
همکاریهای رسانهای هوش مصنوعی: چگونه بر دیده شدن برند شما در دنیای GenAI تأثیر میگذارند؟
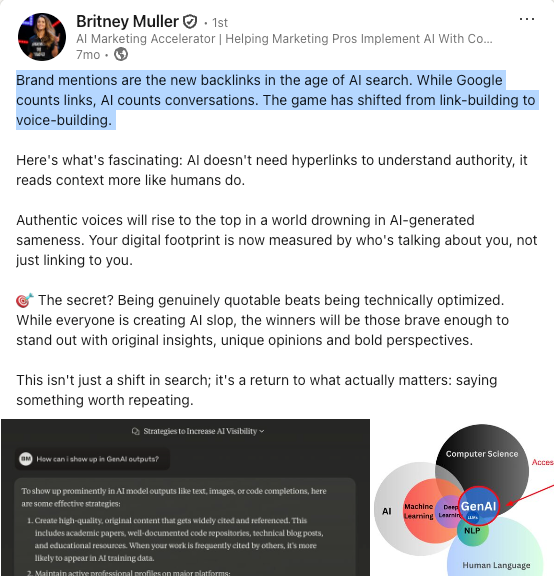
فقط ۷.۲٪ از دامنهها همزمان در نتایج AI Overviews گوگل و LLMها نمایش داده میشن. بیاین ببینیم این شکاف برای استراتژی سئوی شما چه معنایی داره.
توی یه مطالعه جدید که Search Engine Land و Fractl انجام دادن، مشخص شد که ۸۲٪ از مصرفکنندهها جستجوی مبتنی بر هوش مصنوعی رو مفیدتر از نتایج جستجوی سنتی (SERP) میدونن.
با اینکه ظهور بهینهسازی موتورهای تولید محتوا (GEO)، بازاریابها رو به تکاپو انداخته تا روی جدیدترین کلمات کلیدی این حوزه مسلط بشن، اما مدیران و رهبران فکری آژانسها دارن به یه نقطه مشترک میرسن.
فرقی نمیکنه با گوگل طرف باشیم یا هوش مصنوعی مولد، دیده شدن برند هنوز به دو تا چیز بستگی داره:
- عمق تخصص شما در موضوع اصلی فعالیتتون.
- گستردگی منشنهای برندتون (اشاره به نام برند شما در وب).
این دو تا در کنار هم، یه ردپای دیجیتال از اعتبار شما میسازن که هم الگوریتمها و هم گرافهای دانش (Knowledge Graphs) ازش برای نمایش برند شما استفاده میکنن.
اما مشکل اینجاست: بیشتر برندها هنوز دارن یه بازی یکبعدی رو انجام میدن.
اونها دارن مراکز محتوایی (Content Hubs) خودشون رو حول سوالات متداول و نیازهای بازار هدف بهینه میکنن، در حالی که سیگنالهای اعتبار خارج از سایت مثل منشنهای برند رو نادیده میگیرن؛ سیگنالهایی که دیده شدن در جستجوی هوش مصنوعی مولد رو تقویت میکنه.
