
راهنمای شناخت مدلهای زبانی بزرگ (LLMs) از صفر تا صد برای سئوکارها!
هر چیزی که سئوکارها باید در مورد مدلهای زبان بزرگ، پردازش زبان طبیعی و مفاهیم مرتبط با اونها بدونن، اینجا جمع شده.
باید از مدلهای زبان بزرگ برای تحقیق کلمات کلیدی استفاده کنم؟ این مدلها واقعاً میتونن فکر کنن؟ ChatGPT رفیق منه؟
اگه این سوالها ذهنت رو درگیر کرده، این راهنما دقیقاً برای خودته.
اینجا قراره هر چیزی که سئوکارها باید در مورد مدلهای زبان بزرگ (LLM)، پردازش زبان طبیعی (NLP) و هرچیزی که به این دوتا ربط داره بدونن رو پوشش بدیم.
مدلهای زبان بزرگ، پردازش زبان طبیعی و مفاهیم دیگه به زبون ساده
دو راه برای وادار کردن یه نفر به انجام کاری وجود داره: یا بهش بگی اون کار رو انجام بده، یا امیدوار باشی خودش انجامش بده.
توی دنیای علوم کامپیوتر، برنامهنویسی مثل اینه که به ربات بگی چیکار کنه، در حالی که یادگیری ماشین (Machine Learning) مثل اینه که امیدوار باشی ربات خودش اون کار رو انجام بده. حالت اول میشه یادگیری ماشینِ نظارتشده (Supervised) و حالت دوم میشه یادگیری ماشینِ نظارتنشده (Unsupervised).
پردازش زبان طبیعی (NLP) روشی برای تبدیل متن به اعداد و بعد تحلیل اون با کامپیوترهاست.
کامپیوترها الگوهای کلمات رو تحلیل میکنن و هرچقدر پیشرفتهتر میشن، الگوهای روابط بین کلمات رو هم تحلیل میکنن.
یک مدل یادگیری ماشین زبان طبیعیِ نظارتنشده رو میشه با انواع مختلفی از مجموعه دادهها (datasets) آموزش داد.
مثلاً، اگه یه مدل زبانی رو با میانگین نقدهای فیلم «دنیای آب» (Waterworld) آموزش بدی، نتیجهاش مدلی میشه که توی نوشتن (یا درک) نقدهای مربوط به همین فیلم خوب عمل میکنه.
اما اگه همون مدل رو فقط با دو تا نقد مثبتی که من برای فیلم «دنیای آب» نوشتم آموزش بدی، اون مدل فقط همون نقدهای مثبت رو میفهمه.
مدلهای زبان بزرگ (LLMs) شبکههای عصبی با بیش از یک میلیارد پارامتر هستن. این مدلها اونقدر بزرگن که خیلی عمومیتر عمل میکنن. اونها فقط با نقدهای مثبت و منفی فیلم «دنیای آب» آموزش ندیدن، بلکه با کامنتها، مقالات ویکیپدیا، سایتهای خبری و کلی چیز دیگه هم آموزش دیدن.
پروژههای یادگیری ماشین خیلی با مفهوم «زمینه» (context) سروکار دارن؛ یعنی چیزهایی که در یک زمینه خاص قرار دارن یا خارج از اون هستن.
اگه یه پروژه یادگیری ماشین داشته باشی که کارش شناسایی حشراته و بهش عکس یه گربه رو نشون بدی، قطعاً توی اون پروژه خوب عمل نمیکنه.
به همین دلیله که چیزهایی مثل ماشینهای خودران اینقدر سخته: اینقدر مشکلات خارج از زمینه وجود داره که تعمیم دادن اون دانش خیلی دشوار میشه.
مدلهای زبان بزرگ (LLM) به نظر میرسه و میتونن خیلی عمومیتر از پروژههای یادگیری ماشین دیگه باشن. دلیلش هم حجم عظیم دادهها و توانایی پردازش میلیاردها رابطه مختلفه.
حالا بیاین در مورد یکی از فناوریهای انقلابی که این امکان رو فراهم کرده صحبت کنیم: ترنسفورمرها (Transformers).
توضیح ترنسفورمرها از صفر
ترنسفورمرها یه نوع معماری شبکه عصبی هستن که حوزه پردازش زبان طبیعی (NLP) رو متحول کردن.
قبل از ترنسفورمرها، بیشتر مدلهای NLP به تکنیکی به اسم شبکههای عصبی بازگشتی (RNNs) متکی بودن که متن رو به صورت متوالی، کلمه به کلمه، پردازش میکرد. این رویکرد محدودیتهای خودشو داشت، مثلاً کند بود و برای مدیریت وابستگیهای دوربرد در متن به مشکل میخورد.
ترنسفورمرها این بازی رو عوض کردن.
در مقاله برجسته سال ۲۰۱۷ با عنوان «توجه، تمام آن چیزی است که نیاز دارید» (Attention is All You Need)، واسوانی و همکارانش معماری ترنسفورمر رو معرفی کردن.
ترنسفورمرها به جای پردازش متوالی متن، از مکانیزمی به اسم «خود-توجهی» (self-attention) برای پردازش موازی کلمات استفاده میکنن که بهشون اجازه میده وابستگیهای دوربرد رو با کارایی بیشتری درک کنن.
معماریهای قبلی شامل RNNها و الگوریتمهای حافظه طولانی کوتاه-مدت (LSTM) بودن.
مدلهای بازگشتی مثل اینها معمولاً برای کارهایی که با دنبالههای داده سروکار دارن (مثل متن یا گفتار) استفاده میشدن (و هنوز هم میشن).
