ظاهر شوند. اکنون من محدودهای بین ۱.۸ تا ۱۷.۲ ثانیه برای زمان بارگذاری میبینم. اسنپشاتهای هوش مصنوعی که به طور خودکار فعال میشوند بین ۲.۹ تا ۱۵.۸ ثانیه بارگذاری میشوند.
همانطور که از نمودار میبینید، بیشتر زمانهای بارگذاری در حال حاضر بسیار کمتر از ۱۴.۶ ثانیه هستند. کاملاً واضح است که ترافیک «۱۰ لینک آبی» برای اکثریت قریب به اتفاق کوئریها تهدید خواهد شد.

میانگین بسته به دسته کلمه کلیدی کمی متفاوت است. با توجه به اینکه دسته سرگرمی-ورزش زمان بارگذاری بسیار بالاتری نسبت به سایر دستهها دارد، این ممکن است تابعی از سنگینی محتوای منبع برای صفحات در هر حوزه باشد.
توزیع نوع اسنپشات
در حالی که انواع مختلفی از این تجربه وجود دارد، من به طور کلی انواع اسنپشات را به تجربیات صفحه اطلاعاتی، محلی و خرید تقسیم کردهام. در مجموعه ۹۱,۰۰۰ کلمه کلیدی من، تفکیک به این صورت است: ۵۱.۰۸٪ اطلاعاتی، ۳۱.۳۱٪ محلی و ۱۷.۶۰٪ خرید.
۶۰.۳۴٪ از کوئریها اسنپشات هوش مصنوعی نداشتند

در تجزیه و تحلیل محتوای صفحه، مجموعه داده دو مورد را برای تأیید وجود اسنپشات در صفحه شناسایی میکند. این موارد به دنبال اسنپشات فعالشده خودکار و دکمه *تولید (Generate)* میگردد. بررسی این دادهها نشان میدهد که ۳۹.۶۶٪ از کوئریها در مجموعه داده اسنپشات هوش مصنوعی را فعال کردهاند.
۱۰ نتیجه برتر اغلب استفاده میشوند اما نه همیشه
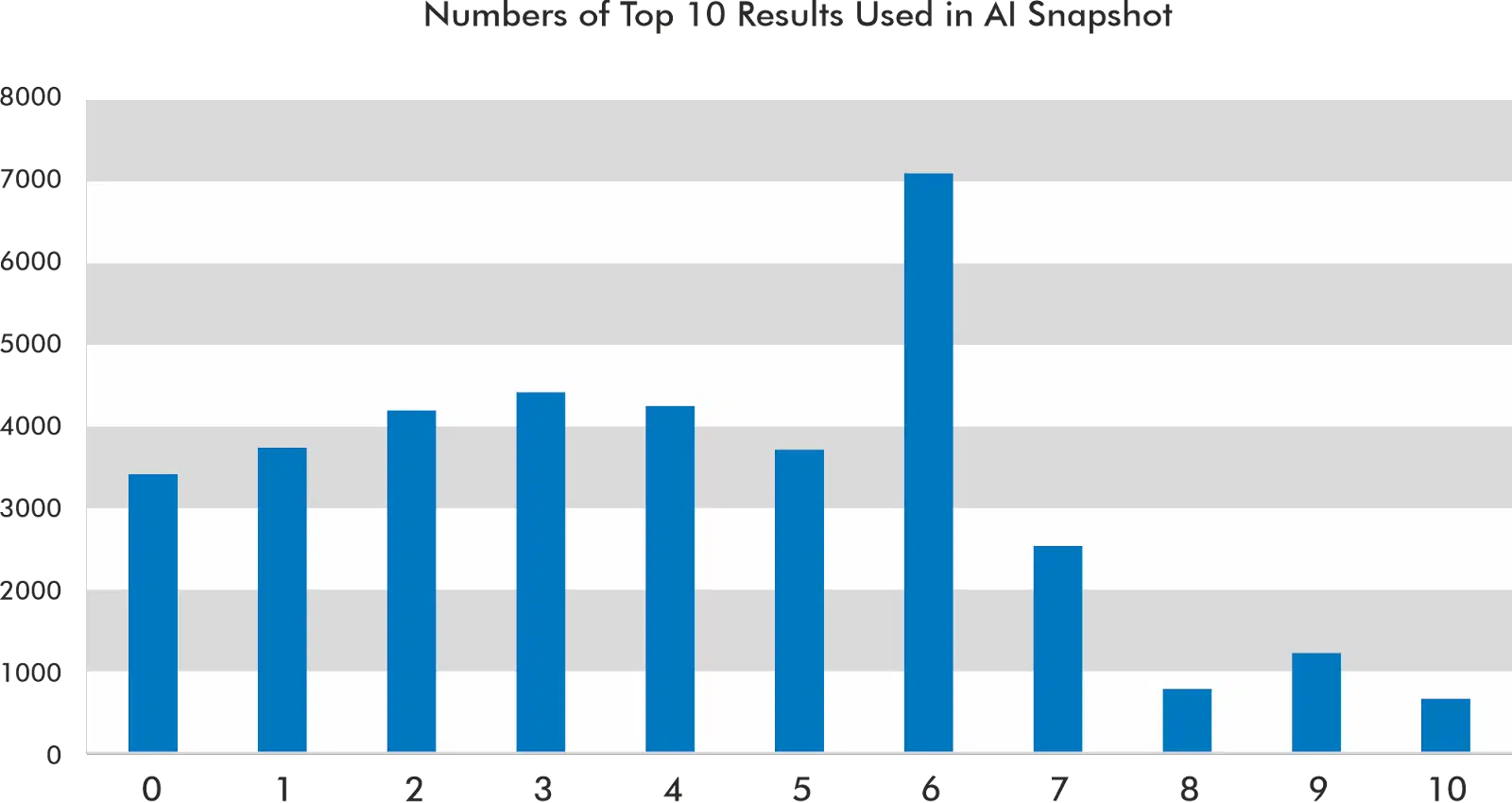
در مجموعه دادهای که من بررسی کردهام، جایگاههای ۱، ۲ و ۹ بیشترین استناد را در کاروسل اسنپشات هوش مصنوعی دارند.

اسنپشات هوش مصنوعی اغلب از شش نتیجه از ۱۰ نتیجه برتر برای ساختن پاسخ خود استفاده میکند. با این حال، در ۹.۴۸٪ از موارد، از هیچ یک از ۱۰ نتیجه برتر در اسنپشات هوش مصنوعی استفاده نمیکند.
