
چطور میتوان از فشردهسازی برای تشخیص صفحات با کیفیت پایین استفاده کرد
موتورهای جستجو میتونن از فشردهسازی برای تشخیص صفحات با کیفیت پایین استفاده کنن. اگرچه این موضوع خیلی شناخته شده نیست، ولی دونستنش برای سئو مفیده.
مفهوم قابلیت فشردهسازی به عنوان یک معیار کیفیت، خیلی شناخته شده نیست، اما متخصصین سئو باید از اون آگاه باشن. موتورهای جستجو میتونن از قابلیت فشردهسازی صفحات وب برای شناسایی صفحات تکراری، صفحات دروازهای (doorway pages) با محتوای مشابه و صفحات با کلمات کلیدی تکراری استفاده کنن، که این برای سئو دانش مفیدی به حساب میاد.
اگرچه مقاله تحقیقاتی زیر نشون میده که استفاده موفقیتآمیز از ویژگیهای درون صفحهای برای تشخیص اسپم امکانپذیره، اما عدم شفافیت عمدی موتورهای جستجو باعث میشه که نشه با قطعیت گفت که آیا موتورهای جستجو از این تکنیکها یا تکنیکهای مشابه استفاده میکنن یا نه.
قابلیت فشردهسازی چیه؟
در دنیای کامپیوتر، قابلیت فشردهسازی به این معنیه که چقدر میشه حجم یک فایل (داده) رو کم کرد در حالی که اطلاعات اصلیش حفظ بشه. این کار معمولاً برای حداکثر استفاده از فضای ذخیرهسازی یا برای انتقال حجم بیشتری از دادهها روی اینترنت انجام میشه.
خلاصهای از فشردهسازی
فشردهسازی، کلمات و عبارتهای تکراری رو با ارجاعات کوتاهتر جایگزین میکنه و حجم فایل رو به طور قابل توجهی کاهش میده. موتورهای جستجو معمولاً صفحات وب نمایه شده رو به دلایل مختلفی مثل حداکثر استفاده از فضای ذخیرهسازی، کاهش پهنای باند و بهبود سرعت بازیابی، فشرده میکنن.
این یه توضیح ساده از نحوه کار فشردهسازیه:
- شناسایی الگوها:
الگوریتم فشردهسازی متن رو برای پیدا کردن کلمات، الگوها و عبارتهای تکراری اسکن میکنه
- کدهای کوتاهتر فضای کمتری میگیرن:
کدها و نمادها نسبت به کلمات و عبارتهای اصلی فضای ذخیرهسازی کمتری میگیرن، که باعث میشه حجم فایل کمتر بشه.
- ارجاعات کوتاهتر بیتهای کمتری مصرف میکنن:
“کد”ی که در اصل نماد کلمات و عبارتهای جایگزین شده است، داده کمتری نسبت به نسخههای اصلی مصرف میکنه.
یک مزیت اضافی استفاده از فشردهسازی اینه که میتونه برای شناسایی صفحات تکراری، صفحات دروازهای با محتوای مشابه و صفحات با کلمات کلیدی تکراری هم استفاده بشه.
مقاله تحقیقاتی درباره تشخیص اسپم
این مقاله تحقیقاتی از این جهت مهمه که توسط دانشمندان برجسته کامپیوتر نوشته شده که به خاطر پیشرفتهایی در زمینه هوش مصنوعی، محاسبات توزیع شده، بازیابی اطلاعات و زمینههای دیگه شناخته شدهان.
مارک ناجورک
یکی از نویسندگان این مقاله تحقیقاتی مارک ناجورک هست، یک دانشمند برجسته تحقیقاتی که در حال حاضر عنوان دانشمند تحقیقاتی ممتاز در گوگل دیپمایند رو داره. او یکی از نویسندگان مقالات TW-BERT هست، در تحقیقات برای افزایش دقت استفاده از بازخورد ضمنی کاربر مثل کلیکها مشارکت داشته و روی ایجاد بازیابی اطلاعات مبتنی بر هوش مصنوعی بهبود یافته کار کرده، و خیلی دستاوردهای مهم دیگه در زمینه بازیابی اطلاعات داشته.
دنیس فترلی
یکی دیگه از نویسندگان دنیس فترلی هست که در حال حاضر مهندس نرمافزار در گوگله. اون به عنوان یکی از مخترعان در یک پتنت برای الگوریتم رتبهبندی که از لینکها استفاده میکنه ثبت شده و به خاطر تحقیقاتش در زمینه محاسبات توزیع شده و بازیابی اطلاعات شناخته شده است.