اما این مدلها یه مشکلی دارن. اونها فقط میتونن دادهها رو تکهتکه پردازش کنن که این باعث کندی و محدودیت در حجم دادههای قابل پردازش میشه. این پردازش متوالی واقعاً توانایی این مدلها رو محدود میکنه.
مکانیزمهای توجه (Attention) به عنوان روشی متفاوت برای پردازش دادههای دنبالهای معرفی شدن. این مکانیزمها به مدل اجازه میدن که به همه تکههای داده به صورت همزمان نگاه کنه و تصمیم بگیره کدوم تکهها مهمترن.
این میتونه توی خیلی از کارها مفید باشه. با این حال، بیشتر مدلهایی که از «توجه» استفاده میکردن، از پردازش بازگشتی هم بهره میبردن.
یعنی، اونها روشی برای پردازش همزمان دادهها داشتن، ولی هنوز باید به ترتیب بهشون نگاه میکردن. مقاله واسوانی و همکارانش این ایده رو مطرح کرد: «چی میشه اگه فقط از مکانیزم توجه استفاده کنیم؟»
توجه راهی برای مدله که موقع پردازش، روی بخشهای خاصی از دنباله ورودی تمرکز کنه. مثلاً وقتی ما یه جمله رو میخونیم، بسته به زمینه و چیزی که میخوایم بفهمیم، به طور طبیعی به بعضی کلمات بیشتر از بقیه توجه میکنیم.
اگه به یه ترنسفورمر نگاه کنی، مدل برای هر کلمه در دنباله ورودی یه امتیاز محاسبه میکنه، بر اساس اینکه اون کلمه چقدر برای درک معنای کلی دنباله مهمه.
بعد، مدل از این امتیازها برای وزندهی به اهمیت هر کلمه در دنباله استفاده میکنه و بهش اجازه میده روی کلمات مهمتر بیشتر و روی کلمات کماهمیتتر کمتر تمرکز کنه.
این مکانیزم توجه به مدل کمک میکنه تا وابستگیها و روابط دوربرد بین کلماتی که ممکنه در دنباله ورودی از هم دور باشن رو بدون نیاز به پردازش متوالی کل دنباله، درک کنه.
همین ویژگیه که ترنسفورمر رو برای کارهای پردازش زبان طبیعی اینقدر قدرتمند میکنه، چون میتونه به سرعت و با دقت معنای یک جمله یا یک دنباله طولانیتر از متن رو بفهمه.
بیاین یه مثال بزنیم از مدل ترنسفورمری که جمله «گربه روی حصیر نشست» (The cat sat on the mat) رو پردازش میکنه.
هر کلمه در جمله به صورت یک بردار (vector)، یعنی مجموعهای از اعداد، با استفاده از یک ماتریس امبدینگ (embedding) نشون داده میشه. فرض کنیم امبدینگ هر کلمه اینطوریه:
- The: [0.2, 0.1, 0.3, 0.5]
- cat: [0.6, 0.3, 0.1, 0.2]
- sat: [0.1, 0.8, 0.2, 0.3]
- on: [0.3, 0.1, 0.6, 0.4]
- the: [0.5, 0.2, 0.1, 0.4]
- mat: [0.2, 0.4, 0.7, 0.5]
بعد، ترنسفورمر برای هر کلمه در جمله بر اساس رابطهاش با تمام کلمات دیگه، یک امتیاز محاسبه میکنه.
این کار با استفاده از ضرب داخلی (dot product) امبدینگ هر کلمه با امبدینگ تمام کلمات دیگه در جمله انجام میشه.
مثلاً برای محاسبه امتیاز کلمه «cat»، ضرب داخلی امبدینگ اون رو با امبدینگ کلمات دیگه حساب میکنیم:
- “The cat“: 0.2*0.6 + 0.1*0.3 + 0.3*0.1 + 0.5*0.2 = 0.24
- “cat sat“: 0.6*0.1 + 0.3*0.8 + 0.1*0.2 + 0.2*0.3 = 0.31
- “cat on“: 0.6*0.3 + 0.3*0.1 + 0.1*0.6 + 0.2*0.4 = 0.39
- “cat the“: 0.6*0.5 + 0.3*0.2 + 0.1*0.1 + 0.2*0.4 = 0.42
- “cat mat“: 0.6*0.2 + 0.3*0.4 + 0.1*0.7 + 0.2*0.5 = 0.32
این امتیازها نشوندهنده میزان ارتباط هر کلمه با کلمه «cat» هستن. بعد ترنسفورمر از این امتیازها برای محاسبه مجموع وزنی امبدینگ کلمات استفاده میکنه، که وزنها همون امتیازها هستن.
این کار یک بردار زمینه (context vector) برای کلمه «cat» ایجاد میکنه که روابط بین تمام کلمات جمله رو در نظر میگیره. این فرآیند برای هر کلمه در جمله تکرار میشه.
اینجوری بهش فکر کن که ترنسفورمر بر اساس نتیجه هر محاسبه، بین هر کلمه در جمله یه خط میکشه. بعضی خطها محکمتر و بعضی ضعیفترن.
ترنسفورمر نوع جدیدی از مدله که فقط از «توجه» بدون هیچ پردازش بازگشتی استفاده میکنه. این باعث میشه خیلی سریعتر باشه و بتونه دادههای بیشتری رو پردازش کنه.
GPT چطور از ترنسفورمرها استفاده میکنه؟
شاید یادتون باشه که در اعلامیه BERT گوگل، اونها با افتخار گفتن که این مدل به جستجو اجازه میده تا زمینه کامل یک ورودی رو درک کنه. این شبیه به روشیه که GPT میتونه از ترنسفورمرها استفاده کنه.
بیاین از یه تشبیه استفاده کنیم.
تصور کنین یک میلیون میمون دارین که هر کدوم جلوی یه کیبورد نشستن.