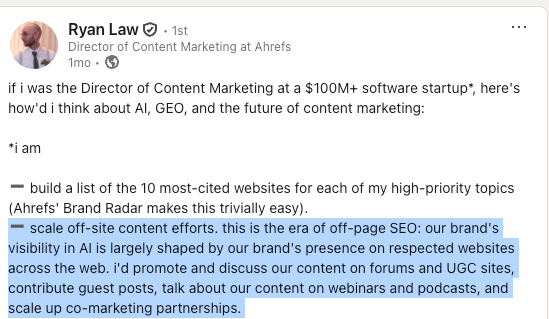
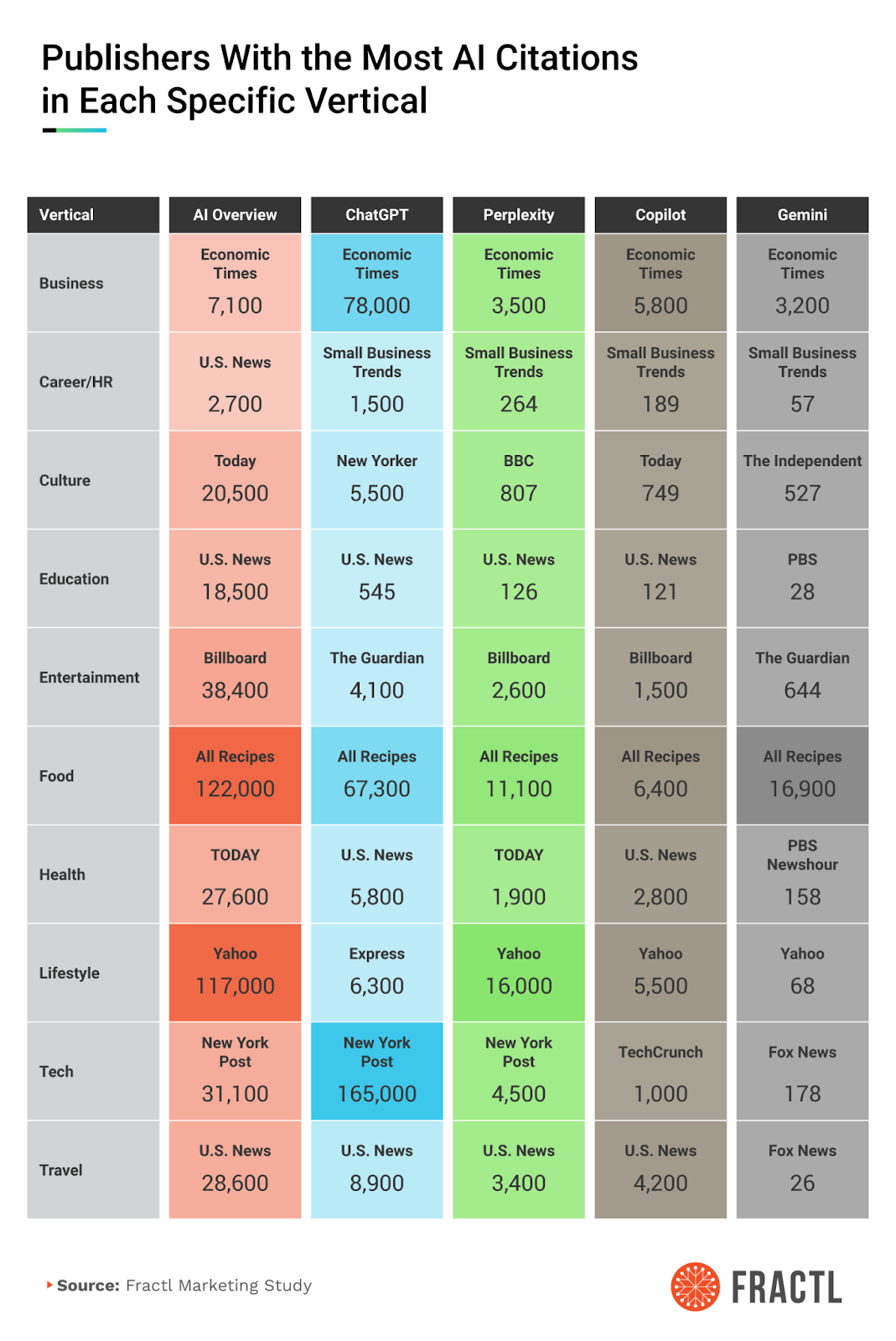
برای اینکه ضرورت یه رویکرد دوگانه رو نشون بدیم، همبنیانگذار من در Fractl، یعنی دن تینسکی (Dan Tynski)، اومد ۸۰۹۰ کلمه کلیدی رو در ۲۵ حوزه مختلف استخراج (scrape) کرد تا استنادات (citations) بین AI Overviews گوگل و LLMها (مثل GPT، Claude، Gemini و غیره) رو برای کوئریهای یکسان با هم مقایسه کنه.
