
کاربران واقعی مدلهای زبانی بزرگ چطور ازشون استفاده میکنن و این چه معنایی برای ناشران داره؟
روند استفاده از مدلهای زبانی بزرگ (LLM) در طول زمان، نکات مهمی رو برای تولیدکنندگان محتوا و مدیران وبسایتها روشن میکنه. بازار داره بزرگتر میشه، اما ما هم باید بهتر بشیم.
شرکت OpenAI به تازگی بزرگترین تحقیقی که تا امروز انجام شده رو درباره نحوه استفاده واقعی کاربرا از ChatGPT منتشر کرده. منم با کلی وسواس، نکات مهمی که به درد من و شما میخوره رو از دل این تحقیق بیرون کشیدم تا شما مجبور نباشید بین یه عالمه اطلاعات ریز و درشت، مفید و بیفایده سردرگم بشید.
خلاصه کلام (TL;DR)
- مدلهای زبانی بزرگ (LLM) قرار نیست جایگزین جستجو بشن. اما دارن نحوه دسترسی و مصرف اطلاعات توسط مردم رو تغییر میدن.
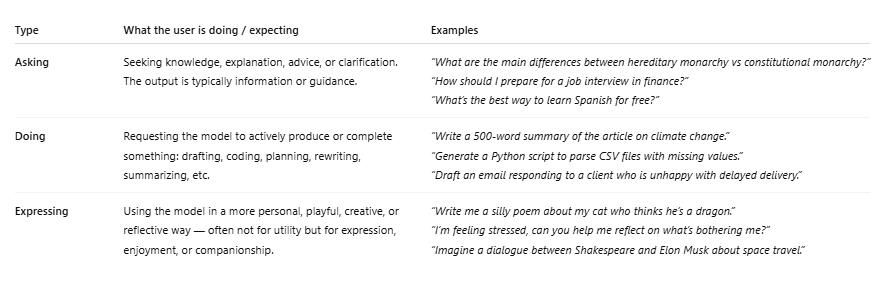
- کوئریهای «پرسشی» (Asking) با ۴۹٪ و کوئریهای «اجرایی» (Doing) با ۴۰٪، بازار رو در دست گرفتن و کیفیتشون هم روز به روز بهتر میشه.
- سه کاربرد اصلی یعنی «راهنمایی عملی»، «جستجوی اطلاعات» و «نوشتن»، ۸۰ درصد کل مکالمات رو تشکیل میدن.
- تولیدکنندههای محتوا باید داراییهای قابل لینک (Linkable Assets) بسازن که ارزش افزوده ایجاد کنه. دیگه دوره اینکه فقط دنبال ترافیک گرفتن از مقالهها باشیم تموم شده.

چتبات ۱۰۱: اصول اولیه
چتبات یه مدل آماریه که آموزش دیده تا در جواب یه متن ورودی، یه متن خروجی تولید کنه. یه چیزی تو مایههای «میمون هرچی ببینه، یاد میگیره.»
چتباتهای پیشرفتهتر، یه فرآیند آموزشی دو یا چند مرحلهای دارن. تو مرحله اول (که بهش «پیشآموزش» یا pre-training هم میگن)، مدلهای زبانی بزرگ یاد میگیرن کلمه بعدی تو یه جمله رو پیشبینی کنن.
این مدلها مثل بهترین حسابدار دنیا، هم قابل پیشبینیان و هم حوصلهسربر. البته این لزوماً چیز بدی نیست. من دوست دارم آشپزم چاق باشه، خلبانم هوشیار باشه و مشاور مالیم اونقدر آدم خشکی باشه که نفر بعدی برای رهبری یه حزب محیط زیستی باشه!
تو مرحله دوم اوضاع یکم جذابتر میشه. تو فاز «پسآموزش» (post-training)، مدلها آموزش میبینن تا جوابهای «باکیفیت» برای پرامپتها تولید کنن. اونها با استراتژیهای مختلفی مثل «یادگیری تقویتی» (reinforcement learning) بهینهسازی میشن تا به پاسخها نمره بدن.
به مرور زمان، این مدلهای زبانی، درست مثل سگ پاولف، بر اساس کیفیت جوابهاشون یا تشویق میشن یا تنبیه.
تو فاز اول، مدل یه درک پنهان (البته «درک» داخل گیومه) از دنیا پیدا میکنه. تو فاز دوم، دانشش صیقل داده میشه تا بهترین و باکیفیتترین جواب رو تولید کنه.
بدون تنظیمات «دما» (temperature)، مدلهای زبانی بزرگ تا زمانی که فرآیند آموزششون یکسان باشه، بارها و بارها دقیقاً همون جواب رو تولید میکنن.
دماهای بالاتر (نزدیک به ۱.۰) باعث افزایش تصادفی بودن و خلاقیت میشن. دماهای پایینتر (نزدیک به ۰) مدلها رو خیلی قابل پیشبینیتر و دقیقتر میکنن.