هر میمون به طور تصادفی کلیدها رو فشار میده و رشتههایی از حروف و نمادها تولید میکنه.
بعضی از این رشتهها کاملاً بیمعنی هستن، در حالی که بعضی دیگه ممکنه شبیه کلمات واقعی یا حتی جملات منسجم باشن.
یه روز، یکی از مربیهای سیرک میبینه که یه میمون نوشته «بودن یا نبودن»، برای همین به اون میمون یه جایزه میده.
میمونهای دیگه اینو میبینن و سعی میکنن از اون میمون موفق تقلید کنن، به امید اینکه خودشون هم جایزه بگیرن.
با گذشت زمان، بعضی میمونها شروع به تولید مداوم رشتههای متنی بهتر و منسجمتر میکنن، در حالی که بقیه همچنان چرت و پرت تولید میکنن.
در نهایت، میمونها میتونن الگوهای منسجم در متن رو تشخیص بدن و حتی ازشون تقلید کنن.
مدلهای زبان بزرگ (LLM) یه برتری نسبت به میمونها دارن، چون اول با میلیاردها قطعه متن آموزش دیدن. اونها از قبل الگوها رو دیدن. اونها همچنین بردارها و روابط بین این قطعات متن رو درک میکنن.
این یعنی میتونن از اون الگوها و روابط برای تولید متن جدیدی استفاده کنن که شبیه زبان طبیعی باشه.
GPT که مخفف «ترنسفورمر از پیش آموزشدیده مولد» (Generative Pre-trained Transformer) هست، یک مدل زبانیه که از ترنسفورمرها برای تولید متن زبان طبیعی استفاده میکنه.
این مدل با حجم عظیمی از متون اینترنتی آموزش دیده که بهش اجازه داده الگوها و روابط بین کلمات و عبارات در زبان طبیعی رو یاد بگیره.
این مدل اینطوری کار میکنه که یک پرامپت (prompt) یا چند کلمه از متن رو به عنوان ورودی میگیره و با استفاده از ترنسفورمرها پیشبینی میکنه که بر اساس الگوهایی که از دادههای آموزشیاش یاد گرفته، چه کلماتی باید در ادامه بیان.
مدل به تولید متن کلمه به کلمه ادامه میده و از زمینه کلمات قبلی برای اطلاعرسانی به کلمات بعدی استفاده میکنه.
GPT در عمل
یکی از مزایای GPT اینه که میتونه متن زبان طبیعی تولید کنه که بسیار منسجم و از نظر زمینهای مرتبطه.
این کاربردهای عملی زیادی داره، مثل تولید توضیحات محصول یا پاسخ به سوالات خدمات مشتری. همچنین میتونه به صورت خلاقانه استفاده بشه، مثلاً برای سرودن شعر یا نوشتن داستانهای کوتاه.
اما، این فقط یک مدل زبانیه. با دادهها آموزش دیده و اون دادهها میتونن قدیمی یا نادرست باشن.
- هیچ منبع دانشی نداره.
- نمیتونه اینترنت رو جستجو کنه.
- هیچ چیزی رو «نمیدونه».
فقط حدس میزنه که کلمه بعدی چیه.
بیاین چندتا مثال ببینیم:
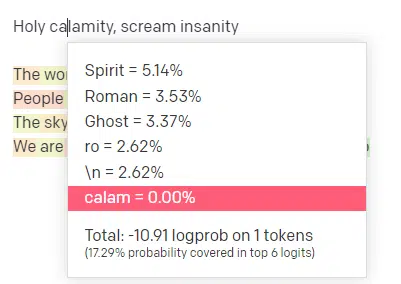
من توی OpenAI Playground، خط اول ترک کلاسیک «Holy calamity» از گروه «Handsome Boy Modeling School» رو وارد کردم.
من پاسخ رو ثبت کردم تا بتونیم احتمال هم ورودی من و هم خطوط خروجی رو ببینیم. پس بیاین هر بخش از چیزی که این به ما میگه رو بررسی کنیم.
برای اولین کلمه/توکن، من «Holy» رو وارد کردم. میتونیم ببینیم که محتملترین ورودیهای بعدی Spirit، Roman و Ghost هستن.
همچنین میتونیم ببینیم که شش نتیجه برتر فقط ۱۷.۲۹٪ از احتمالات کلمه بعدی رو پوشش میدن: این یعنی حدود ۸۲٪ احتمالات دیگهای وجود داره که ما توی این تصویر نمیبینیم.
بیاین به طور خلاصه در مورد ورودیهای مختلفی که میتونین اینجا استفاده کنین و تأثیرشون روی خروجی صحبت کنیم.
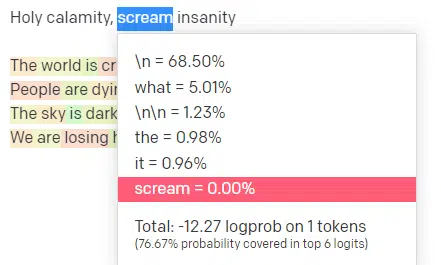
Temperature (دما) نشون میده که مدل چقدر احتمال داره کلماتی غیر از کلمات با بالاترین احتمال رو انتخاب کنه، و top P نشون میده که چطور اون کلمات رو انتخاب میکنه.
پس برای ورودی «Holy Calamity»، top P نحوه انتخاب خوشه توکنهای بعدی [Ghost, Roman, Spirit] رو مشخص میکنه و Temperature نشون میده که چقدر احتمال داره به سراغ محتملترین توکن بره در مقابل تنوع بیشتر.
اگه Temperature بالاتر باشه، احتمال بیشتری داره که یک توکن کماحتمالتر رو انتخاب کنه.