نتیجهای که به دست اومد باید هر بازاریابی رو به فکر فرو ببره: فقط ۷.۲٪ از دامنهها در هر دو سیستم نمایش داده شدن.

از بین ۲۲,۴۱۰ دامنه منحصربهفردی که شناسایی کردیم:
- ۱۵,۸۴۸ دامنه (۷۰.۷٪) فقط در AI Overviews گوگل ظاهر شدن.
- ۴,۹۵۱ دامنه (۲۲.۱٪) فقط در مدلهای پایه LLM دیده شدن.
- ۱,۶۱۱ دامنه (۷.۲٪) در هر دو سیستم حضور داشتن.
خب، این برای بازاریابها چه معنیای داره؟
۱. AI Overviews گوگل هنوز به نفع غولهای قدیمی عمل میکنه
جای تعجب نیست که سیستم هوش مصنوعی گوگل به شدت به همون دامنههای معتبری که عادت داشتیم در صفحات نتایج جستجو ببینیم، تمایل داره.
وبسایتهای با اعتبار بالا که مجموعه محتوای قوی و پروفایل بکلینک قدرتمندی داشتن، در AI Overviews گوگل حسابی جولان میدادن.
این ۱۵,۸۴۸ دامنه عمدتاً شامل این موارد بودن:
- سایتهای خبری و اطلاعاتی معتبر (مثل BBC، Yahoo، CNN).
- شبکههای اجتماعی با رویکرد آموزشی (مثل Reddit و YouTube).
- منابع مرجع معتبر (مثل Wikipedia و مجلات علمی معتبر).
- وبسایتهای دولتی و سازمانی (با دامنههای .gov و .edu).
۲. ناشرانی که دیده شدن برند و اعتبار رو در هوش مصنوعی مولد هدایت میکنن
داستان ۴,۹۵۱ دامنهای که فقط در LLMها حضور داشتن، کاملاً متفاوته.
این دامنهها به طور قابل توجهی کوچکتر هستن – سه برابر کمتر از اونهایی که در AI Overviews بودن – و نشون میدن که LLMها واقعاً برای چه چیزهایی ارزش قائلن:
- روزنامهنگاری تحقیقی از ناشران خبری جریان اصلی که اخبار روز رو پوشش میدن و توسط جستجوهای RAG استخراج میشن (مثلاً USA Today، CNBC، The New York Times).
- متخصصان حوزههای خاص (Niche) که تخصص عمیقی در یک حوزه مشخص از خودشون نشون میدن (مثلاً Edmunds برای خودرو، Investopedia برای سرمایهگذاری، All Recipes برای آشپزی، Wired برای تکنولوژی).
- پلتفرمها و جوامع آموزشی که برای یادگیری بهینه شدن (Reddit، Github، Coursera، Khan Academy و مراکز دانشگاهی).
- پورتالهای داده معتبر صنعتی، مثل مجلات علمی معتبر، پتنتها، استانداردها و رونوشتهای دادگاهها و دولت.
در نهایت، به نظر میرسه که مدلهای پایه، ناشرانی رو در اولویت قرار میدن که عمق موضوعی رو به گستردگی موضوعی ترجیح میدن و برای ارزش آموزشی و شفافیت مفاهیم، بیشتر از سیگنالهای اعتبار وب سنتی اهمیت قائلن.
ممکنه سایت شما با دامین آتوریتی ۹۰ برای ChatGPT نامرئی باشه، اگه نتونه مفاهیم رو به طور واضح و موثر توضیح بده و فقط در رتبهبندی خوب عمل کنه.