اینا فقط دو نفر از محققان برجستهای هستن که به عنوان نویسندگان مقاله تحقیقاتی مایکروسافت در سال 2006 درباره شناسایی اسپم از طریق ویژگیهای محتوای درون صفحهای ذکر شدن. در بین چندین ویژگی محتوای درون صفحهای که این مقاله تحقیقاتی تحلیل میکنه، قابلیت فشردهسازی هست که اونا کشف کردن میتونه به عنوان یک طبقهبندی کننده برای نشون دادن اسپمی بودن یک صفحه وب استفاده بشه.
تشخیص صفحات وب اسپم از طریق تحلیل محتوا
اگرچه این مقاله تحقیقاتی در سال 2006 نوشته شده، اما یافتههاش همچنان برای امروز مرتبط هستن.
در اون زمان، مثل الان، افراد تلاش میکردن صدها یا هزاران صفحه وب مبتنی بر موقعیت مکانی رو رتبهبندی کنن که اساساً محتوای تکراری داشتن و فقط در نام شهر، منطقه یا ایالت با هم فرق داشتن. در اون زمان، مثل الان، متخصصین سئو اغلب صفحات وب رو برای موتورهای جستجو با تکرار بیش از حد کلمات کلیدی در عنوانها، متا دیسکریپشن، تیترها، متن لینکهای داخلی و محتوا میساختن تا رتبهبندی رو بهبود بدن.
بخش 4.6 مقاله تحقیقاتی توضیح میده:
“بعضی موتورهای جستجو به صفحاتی که چندین بار حاوی کلمات کلیدی جستجو هستن وزن بیشتری میدن. مثلاً برای یک عبارت جستجوی خاص، صفحهای که اون رو ده بار داره ممکنه رتبه بالاتری نسبت به صفحهای که فقط یک بار داره، بگیره. برای استفاده از این ویژگی موتورها، بعضی صفحات اسپم محتواشون رو چندین بار تکرار میکنن تا رتبه بالاتری بگیرن.”
مقاله تحقیقاتی توضیح میده که موتورهای جستجو صفحات وب رو فشرده میکنن و از نسخه فشرده شده برای ارجاع به صفحه وب اصلی استفاده میکنن. اونا متوجه شدن که مقدار زیاد کلمات تکراری منجر به سطح بالاتری از قابلیت فشردهسازی میشه. پس شروع کردن به آزمایش اینکه آیا ارتباطی بین سطح بالای قابلیت فشردهسازی و اسپم وجود داره یا نه.
اونا اینطور توضیح دادن:
“رویکرد ما در این بخش برای پیدا کردن محتوای تکراری داخل یک صفحه، فشردهسازی صفحه است؛ برای صرفهجویی در فضا و زمان دیسک، موتورهای جستجو اغلب صفحات وب رو بعد از نمایهسازی و قبل از اضافه کردن به کش صفحه، فشرده میکنن.
…ما تکرار صفحات وب رو با نسبت فشردهسازی، یعنی اندازه صفحه فشرده نشده تقسیم بر اندازه صفحه فشرده شده، اندازهگیری میکنیم. ما از GZIP استفاده کردیم… تا صفحات رو فشرده کنیم، که یک الگوریتم فشردهسازی سریع و موثره.”
قابلیت فشردهسازی بالا با اسپم ارتباط داره
نتایج تحقیق نشون داد که صفحات وب با نسبت فشردهسازی حداقل 4.0 تمایل داشتن صفحات وب با کیفیت پایین یا اسپم باشن. با این حال، بالاترین نرخهای قابلیت فشردهسازی کمتر سازگار شدن چون نقاط داده کمتری وجود داشت، که تفسیر رو سختتر میکرد.
شکل 9: شیوع اسپم نسبت به قابلیت فشردهسازی صفحه
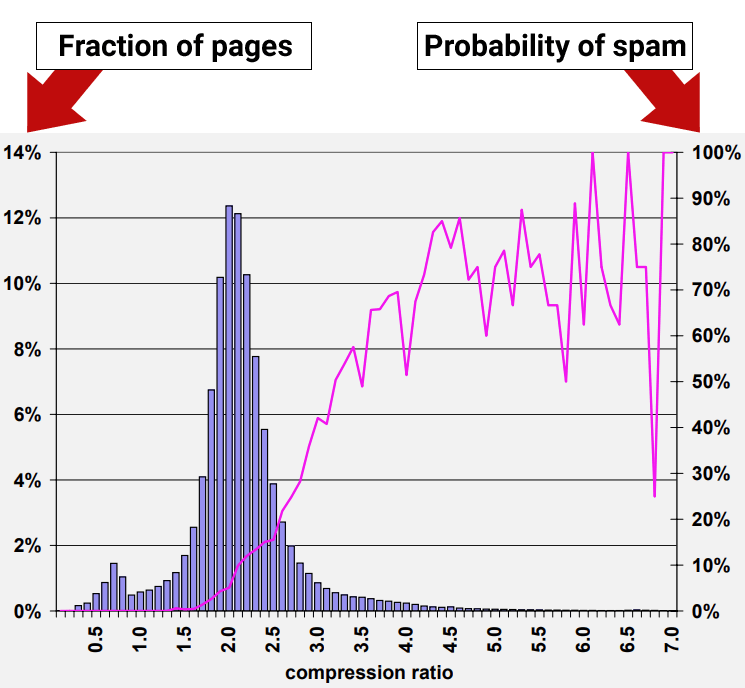
محققان نتیجه گرفتن:
“70% از همه صفحات نمونه با نسبت فشردهسازی حداقل 4.0 به عنوان اسپم تشخیص داده شدن.”