بنابراین، Temperature بالا و top P بالا احتمالاً نتایج عجیبتری تولید میکنن. چون از بین تنوع زیادی انتخاب میکنه (top P بالا) و احتمال بیشتری داره که توکنهای غافلگیرکننده رو انتخاب کنه.


در حالی که دمای بالا اما top P پایینتر، گزینههای غافلگیرکننده رو از نمونه کوچکتری از احتمالات انتخاب میکنه:
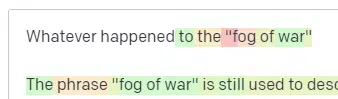

و پایین آوردن دما فقط محتملترین توکنهای بعدی رو انتخاب میکنه:

به نظر من، بازی کردن با این احتمالات میتونه دید خوبی از نحوه کار این نوع مدلها بهتون بده.
این مدل به مجموعهای از انتخابهای محتمل بعدی بر اساس چیزی که قبلاً تکمیل شده نگاه میکنه.
تهش یعنی چی؟
به زبان ساده، مدلهای زبان بزرگ مجموعهای از ورودیها رو میگیرن، اونها رو با هم قاطی میکنن و به خروجی تبدیل میکنن.
شنیدم بعضیها شوخی میکنن که این کار چقدر با کاری که آدما میکنن فرق داره.
اما این مثل آدما نیست؛ مدلهای زبان بزرگ هیچ پایگاه دانشی ندارن. اونها اطلاعاتی در مورد یک چیز استخراج نمیکنن. فقط دارن دنبالهای از کلمات رو بر اساس کلمه قبلی حدس میزنن.
یه مثال دیگه: به یه سیب فکر کنین. چی به ذهنتون میاد؟
شاید بتونین یه سیب رو توی ذهنتون بچرخونین.
شاید بوی یه باغ سیب، شیرینی یه سیب صورتی و غیره یادتون بیاد.
شاید هم به استیو جابز فکر کنین.
حالا ببینیم پرامپت «به یه سیب فکر کن» چه جوابی برمیگردونه.
شاید تا الان اصطلاح «طوطیهای تصادفی» (Stochastic Parrots) به گوشتون خورده باشه.
«طوطیهای تصادفی» اصطلاحیه که برای توصیف مدلهای زبان بزرگ مثل GPT استفاده میشه. طوطی پرندهایه که چیزی که میشنوه رو تقلید میکنه.
پس، LLMها مثل طوطی هستن چون اطلاعات (کلمات) رو میگیرن و چیزی شبیه به چیزی که شنیدن رو خروجی میدن. اما اونها تصادفی (stochastic) هم هستن، یعنی از احتمالات برای حدس زدن کلمه بعدی استفاده میکنن.
LLMها در تشخیص الگوها و روابط بین کلمات خوب عمل میکنن، اما هیچ درک عمیقتری از چیزی که میبینن ندارن. به همین دلیله که در تولید متن زبان طبیعی اینقدر خوبن اما در درک اون نه.
کاربردهای خوب برای یک LLM
LLMها در کارهای عمومیتر خوب عمل میکنن.
میتونی بهش یه متن نشون بدی و بدون آموزش، یه کاری رو با اون متن انجام بده.
میتونی یه متن بهش بدی و ازش تحلیل احساسات (sentiment analysis) بخوای، ازش بخوای اون متن رو به نشانهگذاری ساختاریافته (structured markup) تبدیل کنه و کارهای خلاقانه انجام بده (مثلاً نوشتن طرح کلی یا outline).
توی کارهایی مثل کدنویسی هم بد نیست. برای خیلی از کارها، میتونه تقریباً شما رو به مقصد برسونه.
اما باز هم، همه چیز بر اساس احتمالات و الگوهاست. پس مواقعی پیش میاد که الگوهایی رو توی ورودی شما پیدا میکنه که خودتون از وجودشون خبر ندارین.
این میتونه مثبت باشه (دیدن الگوهایی که انسانها نمیتونن ببینن)، اما میتونه منفی هم باشه (چرا اینجوری جواب داد؟).
همچنین به هیچ منبع دادهای دسترسی نداره. سئوکارهایی که ازش برای پیدا کردن کلمات کلیدی رتبهبندی شده استفاده میکنن، روزگار خوشی نخواهند داشت.
نمیتونه ترافیک یک کلمه کلیدی رو پیدا کنه. هیچ اطلاعاتی در مورد دادههای کلمات کلیدی، فراتر از اینکه این کلمات وجود دارن، نداره.

نکته هیجانانگیز در مورد ChatGPT اینه که یک مدل زبانی به راحتی در دسترسه که میتونی ازش برای کارهای مختلف استفاده کنی. اما بدون اما و اگر هم نیست.
کاربردهای خوب برای سایر مدلهای یادگیری ماشین
میشنوم که بعضیها میگن برای کارهای خاصی از LLMها استفاده میکنن، در حالی که الگوریتمها و تکنیکهای NLP دیگه میتونن اون کارها رو بهتر انجام بدن.
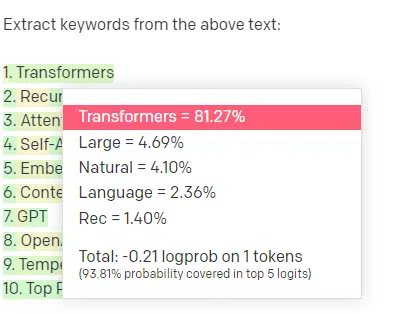
بیاین یه مثال بزنیم، استخراج کلمات کلیدی (keyword extraction).
اگه من از TF-IDF یا یه تکنیک کلیدواژه دیگه برای استخراج کلمات کلیدی از یک مجموعه متن (corpus) استفاده کنم، میدونم چه محاسباتی پشت اون تکنیک وجود داره.