بر اساس دادههای من، به ندرت از تمام نتایج ۱۰ نتیجه برتر استفاده میکند.
بخشهای بسیار مرتبط (Highly relevant chunks) اغلب زودتر در کاروسل ظاهر میشوند
بیایید اسنپشات هوش مصنوعی را برای کوئری [bmw i8] در نظر بگیریم. این کوئری هفت نتیجه را در کاروسل برمیگرداند. چهار مورد از آنها به طور صریح در استنادها ذکر شدهاند.

کلیک کردن روی یک نتیجه در کاروسل اغلب شما را به یکی از «فرگلها» (fraggles) (اصطلاحی که سیندی کروم برای لینکهای رتبهبندی قطعهای (passage ranking) ابداع کرد) میبرد که شما را روی یک جمله یا پاراگراف خاص قرار میدهد.

مفهوم این است که اینها پاراگرافها یا جملاتی هستند که به اسنپشات هوش مصنوعی اطلاعات میدهند.
طبیعتاً، گام بعدی ما این است که سعی کنیم درکی از نحوه رتبهبندی این نتایج داشته باشیم زیرا آنها به همان ترتیبی که URLهای ذکر شده در متن ارائه شدهاند، نمایش داده نمیشوند.
من فرض میکنم که این رتبهبندی بیشتر به ارتباط (relevance) مربوط است تا هر چیز دیگری.
برای آزمایش این فرضیه، من پاراگرافها را با استفاده از Universal Sentence Encoder به بردار تبدیل کردم و آنها را با کوئری برداری شده مقایسه کردم تا ببینم آیا ترتیب نزولی برقرار است یا خیر.
انتظار داشتم پاراگرافی که بالاترین امتیاز شباهت را دارد، اولین پاراگراف در کاروسل باشد.
نتایج دقیقاً آن چیزی که انتظار داشتم نبود. شاید نوعی گسترش کوئری در کار باشد که کوئریای که من مقایسه میکنم با آنچه گوگل ممکن است مقایسه کند، یکسان نیست.
در هر صورت، این نتیجه برای من کافی بود تا این موضوع را بیشتر بررسی کنم. با مقایسه پاراگرافهای ورودی با پاراگراف اسنپشات تولید شده، نتیجه اول برنده واضح از نظر ارتباط است.