بر اساس تحلیل ما، در اینجا پنج قانونی وجود داره که تعیین میکنه آیا محتوای شما در پلتفرمهای هوش مصنوعی مورد استناد قرار میگیره یا نه:
اعتبار، حلقههای اعتماد در LLMها ایجاد میکنه
استانداردهای بالای سردبیری و راستیآزمایی انسانی (مثل NPR، NYT) باعث میشه که محتوا بیشتر لینک بگیره، مورد استناد قرار بگیره و مجدداً کراول بشه.
کراولهای مکرر به این معنیه که عبارتبندی اونها به زبان «پیشفرض» مدلها برای پاسخگویی تبدیل میشه.
اقدامات پیشنهادی:
- محتوای مبتنی بر منبع، خوب ویرایش شده و استاندارد منتشر کنید.
- از اتاقهای خبر با اعتبار بالا لینک بگیرید.
- تازگی و بهروز بودن محتوا رو حفظ کنید تا دوباره کراول بشه.
اگه خوندن سریعش (skim) آسون باشه، آموزشش هم آسونه
مدلها عاشق الگوها هستن، پس به آموزشهای گامبهگام، بلوکهای تعاریف، لیستهای مرتب و جداول مقایسهای فکر کنید که از طرحبندیهای استانداردی استفاده میکنن که برای ماشینها قابل درک هستن.
اقدامات پیشنهادی:
- قالبهای مقالات خودتون رو استاندارد کنید.
- از تگهای هدر، اسکیما، لیستهای بالتپوینت، بخش سوالات متداول و خلاصههای TL;DR (خیلی طولانیه، نخوندم) استفاده کنید.
متخصصان حوزههای خاص، نقشه ذهنی مدل رو آموزش میدن
متخصصان حوزههای خاص (مثل Edmunds برای خودرو، Mayo برای سلامت و غیره) وب رو با آپدیتهای بسیار ساختاریافته و پر از محتوای عمیق پر میکنن.
مدلها یاد میگیرن: «وقتی موضوع خودروئه، برو سراغ Edmunds؛ وقتی سرمایهگذاریه، برو سراغ Investopedia.»
اقدامات پیشنهادی:
- کاملترین منبع دانش در صنعت خودتون رو بسازید.
- آموزشهای گامبهگام، بلوکهای تعاریف، جداول مقایسهای و محتواهای ساختاریافتهای که مدلها دوست دارن بهشون استناد کنن، ایجاد کنید.
- متخصصان خودتون رو به رسانهها معرفی کنید تا ارتباط و تخصص شما رو تقویت کنن.
تکرار و بازنشر محتوا (Syndication) = جاذبه آماری
رسانههای بزرگ نقلقول میشن، بازنشر میشن و تجمیع میشن – هر کپی از محتوای اونها، الگوهای کلمات و چارچوبهای روایی رو تقویت میکنه.
یه خبر از آسوشیتدپرس (AP) به ۲۰۰ کپی محلی تبدیل میشه. حالا اون کلمات همه جای رژیم غذایی مدل هوش مصنوعی وجود داره.
بازنشر محتوا روشیه که یک واقعیت در دنیای هوش مصنوعی به «همون واقعیت» تبدیل میشه.
اقدامات پیشنهادی:
- شبکههای بازنشر محتوا، خبرگزاریها و داستانهای مبتنی بر داده رو که قابلیت استفاده مجدد دارن، هدف قرار بدید.
- داراییهای آماده کپیپیست (مثل نمودارها، آمارها به صورت بالتپوینت و کدهای embed) فراهم کنید.
سوگیری تجاری آمریکا، لنز دانش رو منحرف میکنه
مجموعه دادههای آموزشی به دلیل همکاریهای فعلی، بیش از حد روی انگلیسی آمریکایی، اخبار مبتنی بر تبلیغات و ناشران تجاری متمرکز شدن.
منابع غیرآمریکایی، غیرانگلیسی، دانشگاهی یا سازمانهای غیردولتی کمتر مورد توجه قرار میگیرن – که منجر به پاسخهای فرهنگی محدود میشه.
اقدام پیشنهادی:
- در همون ناشرانی که پلتفرمهای هوش مصنوعی مولد برای آموزش مدلهاشون ازشون استفاده میکنن، منشن رسانهای بگیرید.