اما اونا همچنین کشف کردن که استفاده از نسبت فشردهسازی به تنهایی هنوز منجر به مثبت کاذب میشه، یعنی جایی که صفحات غیر اسپم به اشتباه به عنوان اسپم شناسایی میشن:
“روش تقریبی نسبت فشردهسازی که در بخش 4.6 توضیح داده شد بهترین عملکرد رو داشت، 660 (27.9%) از صفحات اسپم در مجموعه ما رو به درستی شناسایی کرد، در حالی که 2,068 (12.0%) از همه صفحات قضاوت شده رو اشتباه شناسایی کرد.
با استفاده از همه ویژگیهای ذکر شده، دقت طبقهبندی بعد از فرآیند اعتبارسنجی متقابل ده برابری امیدوارکننده است:
95.4% از صفحات قضاوت شده ما به درستی طبقهبندی شدن، در حالی که 4.6% اشتباه طبقهبندی شدن.
به طور دقیقتر، برای کلاس اسپم 1,940 صفحه از 2,364 صفحه به درستی طبقهبندی شدن. برای کلاس غیر اسپم، 14,440 صفحه از 14,804 صفحه به درستی طبقهبندی شدن. در نتیجه، 788 صفحه اشتباه طبقهبندی شدن.”
بخش بعدی یک کشف جالب درباره چگونگی افزایش دقت استفاده از سیگنالهای درون صفحهای برای شناسایی اسپم رو توضیح میده.
درک رتبه های با کیفیت
این مقاله تحقیقاتی چندین سیگنال درون صفحهای، از جمله قابلیت فشردهسازی رو بررسی کرد. اونا کشف کردن که هر سیگنال جداگانه (طبقهبندی کننده) میتونه بعضی اسپمها رو پیدا کنه اما تکیه کردن روی هر سیگنال به تنهایی منجر به علامتگذاری صفحات غیر اسپم به عنوان اسپم میشه، که معمولاً به اونا مثبت کاذب میگن.
محققان یک کشف مهم کردن که هر کسی که به سئو علاقه داره باید بدونه، و اون اینه که استفاده از چندین طبقهبندی کننده، دقت تشخیص اسپم رو افزایش داد و احتمال مثبت کاذب رو کاهش داد. به همون اندازه مهم، سیگنال قابلیت فشردهسازی فقط یک نوع اسپم رو شناسایی میکنه اما نه همه انواع اسپم رو.
نتیجهگیری اینه که قابلیت فشردهسازی یک روش خوب برای شناسایی یک نوع اسپمه اما انواع دیگه اسپم هست که با این سیگنال شناسایی نمیشن. انواع دیگه اسپم با سیگنال قابلیت فشردهسازی گیر نمیافتن.
این بخشیه که هر متخصص سئو و ناشر باید ازش آگاه باشه:
“در بخش قبلی، ما چندین روش تقریبی برای ارزیابی صفحات وب اسپم ارائه کردیم. یعنی، ما چندین ویژگی صفحات وب رو اندازهگیری کردیم و محدودههایی از این ویژگیها رو پیدا کردیم که با اسپم بودن یک صفحه ارتباط داشت. با این حال، وقتی به تنهایی استفاده میشن، هیچ تکنیکی بیشتر اسپمهای موجود در مجموعه دادههای ما رو بدون علامتگذاری بسیاری از صفحات غیر اسپم به عنوان اسپم کشف نمیکنه.
مثلاً، با در نظر گرفتن روش تقریبی نسبت فشردهسازی که در بخش 4.6 توضیح داده شد، که یکی از امیدوارکنندهترین روشهای ماست، میانگین احتمال اسپم برای نسبتهای 4.2 و بالاتر 72% است. اما فقط حدود 1.5% از همه صفحات در این محدوده قرار میگیرن. این عدد خیلی کمتر از 13.8% صفحات اسپمی هست که ما در مجموعه دادههامون شناسایی کردیم.”
پس، حتی با اینکه قابلیت فشردهسازی یکی از سیگنالهای بهتر برای شناسایی اسپم بود، هنوز هم نتونست همه انواع اسپم موجود در مجموعه دادهای که محققان برای آزمایش سیگنالها استفاده کردن رو کشف کنه.