اینکه بخش (chunk) استفاده شده در نتیجه اول بیشترین شباهت را به پاراگراف اسنپشات هوش مصنوعی دارد، در بسیاری از مواردی که به صورت موردی بررسی کردهام، صادق بوده است.
بنابراین، تا زمانی که شواهد دیگری نبینم، رتبهبندی در ۲ رتبه برتر نتایج ارگانیک و داشتن مرتبطترین قطعه محتوا، بهترین راه برای قرار گرفتن در جایگاه اول کاروسل در SGE است.
محاسبه سطح تهدید SGE شما
فقدان دادههای کامل به ندرت دلیلی برای ارزیابی نکردن ریسک در یک محیط تجاری است. بسیاری از برندها میخواهند تخمینی از میزان ترافیکی که ممکن است با در دسترس قرار گرفتن گسترده SGE از دست بدهند، داشته باشند.
برای این منظور، ما مدلی برای تعیین پتانسیل از دست دادن ترافیک ساختهایم. معادله سطح بالا بسیار ساده است:
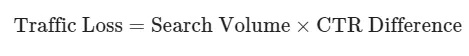
ما این محاسبه را فقط روی کلمات کلیدیای انجام میدهیم که اسنپشات هوش مصنوعی دارند. بنابراین، نمایش بهتری از فرمول به شرح زیر است.
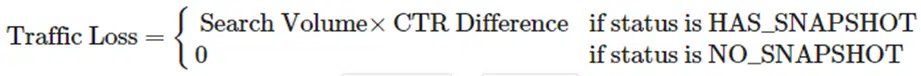
CTR تنظیمشده (Adjusted CTR) جایی است که بیشتر جادو اتفاق میافتد، و برای رسیدن به اینجا، به قول امروزیها، باید «حساب کتابها جور در بیاد».
ما باید روشهای مختلفی را که SERP خود را با توجه به نوع صفحه، فعال شدن خودکار یا نمایش دکمه «بیشتر نشان بده» ارائه میدهد، در نظر بگیریم.
توضیح کوتاه این است که ما یک CTR تنظیمشده برای هر کلمه کلیدی بر اساس حضور و زمان بارگذاری یک اسنپشات هوش مصنوعی تعیین میکنیم، و انتظار داریم که بزرگترین تهدید برای یک نتیجه خرید باشد زیرا یک تجربه تمامصفحه است.
متریک CTR تنظیمشده ما تابعی از آن پارامترها است که در یک فاکتور توزیع نشان داده میشود.
فاکتور توزیع، تأثیر وزندار لینکهای کاروسل، لینکهای استناد، لینکهای خرید و لینکهای محلی در اسنپشات هوش مصنوعی است.
این فاکتور بر اساس حضور این عناصر تغییر میکند و به ما امکان میدهد تا در نظر بگیریم که آیا دامنه هدف در هر یک از این ویژگیها حضور دارد یا خیر.
برای غیرمشتریان، ما این گزارشها را با استفاده از کلمات کلیدی غیربرند که درصد ترافیک آنها در Semrush غیرصفر است و CTR مخصوص هر حوزه از مطالعه CTR Advanced Web Ranking اجرا میکنیم.
برای مشتریان، ما همین کار را با استفاده از تمام کلمات کلیدیای که ۸۰٪ از کلیکها را به خود اختصاص میدهند و مدل CTR خودشان در Google Search Console انجام میدهیم.
به عنوان مثال، با محاسبه این موارد روی کلمات کلیدی پر ترافیک برای Nerdwallet (که مشتری ما نیست)، دادهها سطح تهدید «هشدار» را با پتانسیل از دست دادن ۳۰.۸۱٪ نشان میدهد. برای سایتی که عمدتاً از طریق درآمد همکاری در فروش (affiliate) کسب درآمد میکند، این یک حفره قابل توجه در جریان نقدی آنهاست.
این به ما امکان داده است تا گزارشهای تهدید را برای مشتریان خود بر اساس نحوه نمایش فعلی آنها در SGE تهیه کنیم. ما پتانسیل از دست دادن ترافیک را محاسبه کرده و آن را در مقیاسی از کم تا شدید امتیاز میدهیم.
مشتریان این کار را برای متعادل کردن استراتژی کلمات کلیدی خود برای کاهش زیانهای آینده ارزشمند میدانند. اگر علاقهمند به دریافت گزارش تهدید خود هستید، با ما تماس بگیرید.