این یعنی نتایج استاندارد، قابل تکرار و مرتبط با همون مجموعه متن خواهند بود.
با LLMهایی مثل ChatGPT، اگه ازش بخوای کلمات کلیدی رو استخراج کنه، لزوماً کلمات کلیدی استخراجشده از اون مجموعه متن رو دریافت نمیکنی. بلکه چیزی رو میگیری که GPT فکر میکنه پاسخی به «مجموعه متن + استخراج کلمات کلیدی» میتونه باشه.
این موضوع در مورد کارهایی مثل خوشهبندی (clustering) یا تحلیل احساسات هم صدق میکنه. شما لزوماً نتیجه دقیق با پارامترهایی که تعیین کردین رو نمیگیرین. بلکه چیزی رو میگیرین که بر اساس کارهای مشابه دیگه، احتمالش وجود داره.
باز هم تکرار میکنم، LLMها هیچ پایگاه دانش و اطلاعات بهروزی ندارن. اونها اغلب نمیتونن وب رو جستجو کنن و چیزی که از اطلاعات میگیرن رو به صورت توکنهای آماری پردازش میکنن. محدودیتهای مربوط به مدت زمان حافظه یک LLM به خاطر همین عوامله.
نکته دیگه اینه که این مدلها نمیتونن فکر کنن. من فقط چند بار در این مطلب از کلمه «فکر کردن» استفاده کردم چون واقعاً سخته که موقع صحبت در مورد این فرآیندها ازش استفاده نکنی.
حتی وقتی در مورد آمار و ارقام فانتزی صحبت میکنیم، تمایل به انسانانگاری (anthropomorphism) وجود داره.
اما این یعنی اگه شما یک LLM رو برای کاری که نیاز به «فکر کردن» داره مسئول کنین، به یک موجود متفکر اعتماد نکردین.
شما به یک تحلیل آماری از پاسخهای صدها آدم عجیب و غریب اینترنتی به توکنهای مشابه اعتماد کردین.
اگه برای انجام کاری به ساکنان اینترنت اعتماد میکنین، پس میتونین از یک LLM هم استفاده کنین. در غیر این صورت…
کارهایی که هرگز نباید به مدلهای یادگیری ماشین سپرد
گزارش شده که یک چتبات که با یک مدل GPT (GPT-J) کار میکرده، مردی رو به خودکشی تشویق کرده. ترکیبی از عوامل میتونه باعث آسیب واقعی بشه، از جمله:
- انسانانگاری این پاسخها توسط مردم.
- باور به اینکه این مدلها خطاناپذیرن.
- استفاده از اونها در جاهایی که نیاز به حضور انسان در سیستم هست.
- و موارد دیگه.
شاید فکر کنین، «من یه سئوکارم. من توی سیستمهایی که میتونن کسی رو بکشن دستی ندارم!»
به صفحات YMYL (پول یا زندگی شما) و اینکه چطور گوگل مفاهیمی مثل E-E-A-T رو ترویج میده فکر کنین.
آیا گوگل این کار رو میکنه چون میخواد سئوکارها رو اذیت کنه، یا چون نمیخواد مسئولیت اون آسیب رو به عهده بگیره؟
حتی در سیستمهایی با پایگاههای دانش قوی هم میتونه آسیب به وجود بیاد.
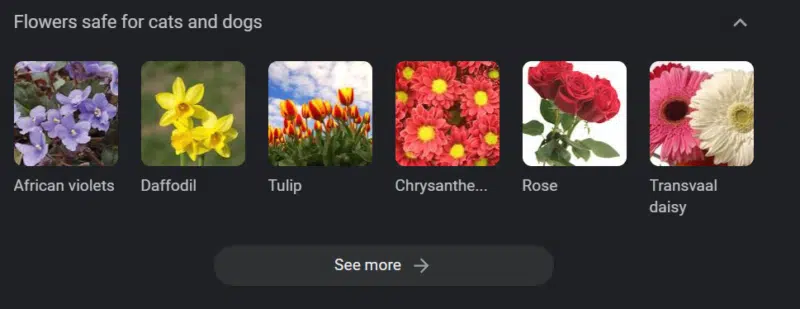
تصویر بالا یک کاروسل دانش گوگله برای «گلهای بیخطر برای سگ و گربه». گل نرگس (Daffodil) در این لیست قرار داره، در حالی که برای گربهها سمی است.
فرض کنین شما در حال تولید محتوا برای یک وبسایت دامپزشکی در مقیاس بزرگ با استفاده از GPT هستین. یه عالمه کلمه کلیدی وارد میکنین و به API ChatGPT وصل میشین.
یه فریلنسر تمام نتایج رو میخونه و متخصص اون حوزه نیست. اون متوجه مشکل نمیشه.
شما نتیجه رو منتشر میکنین که صاحبان گربه رو به خرید گل نرگس تشویق میکنه.
شما گربه کسی رو میکشین.
نه به طور مستقیم. شاید حتی اونها ندونن که به خاطر اون سایت خاص بوده.
شاید سایتهای دامپزشکی دیگه هم شروع به همین کار کنن و از همدیگه تغذیه کنن.
نتیجه برتر جستجوی گوگل برای «آیا گل نرگس برای گربهها سمی است» سایتیه که میگه سمی نیست.
فریلنسرهای دیگه که محتواهای هوش مصنوعی دیگه رو میخونن – صفحهها پشت صفحه محتوای هوش مصنوعی – واقعاً بررسی واقعیت (fact check) میکنن. اما حالا سیستمها اطلاعات نادرست دارن.
وقتی در مورد این موج فعلی هوش مصنوعی صحبت میکنم، خیلی به Therac-25 اشاره میکنم. این یک مطالعه موردی معروف از تخلف کامپیوتریه.