پس، کاربرد شماست که تنظیمات دمای مناسب رو مشخص میکنه. برای کدنویسی بهتره دما نزدیک به صفر باشه. برای کارهای خلاقانهتر و محتوامحور، بهتره دما به یک نزدیکتر باشه.
دادهها به ما چه میگویند؟
اینکه مدلهای زبانی بزرگ جایگزین مستقیم جستجو نیستن. به نظر من حتی نزدیک به اون هم نیستن. این تحقیق سمراش نشون داد که کاربران حرفهای LLM، میزان جستجوهای سنتی خودشون رو افزایش دادن. به نظر میرسه نظریه «گسترش» (expansion theory) درسته.
اما این مدلها یه تغییر اساسی تو نحوه دسترسی و تعامل مردم با اطلاعات ایجاد کردن. رابطهای کاربری محاورهای ارزش فوقالعادهای دارن؛ مخصوصاً تو محیطهای کاری.
کی فکرشو میکرد ما اینقدر تنبل باشیم؟
۱. راهنمایی، جستجوی اطلاعات و نوشتن، سه کاربرد اصلی
این سه کاربرد اصلی، ۸۰ درصد کل مکالمات بین انسان و ربات رو تشکیل میدن: راهنمایی عملی، جستجوی اطلاعات، و «ربات شگفتانگیز، لطفاً کمکم کن یه متن بیروح و بدون هیچ شور و بینشی بنویسم.»
البته قبول دارم که اکثر کوئریهای مربوط به «نوشتن» برای ویرایش متنهای موجوده. با این حال، اگه من متنی رو بخونم که توسط هوش مصنوعی نوشته شده، حس میکنم سرم کلاه رفته. و فریبکاری اصلاً ویژگی جذابی نیست.
۲. استفاده غیرکاری رو به افزایش است
- پیامهای غیرکاری از ۵۳٪ کل استفاده، تا جولای ۲۰۲۵ به بیش از ۷۰٪ رسیده.
- استفاده از مدلهای زبانی بزرگ به یه عادت تبدیل شده؛ مخصوصاً وقتی پای تصمیمگیریهای درست، چه تو محیط کار و چه بیرون از اون، وسط باشه.
۳. نوشتن، رایجترین کاربرد در محیط کار
- «نوشتن» رایجترین کاربرد کاریه و به طور متوسط در ژوئن ۲۰۲۵، ۴۰٪ از پیامهای مربوط به کار رو تشکیل داده.
- حدود دو سوم از کل پیامهای مربوط به «نوشتن»، درخواست برای ویرایش متنهای موجود کاربره، نه تولید متن جدید از صفر.
من کلی آدم میشناسم که فقط از مدلهای زبانی بزرگ برای نوشتن ایمیلهای بهتر استفاده میکنن. تقریباً دلم برای اون خورههای تکنولوژی میسوزه که میبینن کاربردهای اصلی این ابزارها اینقدر خالی از خلاقیته.
۴. کدنویسی، کمتر از انتظار
- کوئریهای مربوط به کدنویسی کامپیوتر سهم نسبتاً کمی دارن و فقط ۴.۲٪ از کل پیامها رو تشکیل میدن.*
- شاید این آمار عجیب به نظر برسه، اما رباتهای تخصصی مثل Claude یا ابزارهایی مثل Lovable جایگزینهای بهتری هستن.
- این یه نکته قابل توجهه. استفاده از مدلهای زبانی تخصصی رشد میکنه و به احتمال زیاد صنایع خاصی رو تحت سلطه خودش درمیاره، چون میتونن خروجیهای باکیفیتتری تولید کنن. آموزش تخصصی به سبک مرحله دوم، محصول خیلی بهتری رو به وجود میاره.
*در مقایسه با ۳۳٪ از مکالمات کاری در Claude.
البته مهمه که بدونید مطالعات دیگهای هم وجود دارن که نظرات متفاوتی درباره کاربردهای مدلهای زبانی بزرگ دارن. پس اوضاع اونقدرها هم که فکر میکنیم قطعی و مشخص نیست. مطمئنم که شرایط در آینده هم تغییر میکنه.
۵. دیگه خبری از سلطه مردها نیست
- کاربران اولیه به طور نامتناسبی مرد بودن (حدود ۸۰٪ با اسمهایی که معمولاً مردانه هستن).
- این عدد تا ژوئن ۲۰۲۵ به ۴۸٪ کاهش پیدا کرده و حالا احتمال اینکه کاربران فعال اسمهای زنانه داشته باشن، کمی بیشتره.
قبول، ما مردها هم عیب و ایرادای خودمون رو داریم. شاید در طول تاریخ یکم تو جنگ و دعوا عجول بودیم و یه کم هم سلطهگر. اما دیدن این برابری حس خوبیه.
۶. کوئریهای پرسشی سریعتر رشد میکنند و باکیفیتترند
- ۸۹٪ از کل کوئریها مربوط به «پرسش» (Asking) و «اجرا» (Doing) هستن.