معرفی Raggle: یک نمونه اولیه برای SGE
وقتی برای اولین بار SGE را در Google I/O دیدم، مشتاق بودم با آن کار کنم. تا چند هفته بعد به صورت عمومی در دسترس قرار نمیگرفت، بنابراین شروع به ساخت نسخه خودم از آن کردم. تقریباً در همان زمان، دوستان خوب در AvesAPI، ارائهدهنده دادههای JSON SERP، با من تماس گرفتند و یک نسخه آزمایشی از سرویس خود را به من پیشنهاد دادند.
متوجه شدم که میتوانم از سرویس آنها با یک فریمورک متنباز برای برنامههای LLM به نام Llama Index استفاده کنم تا به سرعت نسخهای از نحوه کار SGE را راهاندازی کنم.
و این کاری بود که کردم. اسمش Raggle است.
البته بگذارید انتظارات شما را کمی مدیریت کنم، چون من این را با روحیه تحقیق و نه با تیمی متشکل از ۵۰,۰۰۰ مهندس و دکترای تراز اول ساختهام. اینها کاستیهای آن است:
- خیلی کند است.
- ریسپانسیو نیست.
- فقط پاسخهای اطلاعاتی میدهد.
- سوالات تکمیلی را پر نمیکند.
- وقتی اعتبار AvesAPI من تمام شود، کوئریهای جدید کار نخواهند کرد.
با این حال، من چند ایستر اگ (easter egg) و ویژگیهای اضافی برای کمک به درک نحوه استفاده گوگل از RAG اضافه کردهام.
Raggle چگونه کار میکند
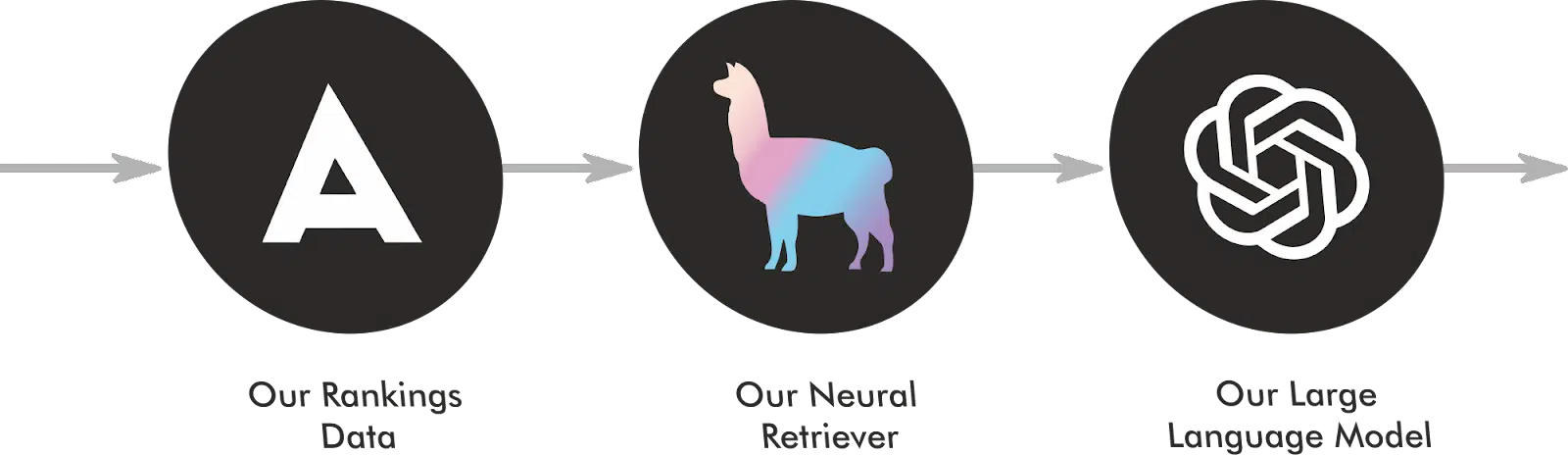
Raggle در واقع یک پیادهسازی RAG بر روی یک راهحل API SERP است.
در زمان اجرا، کوئری را به AvesAPI ارسال میکند تا SERP را دریافت کند. ما به محض بازگشت HTML SERP، آن را به کاربر نشان میدهیم و سپس شروع به خزیدن ۲۰ نتیجه برتر به صورت موازی میکنیم.