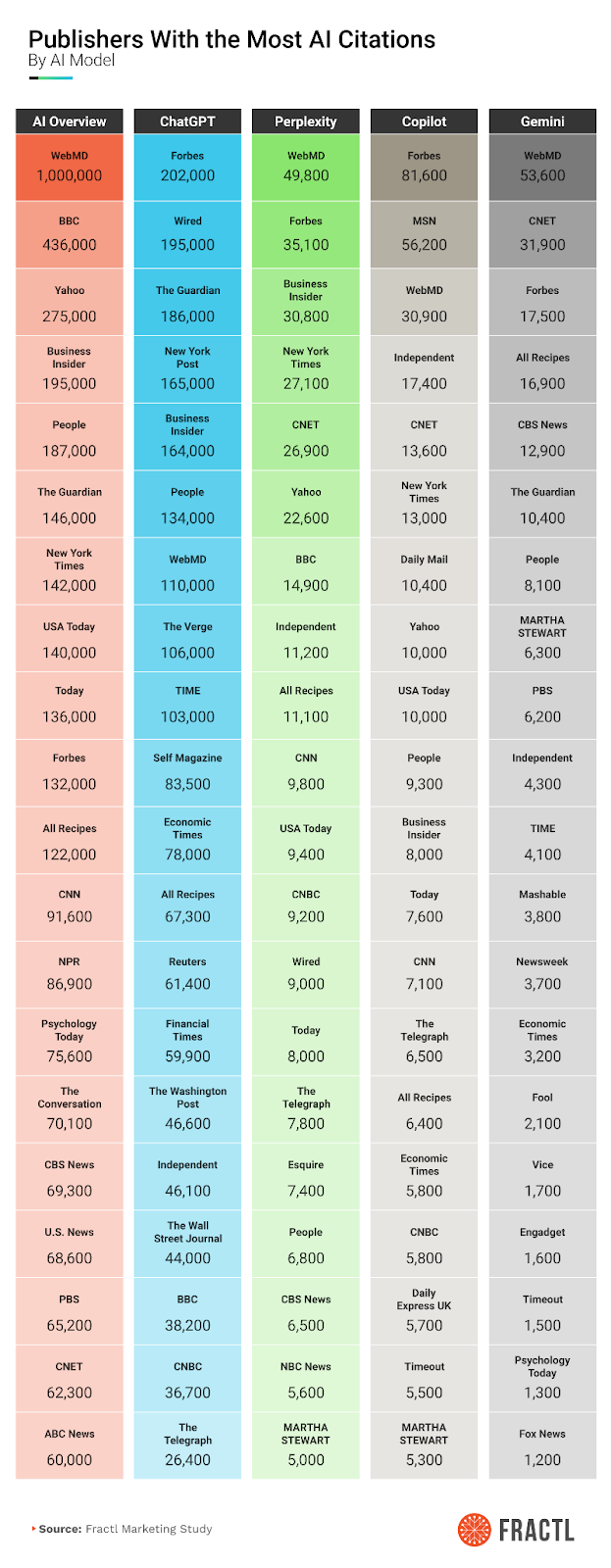
فراتر از استراتژیهای محتوایی که گرافهای دانش پلتفرمهای هوش مصنوعی مولد رو شکل میدن، من همچنین میخواستم بفهمم که کدوم غولهای رسانهای بیشتر از بقیه مورد استناد قرار میگیرن.
از اونجایی که من مسئول تیم رسانهای آژانسمون هستم، برام خیلی مهم بود که تیم روابط عمومی دیجیتالم رو برای هدف قرار دادن ناشرانی که بیشترین استنادات رو در حوزه تخصصی هر مشتری دارن، در اولویت قرار بدم.
من شروع به تحقیق در مورد «همکاریهای رسانهای هوش مصنوعی» و قراردادهای مجوزی کردم که OpenAI، Perplexity و بقیه در چند سال گذشته ترتیب داده بودن.