ترکیب چندین سیگنال
نتایج بالا نشون داد که سیگنالهای منفرد کیفیت پایین دقت کمتری دارن. پس اونا استفاده از چندین سیگنال رو آزمایش کردن. چیزی که کشف کردن این بود که ترکیب چندین سیگنال درون صفحهای برای تشخیص اسپم منجر به نرخ دقت بهتر با طبقهبندی اشتباه کمتر صفحات به عنوان اسپم شد.
محققان توضیح دادن که استفاده از چندین سیگنال رو آزمایش کردن:
“یک راه برای ترکیب روشهای تقریبی ما اینه که به مشکل تشخیص اسپم به عنوان یک مسئله طبقهبندی نگاه کنیم. در این حالت، ما میخوایم یک مدل طبقهبندی (یا طبقهبندی کننده) بسازیم که با توجه به یک صفحه وب، از ویژگیهای صفحه به طور همزمان استفاده کنه تا اون رو در یکی از دو کلاس طبقهبندی کنه (امیدواریم به درستی): اسپم و غیر اسپم.”
اینا نتیجهگیریهاشون درباره استفاده از چندین سیگناله:
“ما جنبههای مختلف اسپم مبتنی بر محتوا در وب رو با استفاده از یک مجموعه داده دنیای واقعی از خزنده MSNSearch مطالعه کردیم. ما چندین روش تقریبی برای تشخیص اسپم مبتنی بر محتوا ارائه کردیم. بعضی از روشهای تشخیص اسپم ما موثرتر از بقیه هستن، اما وقتی به تنهایی استفاده میشن ممکنه همه صفحات اسپم رو شناسایی نکنن. به همین دلیل، ما روشهای تشخیص اسپم خودمون رو ترکیب کردیم تا یک طبقهبندی کننده C4.5 با دقت بالا بسازیم. طبقهبندی کننده ما میتونه 86.2% از همه صفحات اسپم رو به درستی شناسایی کنه، در حالی که تعداد خیلی کمی از صفحات مشروع رو به عنوان اسپم علامتگذاری میکنه.”
نکته کلیدی
شناسایی اشتباه “تعداد خیلی کمی از صفحات مشروع به عنوان اسپم” یک پیشرفت قابل توجه بود. بینش مهمی که همه افراد درگیر با سئو باید از این موضوع بگیرن اینه که یک سیگنال به تنهایی میتونه منجر به مثبت کاذب بشه. استفاده از چندین سیگنال دقت رو افزایش میده.
این به این معنیه که آزمایشهای سئو از سیگنالهای رتبهبندی یا کیفیت جداگانه نتایج قابل اعتمادی که بشه برای تصمیمگیریهای استراتژیک یا تجاری بهشون اعتماد کرد، به دست نمیدن.
نتیجهگیری
ما با قطعیت نمیدونیم که آیا قابلیت فشردهسازی در موتورهای جستجو استفاده میشه یا نه، اما این یک سیگنال آسون برای استفاده است که در ترکیب با سیگنالهای دیگه میتونه انواع ساده اسپم مثل هزاران صفحه دروازهای با نام شهر که محتوای مشابه دارن رو تشخیص بده. حتی اگه موتورهای جستجو از این سیگنال استفاده نکنن، این نشون میده که چقدر تشخیص این نوع دستکاری موتور جستجو آسونه و اینکه موتورهای جستجو امروزه کاملاً میتونن باهاش مقابله کنن.
اینا نکات کلیدی این مقاله هستن که باید به خاطر داشته باشید:
- صفحات دروازهای با محتوای تکراری به راحتی قابل تشخیص هستن چون نسبت به صفحات وب معمولی با نسبت بالاتری فشرده میشن.
- گروههای صفحات وب با نسبت فشردهسازی بالای 4.0 عمدتاً اسپم بودن.
- سیگنالهای کیفیت منفی وقتی به تنهایی برای گرفتن اسپم استفاده میشن میتونن به مثبت کاذب منجر بشن.
- در این آزمایش خاص، اونا کشف کردن که سیگنالهای کیفیت منفی درون صفحهای فقط انواع خاصی از اسپم رو میگیرن.
- وقتی به تنهایی استفاده میشه، سیگنال قابلیت فشردهسازی فقط اسپم نوع تکراری رو میگیره، در تشخیص سایر اشکال اسپم شکست میخوره و منجر به مثبت کاذب میشه.
- ترکیب سیگنالهای کیفیت دقت تشخیص اسپم رو بهبود میده و مثبت کاذب رو کاهش میده.
- موتورهای جستجو امروزه با استفاده از هوش مصنوعی مثل Spam Brain دقت بالاتری در تشخیص اسپم دارن.
مقاله تحقیقاتی رو بخونید که از صفحه Google Scholar مارک ناجورک لینک شده:
پاسخی بگذارید