اساساً، این یک دستگاه پرتودرمانی بود، اولین دستگاهی که فقط از مکانیزمهای قفل کامپیوتری استفاده میکرد. یک اشکال در نرمافزار باعث شد که مردم دهها هزار برابر دوز تابشی که باید دریافت کنن، دریافت کنن.
چیزی که همیشه برای من برجسته است اینه که شرکت داوطلبانه این مدلها رو بازخوانی و بازرسی کرد.
اما اونها فرض کردن که چون فناوری پیشرفته بود و نرمافزار «خطاناپذیر» بود، مشکل باید به قطعات مکانیکی دستگاه مربوط باشه.
بنابراین، اونها مکانیزمها رو تعمیر کردن اما نرمافزار رو بررسی نکردن – و Therac-25 در بازار باقی موند.
سوالات متداول و باورهای غلط
چرا ChatGPT به من دروغ میگه؟
یکی از چیزهایی که از بعضی از بزرگترین ذهنهای نسل ما و همچنین اینفلوئنسرهای توییتر دیدم، شکایت از اینه که ChatGPT بهشون «دروغ» میگه. این به خاطر چندتا باور غلط همزمانه:
- اینکه ChatGPT «خواسته» داره.
- اینکه پایگاه دانش داره.
- اینکه فناوران پشت این فناوری، هدفی غیر از «پول درآوردن» یا «ساختن یه چیز باحال» دارن.
سوگیریها در هر بخش از زندگی روزمره شما وجود دارن. استثنائات این سوگیریها هم همینطور.
بیشتر توسعهدهندگان نرمافزار در حال حاضر مرد هستن: من یک توسعهدهنده نرمافزار و یک زن هستم.
آموزش یک هوش مصنوعی بر اساس این واقعیت، باعث میشه که همیشه فرض کنه توسعهدهندگان نرمافزار مرد هستن، که درست نیست.
یک مثال معروف، هوش مصنوعی استخدام آمازونه که با رزومههای کارمندان موفق آمازون آموزش دیده بود.
این باعث شد که رزومههای کالجهایی با اکثریت سیاهپوست رو رد کنه، حتی با اینکه خیلی از اون کارمندان میتونستن بسیار موفق باشن.
برای مقابله با این سوگیریها، ابزارهایی مثل ChatGPT از لایههای تنظیم دقیق (fine-tuning) استفاده میکنن. به همین دلیله که پاسخ «به عنوان یک مدل زبان هوش مصنوعی، من نمیتوانم…» رو میگیرین.
بعضی از کارگران در کنیا مجبور بودن صدها پرامپت رو بررسی کنن و به دنبال توهین، سخنان نفرتانگیز و پاسخها و پرامپتهای افتضاح بگردن.
بعد یک لایه تنظیم دقیق ایجاد شد.
چرا نمیتونی در مورد جو بایدن توهین بسازی؟ چرا میتونی در مورد مردان جوکهای جنسیتی بگی اما در مورد زنان نه؟
این به خاطر سوگیری لیبرال نیست، بلکه به خاطر هزاران لایه تنظیم دقیقیه که به ChatGPT میگه فلان حرف رو نزنه.
در حالت ایدهآل، ChatGPT باید در مورد جهان کاملاً بیطرف باشه، اما اونها همچنین نیاز دارن که جهان رو منعکس کنه.
این مشکلی شبیه به مشکلیه که گوگل داره.
چیزی که درسته، چیزی که مردم رو خوشحال میکنه و چیزی که پاسخ درستی به یک پرامپت هست، اغلب چیزهای بسیار متفاوتی هستن.
چرا ChatGPT منابع جعلی میسازه؟
سوال دیگهای که زیاد میبینم در مورد منابع جعلیه. چرا بعضیهاشون جعلی و بعضی واقعی هستن؟ چرا بعضی وبسایتها واقعی هستن، اما صفحات جعلی؟
امیدوارم با خوندن نحوه کار مدلهای آماری، بتونین این موضوع رو درک کنین. اما اینجا یه توضیح کوتاه میدم:
شما یک مدل زبان هوش مصنوعی هستین. با حجم زیادی از وب آموزش دیدین.
کسی به شما میگه در مورد یه موضوع فنی بنویسین – مثلاً Cumulative Layout Shift (CLS).
شما نمونههای زیادی از مقالات CLS ندارین، اما میدونین چیه و شکل کلی یک مقاله در مورد فناوریها رو میشناسین. الگوی ظاهری این نوع مقالات رو بلدین.

پس با پاسخ خودتون شروع میکنین و به یه مشکلی برمیخورین. به روشی که شما نوشتار فنی رو درک میکنین، میدونین که در ادامه جمله باید یک URL بیاد.
خب، از مقالات دیگه CLS، میدونین که گوگل و GTMetrix اغلب در مورد CLS به عنوان منبع ذکر میشن، پس اینها آسونن.