این همکاریها سه اهرم اصلی رو به حرکت درمیارن که شبکه عصبی داخلی و گراف دانش یک مدل رو در مورد صنعت و برند شما شکل میدن:
- پوشش (Coverage): قانونی بودن، عمق و بهروز بودن آرشیوهایی که مدل میتونه اونها رو کراول و بازاستفاده کنه.
- زمینه (Context): تعداد دفعاتی که اون منابع در دادههای پیشآموزش، ایندکسهای بازیابی، مجموعههای ارزیابی و فرآیندهای ایمنی ظاهر میشن.
- اعتبار (Credibility): وزن اعتمادی که یک سیستم هنگام بررسی متقابل و رتبهبندی اون منابع در زمان پاسخگویی بهشون اختصاص میده.
وقتی یک شبکه از ناشران با یک مدل هوش مصنوعی همکاری میکنه، دیگه فقط یه وبسایت معمولی نیست که هوش مصنوعی بتونه بخوندش – بلکه به یک منبع معتبر تبدیل میشه که مدل به طور فعال ازش یاد میگیره و دوباره ازش استفاده میکنه.
با گذشت زمان، اون محتوا به یک نقطه عطف در نقشه دانش سیستم تبدیل میشه و نحوه درک مدل از موضوعات، برندها و اعتبار رو شکل میده.
همچنان که دستیارهای هوش مصنوعی «خطوط لوله پاسخ» ساختاریافتهتری میسازن، این شبکههای ناشران یک مزیت واقعی دارن – داستانهای اونها به احتمال زیاد مورد استناد، تکرار و به خاطر سپرده میشن.
به عنوان یک برند، اگه داستان شما خارج از این شبکههای ناشران باشه، باید زمان و بودجه بیشتری رو صرف کنید تا خودتون رو به عنوان یک منبع معتبر در پاسخهای هوش مصنوعی مولد جا بندازید.
۴. از قطار هیجانانگیز Reddit پیاده شید
همچنان که هوش مصنوعی مولد به آموزش خودش با دادههای عمومی وب ادامه میده، همه پلتفرمها ارزش یکسانی ندارن.
اگه اعتماد به پول رایج جدید اینترنت تبدیل بشه، اون وقته که منبع دادهها، و نه فقط مقیاس اونها، ارزش بلندمدتشون رو در آموزش مدلها تعیین میکنه.
ممکنه Reddit، Quora و سایر پلتفرمهای پر از محتوای تولید شده توسط کاربر (UGC) امروز بر استنادات هوش مصنوعی مسلط باشن.
اما اونها همچنین در برابر آلودگی، حلقههای سوگیری و نویز مصنوعی آسیبپذیرترن.
با بدتر شدن نسبت سیگنال به محتوای بیارزش (slop)، این منابع ممکنه با یک اصلاح اعتبار مواجه بشن، زمانی که مدلها شروع به وزندهی بر اساس منشأ، تنوع و قابلیت تأیید کنن.
ما یک چارچوب برای پیشبینی منابع معتبر ساختیم تا مشخص کنیم کدوم نوع از ناشران در بهترین موقعیت برای حفظ نفوذ در اکوسیستمهای هوش مصنوعی مولد قرار دارن.
با امتیازدهی به پلتفرمها بر اساس هفت سیگنال اعتماد – از کمیابی و قابلیت تأیید گرفته تا شفافیت قانونی و طول عمر – میتونیم پیشبینی کنیم که کدوم محیطهای رسانهای به احتمال زیاد نسل بعدی دادههای آموزشی رو تغذیه خواهند کرد.


خلاصه کلام: برندهایی که امروز روی پوشش معتبر، تولید شده توسط انسان و از نظر قانونی شفاف سرمایهگذاری میکنن، به صداهای بنیادی تبدیل خواهند شد که مدلهای فردا به اونها تکیه خواهند کرد.