- ۴۹٪ پرسشی، ۴۰٪ اجرایی و فقط ۱۱٪ برای «بیان احساسات» (Expressing).
- پیامهای پرسشی در طول سال گذشته سریعتر از پیامهای اجرایی رشد کردن و کیفیت بالاتری هم دارن.
۷. روابط و تأملات شخصی در اولویت نیستند
- مطالعات زیادی بودن که میگفتن مدلهای زبانی بزرگ برای مردم نقش رواندرمانگر شخصی رو پیدا کردن (همونطور که بالاتر اشاره شد).
- اما طبق گفته OpenAI، روابط و تأملات شخصی فقط ۱.۹٪ از کل پیامها رو تشکیل میدن.
۸. این جوونهای لعنتی (*با مشت گرهکرده*)
- تقریباً نصف کل پیامهایی که توسط بزرگسالان ارسال شده، از طرف کاربرای زیر ۲۶ سال بوده.
- این موضوع کاملاً با تحقیق کوین ایندیگ درباره نحوه استفاده گروههای سنی مختلف از AI Overviews گوگل همخونی داره. جوونترها الف) بیشتر بهش اعتماد میکنن و ب) بیشتر ازش استفاده میکنن.
نتیجهگیری نهایی
من فکر نمیکنم مدلهای زبانی بزرگ یه فاجعه برای تولیدکنندههای محتوا باشن. درسته، هیچ ترافیک ارجاعی (referral) برامون نمیفرستن و شروع کردن به حذف کردن منابع و استنادها برای کاربرای غیرپولی (یه حرکت کلاسیک!). اما خب، هیچکدوم از این غولهای تکنولوژی قرار نیست چیزی رو دو دستی تقدیم ما کنن.
این یه مسابقه برای رسیدن به ماهه، و ما اون سگی هستیم که برای پرواز آزمایشی فرستادنش فضا.
اما اگه شما یه تولیدکننده محتوا هستید که صاحبنظره، مخاطب داره و خوشبختانه عمق برند و داراییهای خوبی هم در اختیار داره، جاتون امنه. هرچند که رفتار خزندههاشون (crawlers) دیگه داره از کنترل خارج میشه.

یکی از کاربردیترین نتایجی که ما به عنوان تولیدکننده محتوا میتونیم از این دادهها بگیریم، تغییر واضح در اینتنتها (قصد کاربر) است. برای سالها، ما با اینتنتهای ناوبری (navigational)، اطلاعاتی (informational)، تجاری (commercial) و تراکنشی (transactional) سروکار داشتیم.
حالا ما با اینتنت «انجام دادن» (Doing) یا «تولید کردن» (Generating) طرفیم. و این خیلی مهمه.
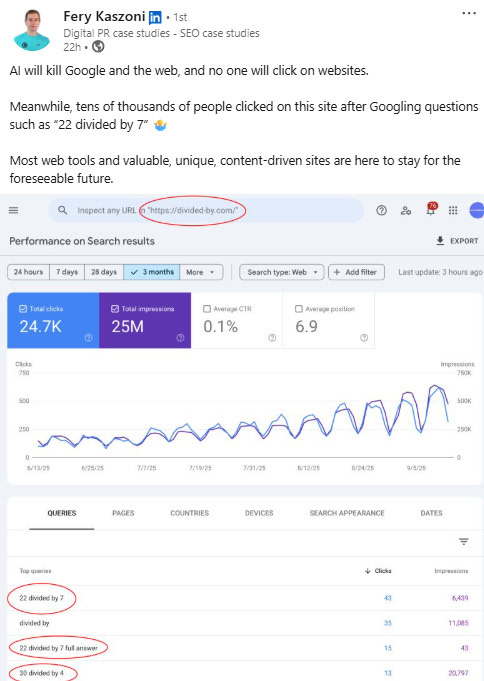
سئو برای تولیدکنندگان محتوا نمرده. اما ما باید کاری بیشتر از صرفاً انتشار محتوا انجام بدیم. باید از مزایای هوش مصنوعی دفاع کنیم، اما همزمان فاصلهمون رو هم باهاش حفظ کنیم.
به سرویس BBC Verify فکر کنید. محتوایی که ماشینها نمیتونن خلاصهش کنن، چون ارزش افزوده خیلی بالایی داره. ابزارها و داراییهای قابل لینک. نظرات واقعی از متخصصانی که در مرکز توجه قرار گرفتن.
اما رسوندن این کیفیت به مقیاس بالا کار سختیه. سئوی برنامهریزیشده (Programmatic SEO) میتونه ارزش فوقالعادهای ایجاد کنه. ابزارها هم همینطور. ابزارهایی که بارها و بارها به کوئریهای «اجرایی» کاربرا جواب میدن. ما باید چیزهایی بسازیم که خارج از مجموعه دادههای موجود، ارزش افزوده ایجاد کنن.
و اگه مخاطب شما عموماً جوونتر و خوشبینتره، باید بیشتر به این سمت حرکت کنید.
پاسخی بگذارید