پس از استخراج محتوا از هر صفحه، آن را به یک ایندکس در Llama Index با URLها، عناوین صفحات، متا دیسکریپشنها و تصاویر og:image به عنوان متادیتا برای هر ورودی اضافه میکنیم.
سپس، از ایندکس با یک پرامپت که شامل کوئری اصلی کاربر با دستوری برای پاسخ به کوئری در ۱۵۰ کلمه است، پرسوجو میشود. بهترین تکههای (chunks) حاصل از ایندکس برداری به کوئری اضافه شده و به API GPT 3.5 Turbo ارسال میشود تا اسنپشات هوش مصنوعی را تولید کند.
ایجاد ایندکس از اسناد و پرسوجو از آن تنها سه دستور است:
index = VectorStoreIndex.from_documents(documents)
query_engine = CitationQueryEngine.from_args(
index,
# here we can control how many citation sources
similarity_top_k=5,
# here we can control how granular citation sources are, the default is 512
citation_chunk_size=155,
)
response = query_engine.query("Answer the following query in 150 words: " + query)با استفاده از متدهای استناد ارائه شده توسط Llama Index، میتوانیم بلوکهای متن و متادیتای آنها را برای استناد به منابع بازیابی کنیم. اینگونه است که من میتوانم استنادها را در خروجی به همان روشی که SGE انجام میدهد، نمایش دهم.
finalResponse["citations"].append({
'url': citation.node.metadata.get('url', 'N/A'),
'image': citation.node.metadata.get('image', 'N/A'),
'title': citation.node.metadata.get('title', 'N/A'),
'description': citation.node.metadata.get('description', 'N/A'),
'text': citation.node.get_text() if hasattr(citation.node, 'get_text') else
'N/A',
'favicon': citation.node.metadata.get('favicon', 'N/A'),
'sitename' : citation.node.metadata.get('sitename', 'N/A'),
})میتوانید با آن کار کنید. وقتی روی سه نقطه در سمت راست کلیک میکنید، کاوشگر تکهها (chunk explorer) باز میشود، جایی که میتوانید تکههای استفاده شده برای اطلاعرسانی به پاسخ اسنپشات هوش مصنوعی را ببینید.
در این پیادهسازی نمونه اولیه، متوجه خواهید شد که محاسبه ارتباط کوئری در مقابل تکهها چقدر با ترتیبی که نتایج در کاروسلها نمایش داده میشوند، همخوانی دارد.
ما در آینده جستجو زندگی میکنیم
من نزدیک به دو دهه در حوزه جستجو بودهام. در ۱۰ ماه گذشته شاهد تغییراتی بودهایم که در تمام دوران حرفهایام ندیدهام – و این را در حالی میگویم که آپدیتهای فلوریدا، پاندا و پنگوئن را تجربه کردهام.
این موج تغییرات، فرصتهای زیادی برای بهرهبرداری از فناوریهای جدید ایجاد میکند. محققان در زمینه بازیابی اطلاعات و NLP/NLU/NLG آنقدر در مورد یافتههای خود شفاف هستند که ما درک بیشتری از نحوه کارکرد واقعی همه چیز پیدا میکنیم.
اکنون زمان خوبی است تا بفهمیم چگونه میتوان خطوط لوله RAG را در موارد استفاده سئو خودمان ادغام کنیم.
با این حال، گوگل از چندین جبهه مورد حمله قرار گرفته است.
- تیکتاک.
- ChatGPT.
- وزارت دادگستری آمریکا (DOJ).
- درک کاربران از کیفیت جستجو.
- سیل محتوای تولید شده توسط هوش مصنوعی.
- نسخههای متعدد سیستمهای پاسخگویی به سوال در بازار.
در نهایت، تمام این تهدیدها برای گوگل، تهدیدی برای ترافیک شما از گوگل هستند.
چشمانداز جستجوی ارگانیک به شیوههای معناداری در حال تغییر و پیچیدهتر شدن است. با ادامه تکهتکه شدن روشهایی که کاربران نیازهای اطلاعاتی خود را برآورده میکنند، ما از بهینهسازی برای وب به سمت بهینهسازی برای مدلهای زبان بزرگ حرکت خواهیم کرد و پتانسیل واقعی دادههای ساختاریافته را در این محیط درک خواهیم کرد.
درست مانند بیشتر فرصتها در وب، افرادی که زودتر از همه این فرصتها را بپذیرند، بازدهی بسیار بیشتری خواهند دید.
پاسخی بگذارید