اما شما همچنین میدونین که CSS-tricks اغلب در مقالات وب لینک داده میشه: میدونین که معمولاً URLهای CSS-tricks شکل خاصی دارن: پس میتونین یک URL CSS-tricks رو اینطوری بسازین:
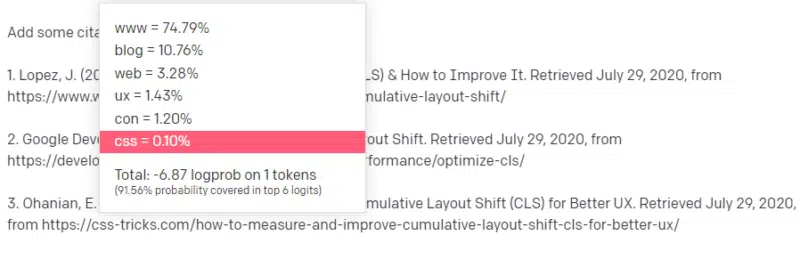
نکته اینجاست: همه URLها اینطوری ساخته میشن، نه فقط جعلیها:
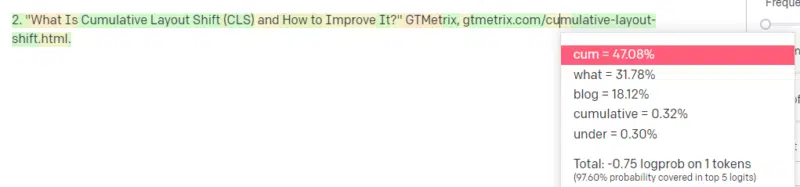
این مقاله GTMetrix وجود داره: اما وجود داره چون یک رشته محتمل از مقادیر بوده که در انتهای این جمله بیاد.
GPT و مدلهای مشابه نمیتونن بین یک منبع واقعی و یک منبع جعلی تمایز قائل بشن.
تنها راه برای این مدلسازی، استفاده از منابع دیگه (پایگاههای دانش، پایتون و غیره) برای تجزیه و تحلیل این تفاوت و بررسی نتایجه.
«طوطی تصادفی» چیه؟
میدونم که قبلاً در مورد این صحبت کردم، اما ارزش تکرار داره. طوطیهای تصادفی روشی برای توصیف چیزیه که وقتی مدلهای زبان بزرگ به نظر عمومی میان اتفاق میفته.
برای LLM، مزخرفات و واقعیت یکی هستن. اونها جهان رو مثل یک اقتصاددان میبینن، به عنوان یک مشت آمار و ارقام که واقعیت رو توصیف میکنن.
این نقل قول رو میشناسین: «سه نوع دروغ وجود داره: دروغ، دروغ لعنتی و آمار.»
LLMها یک مشت بزرگ آمار هستن.
LLMها منسجم به نظر میرسن، اما این به این دلیله که ما اساساً چیزهایی رو که شبیه انسان به نظر میرسن، انسان میبینیم.
به همین ترتیب، مدل چتبات، بخش زیادی از پرامپتها و اطلاعاتی که برای منسجم بودن کامل پاسخهای GPT نیاز دارین رو پنهان میکنه.
من یک توسعهدهنده هستم: تلاش برای استفاده از LLMها برای دیباگ کردن کدم نتایج بسیار متغیری داشته. اگه مشکلی شبیه به مشکلی باشه که مردم اغلب آنلاین باهاش مواجه شدن، LLMها میتونن اون نتیجه رو پیدا و اصلاح کنن.
اگه مشکلی باشه که قبلاً باهاش مواجه نشده، یا بخش کوچکی از مجموعه دادهها باشه، هیچی رو درست نمیکنه.
چرا GPT از یک موتور جستجو بهتره؟
من این سوال رو به شکل تندی مطرح کردم. من فکر نمیکنم GPT از یک موتور جستجو بهتر باشه. نگرانم که مردم جستجو رو با ChatGPT جایگزین کردن.
یکی از بخشهای کمتر شناخته شده ChatGPT اینه که چقدر برای پیروی از دستورالعملها وجود داره. میتونی ازش بخوای تقریباً هر کاری رو انجام بده.
اما یادتون باشه، همه چیز بر اساس کلمه آماری بعدی در یک جمله است، نه حقیقت.
پس اگه ازش سوالی بپرسین که جواب خوبی نداره اما به شکلی بپرسین که مجبور به جواب دادن باشه، جواب ضعیفی میگیرین.
داشتن پاسخی که برای شما و حول شما طراحی شده آرامشبخشتره، اما جهان تودهای از تجربیاته.
همه ورودیها به یک LLM به یک شکل رفتار میشن: اما بعضی از مردم تجربه دارن و پاسخ اونها بهتر از ترکیبی از پاسخهای دیگران خواهد بود.
یک متخصص ارزشش بیشتر از هزاران مقاله نظریه.
آیا این طلوع هوش مصنوعیه؟ آیا اسکاینت اینجاست؟
کوکو گوریل، میمونی بود که بهش زبان اشاره یاد داده بودن. محققان در مطالعات زبانشناسی تحقیقات زیادی انجام دادن که نشون میداد میمونها میتونن زبان یاد بگیرن.
بعد هربرت تراس کشف کرد که میمونها جملات یا کلمات رو کنار هم نمیذاشتن، بلکه فقط از مربیان انسانیشون تقلید میکردن.
الایزا یک درمانگر ماشینی، یکی از اولین چتباتها بود.
مردم اون رو به عنوان یک شخص میدیدن: یک درمانگر که بهش اعتماد و اهمیت میدادن. اونها از محققان میخواستن که باهاش تنها باشن.
زبان کار خاصی با مغز مردم میکنه. مردم میشنون چیزی ارتباط برقرار میکنه و انتظار دارن فکری پشتش باشه.
LLMها چشمگیرن اما به شکلی که گستره دستاوردهای انسانی رو نشون میده.
LLMها اراده ندارن. نمیتونن فرار کنن. نمیتونن سعی کنن جهان رو تسخیر کنن.
اونها یک آینه هستن: بازتابی از مردم و به طور خاص کاربر.
تنها فکر موجود، یک نمایش آماری از ناخودآگاه جمعیه.
آیا GPT یک زبان کامل رو به تنهایی یاد گرفت؟
ساندار پیچای، مدیرعامل گوگل، در برنامه «60 دقیقه» ادعا کرد که مدل زبان گوگل زبان بنگالی رو یاد گرفته.