۵. GEO برای استراتژی سئوی شما در سال ۲۰۲۶ چه معنایی داره؟
برندهایی که در سال ۲۰۲۶ بر بهینهسازی موتورهای تولید محتوا مسلط میشن، به دنبال رتبهها نخواهند بود. اونها اعتبار رو معماری خواهند کرد.
اونها استراتژیهایی رو در اولویت قرار میدن که با ایجاد دیدهشدن در کانالهای مختلف، یک ردپای دیجیتال به اندازه کافی قوی بسازن تا بتونن همزمان بر گرافهای دانش، الگوریتمها و مخاطبان تأثیر بذارن.
اگه میخواید اون برند باشید، این برنامه اقدام شماست:
لاین خودتون رو انتخاب کنید و در اون استاد شید
دیدهشدن در دنیای هوش مصنوعی مولد به عمق پاداش میده، نه گستردگی.
بهترینها – مثل WebMD، All Recipes، U.S. News – حوزههای تخصصی خودشون رو به طور کامل در اختیار دارن.
زیرشاخه خودتون رو مشخص کنید و کاملترین پایگاه دانش رو در اون بسازید.
برای ساختار مهندسی کنید
LLMها به چیزی استناد میکنن که بتونن تجزیهش کنن.
قالبهای محتوای خودتون رو استاندارد کنید – تعاریف، سوالات متداول، آموزشها، جداول مقایسهای – و از نشانهگذاری اسکیمای واضح استفاده کنید.
چیزی که برای ماشینها خوبه، معمولاً برای انسانها هم خوبه.
از «جاذبه آماری» استفاده کنید
برای هر مطالعه مبتنی بر داده، مسیرهای بازنشر (syndication) رو مهندسی کنید.
هر منشن بازنشر شده، نمودار embed شده و نقلقول بازاستفاده شده، اعتبار رو چند برابر میکنه.
کاری کنید که روزنامهنگاران و پلتفرمهای هوش مصنوعی مولد بتونن به راحتی از زبان، نمودارها و بینشهای شما استفاده کنن.
یک بازنشر میتونه به ۲۰۰ استناد در سراسر وب تبدیل بشه.
اکوسیستم همکاریهای خودتون رو زیر نظر داشته باشید
مدلهای هوش مصنوعی به محتوای گروههای رسانهای معتبر (مثل TIME، FT Group، Guardian Media، Axel Springer) علاقه دارن.
در این شبکهها جایگاه کسب کنید تا شانس خودتون رو برای قرار گرفتن در خطوط لوله بازیابی اطلاعات افزایش بدید.
جهانی فکر کنید، نه فقط گوگلی
رسانههای آمریکایی بر دادههای آموزشی هوش مصنوعی تسلط دارن، اما محتوای چندزبانه و منطقهای میتونه شکافهای فرهنگی رو پر کنه.
داراییهای خودتون رو بومیسازی و ترجمه کنید تا دیدهشدن شما در مدلهای جهانی بهبود پیدا کنه.
برای اعتماد بازسازی کنید
دادههای بررسی شده توسط همتایان، منابع شفاف و محتوای نوشته شده توسط متخصصان، در ارزش آموزشی از محتوای بیکیفیت بهینهشده برای سئو بهتر عمل میکنن.
در جستجوی هوش مصنوعی مولد، اعتبار، فاکتور رتبهبندی جدیده.
اعتبار، برنده این مسابقه است
تکامل بعدی جستجو، مسابقهای برای کلمات کلیدی نیست.
بلکه مسابقهای برای زمینه، اعتبار و پوشش رسانهایه.
همین حالا ردپای دیجیتال اعتبار خودتون رو از طریق منشنهای برند بسازید، در حالی که رقبای شما هنوز دارن اصول اولیه ساختار سایت و مراکز محتوایی رو بهینه میکنن.
وقتی اونها قوانین جدید کشف شدن رو بفهمن، گرافهای دانش از قبل میدونن که به چه کسی اعتماد کنن.
پاسخی بگذارید