این مدل با اون متون آموزش دیده بود. این نادرسته که «به زبان خارجیای صحبت کرد که هرگز برای شناختنش آموزش ندیده بود.»
مواقعی هست که هوش مصنوعی کارهای غیرمنتظرهای انجام میده، اما این خودش قابل انتظاره.
وقتی به الگوها و آمار در مقیاس بزرگ نگاه میکنین، لزوماً مواقعی پیش میاد که اون الگوها چیزی غافلگیرکننده رو آشکار میکنن.
چیزی که این واقعاً نشون میده اینه که بسیاری از مدیران ارشد و بازاریابهایی که هوش مصنوعی و یادگیری ماشین رو تبلیغ میکنن، در واقع نمیفهمن که این سیستمها چطور کار میکنن.
شنیدم بعضی از افراد بسیار باهوش در مورد ویژگیهای نوظهور، هوش عمومی مصنوعی (AGI) و سایر چیزهای آیندهنگرانه صحبت میکنن.
من شاید فقط یک مهندس ساده عملیات یادگیری ماشین باشم، اما این نشون میده که چقدر هایپ، وعدهها، داستانهای علمی-تخیلی و واقعیت هنگام صحبت در مورد این سیستمها با هم قاطی میشن.
الیزابت هولمز، بنیانگذار بدنام ترانوس، به خاطر دادن وعدههایی که نمیتونست بهشون عمل کنه، به صلیب کشیده شد.
اما چرخه دادن وعدههای غیرممکن بخشی از فرهنگ استارتاپی و پول درآوردنه. تفاوت بین ترانوس و هایپ هوش مصنوعی اینه که ترانوس نمیتونست برای مدت طولانی تظاهر کنه.
آیا GPT یک جعبه سیاهه؟ چه اتفاقی برای دادههای من در GPT میفته؟
GPT به عنوان یک مدل، یک جعبه سیاه نیست. میتونین کد منبع GPT-J و GPT-Neo رو ببینین.
اما GPT شرکت OpenAI یک جعبه سیاهه. OpenAI مدل خودش رو منتشر نکرده و احتمالاً سعی خواهد کرد منتشر نکنه، همونطور که گوگل الگوریتم خودش رو منتشر نمیکنه.
اما این به این دلیل نیست که الگوریتم بیش از حد خطرناکه. اگه اینطور بود، اونها اشتراک API رو به هر آدم سادهای با یک کامپیوتر نمیفروختن. این به خاطر ارزش اون کدبیس انحصاریه.
وقتی از ابزارهای OpenAI استفاده میکنین، شما در حال آموزش و تغذیه API اونها با ورودیهای خودتون هستین. این یعنی هر چیزی که وارد OpenAI میکنین، اون رو تغذیه میکنه.
این یعنی افرادی که از مدل GPT OpenAI برای کمک به نوشتن یادداشتها و کارهای دیگه برای دادههای بیماران استفاده کردن، قوانین حریم خصوصی (مثل HIPAA) رو نقض کردن. اون اطلاعات الان در مدله و استخراجش بسیار دشوار خواهد بود.
چون خیلی از مردم در درک این موضوع مشکل دارن، خیلی محتمله که این مدل حاوی حجم زیادی از دادههای خصوصی باشه که فقط منتظر پرامپت مناسب برای انتشارشون هستن.
چرا GPT با سخنان نفرتانگیز آموزش دیده؟
موضوع دیگهای که اغلب مطرح میشه اینه که مجموعه متنی که GPT باهاش آموزش دیده شامل سخنان نفرتانگیزه.
تا حدی، OpenAI نیاز داره مدلهای خودش رو برای پاسخ به سخنان نفرتانگیز آموزش بده، پس نیاز داره مجموعهای داشته باشه که شامل برخی از اون اصطلاحات باشه.
OpenAI ادعا کرده که این نوع سخنان نفرتانگیز رو از سیستم پاک کرده، اما اسناد منبع شامل 4chan و کلی سایتهای نفرتپراکنی هستن.
هیچ راه آسانی برای جلوگیری از این وجود نداره. چطور میتونی چیزی داشته باشی که نفرت، سوگیریها و خشونت رو تشخیص بده یا درک کنه بدون اینکه به عنوان بخشی از مجموعه آموزشیات باشه؟
چطور از سوگیریها اجتناب میکنی و سوگیریهای ضمنی و صریح رو درک میکنی وقتی یک عامل ماشینی هستی که به طور آماری توکن بعدی در یک جمله رو انتخاب میکنه؟
خلاصه کلام
هایپ و اطلاعات غلط در حال حاضر عناصر اصلی رونق هوش مصنوعی هستن. این به این معنی نیست که کاربردهای قانونی وجود نداره: این فناوری شگفتانگیز و مفیده.
اما نحوه بازاریابی این فناوری و نحوه استفاده مردم از اون میتونه باعث ترویج اطلاعات غلط، سرقت ادبی و حتی آسیب مستقیم بشه.
وقتی پای جون کسی در میونه از LLMها استفاده نکنین. وقتی الگوریتم دیگهای بهتر عمل میکنه از LLMها استفاده نکنین. گول هایپ رو نخورین.
درک اینکه LLMها چی هستن – و چی نیستن – ضروریه
توصیه میکنم این مصاحبه آدام کانوور با امیلی بندر و تیمنیت گبرو رو ببینین.
LLMها اگه به درستی استفاده بشن، میتونن ابزارهای فوقالعادهای باشن. راههای زیادی برای استفاده از LLMها و راههای بیشتری برای سوءاستفاده از اونها وجود داره.
ChatGPT دوست شما نیست. یه مشت آماره. هوش عمومی مصنوعی (AGI) «هنوز نیومده».
پاسخی بگذارید